XPath详解
XPath 是一门在 XML 文档中查找信息的语言。
XPath 是 XSLT 中的主要元素。
XQuery 和 XPointer 均构建于 XPath 表达式之上
常常用于selenum自动化测试中元素定位中,了解学习XPath有利于快速定位某些节点元素。XPath使用路径表达式来选取XML文档中的节点或者节点集,这些路径表达式和平时在常规电脑上的表达式操作非常类似。
1、XPath节点
XPath节点是XPath中的专业术语,是某些“特性或者属性”的总称,包括7种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点。而XML文档是被作为节点树来对待的,树的根被称为根节点或者文档节点。
Harry Potter
J K. Rowling
2005
29.99
节点解析:
(文档节点)
J K. Rowling (元素节点)
lang="en" (属性节点) a、基本值(原子值,Atomic value)
基本值是无父节点或者没有孩子的节点,如:
J K. Rowling
"en"节点之间的关系有:父(parent)、子(children)、同胞(sibling)、先辈(ancestor,该节点的父,父的父等)、后代(decentant,该节点的子,子的子)
Harry Potter
J K. Rowling
2005
29.99
book元素是title、autor、year、price的父;title、autor、year、price互为同胞;title的先辈是book 和bookstore元素
2、XPath语法
XPath使用路径表达式来选取XML文档中的节点或者节点集,节点是通过沿着路径(path)或者步(steps)来选取的
Harry Potter
29.99
Learning XML
39.95
a、选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
结合上述实例
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
b、谓语(predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
c、选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
d、选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
3、轴(Axes)
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| following-sibling | 选取当前节点之后的所有兄弟节点 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
4、实例介绍
这里给出一个books.xml
Everyday Italian
Giada De Laurentiis
2005
30.00
Harry Potter
J K. Rowling
2005
29.99
XQuery Kick Start
James McGovern
Per Bothner
Kurt Cagle
James Linn
Vaidyanathan Nagarajan
2003
49.99
Learning XML
Erik T. Ray
2003
39.95
a、加载XML文档
所有现代浏览器都支持使用 XMLHttpRequest 来加载 XML 文档的方法。针对大多数现代浏览器的代码:
var xmlhttp=new XMLHttpRequest()b、选取节点
Internet Explorer 和其他处理 XPath 的方式不同。在我们的例子中,包含适用于大多数主流浏览器的代码。Internet Explorer 使用 selectNodes() 方法从 XML 文档中的选取节点:
xmlDoc.selectNodes(xpath);Firefox、Chrome、Opera 以及 Safari 使用 evaluate() 方法从 XML 文档中选取节点:
xmlDoc.evaluate(xpath, xmlDoc, null, XPathResult.ANY_TYPE,null);c、选取所有title
/bookstore/book/title选取所有title
d、选取第一个book的title
选取 bookstore 元素下面的第一个 book 节点的 title:
/bookstore/book[1]/title选取第一个book的title
IE5 以及更高版本将 [0] 视为第一个节点
e、选取所有价格
/bookstore/book/price/text()选取所有价格
f、选取价格高于35的price节点
/bookstore/book[price>35]/price/bookstore/book[price>35]/title 选取价格高于35的title节点选取价格高于35的title节点
基于上面的理论知识,结合实践进行熟悉。打开Firefox浏览器的firebug如下轻松定位到搜索元素
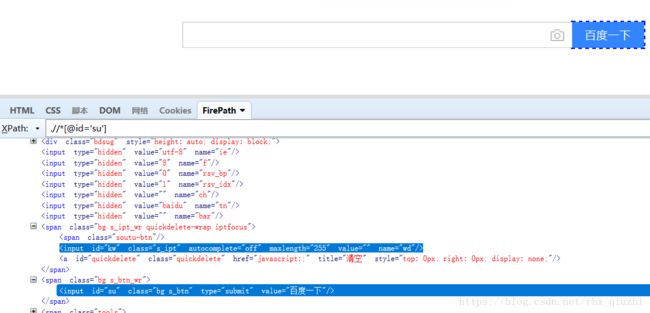
- xpath通过id、name、class进行元素定位
#coding:utf-8
from selenium import webdriver
import time
#打开火狐浏览器
driver = webdriver.Firefox()
driver.maximize_window()
#打开百度
driver.get("https://www.baidu.com/")
#页面加载需要几秒钟的时间
time.sleep(2)
#通过id定位搜索框,并输出Python
driver.find_element_by_xpath(".//*[@id='kw']").send_keys("python")
#通过name定位搜索框,并输出selenium
#driver.find_element_by_xpath(".//*[@name='wd']").send_keys("selenium")
#通过class定位搜索框,并输出firefox
#driver.find_element_by_xpath(".//*[@class='s_ipt']").send_keys("firefox")
driver.find_element_by_xpath(".//*[@id='su']").click()
time.sleep(3)
driver.quit()2. Xpath标签
有时候同一个属性,同名的较多,可以通过标签进行筛选,如果不想指定标签名称,可以使用*表示任意标签,如果想指定标签,直接写出标签名称即可。
#coding:utf-8
from selenium import webdriver
import time
#打开火狐浏览器
driver = webdriver.Firefox()
driver.maximize_window()
#打开百度
driver.get("https://www.baidu.com/")
#页面加载需要几秒钟的时间
time.sleep(2)
#通过id定位搜索框,并输出Python
driver.find_element_by_xpath("//input[@autocomplete='off']").send_keys("python")
#driver.find_element_by_xpath("//input[@id='kw']").send_keys("python")
#driver.find_element_by_xpath("//input[@name='wd']").send_keys("python")
driver.find_element_by_xpath(".//*[@id='su']").click()
time.sleep(3)
driver.quit()3. xpath层级进行元素定位
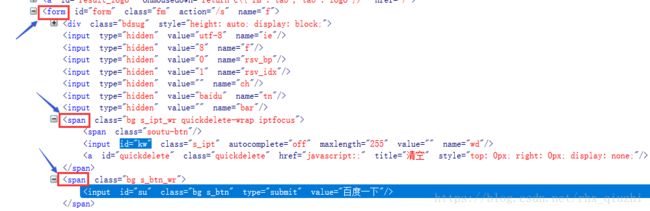
从上图不难发现,input的父节点是span,其祖先节点是form,因此可以这样定位
driver.find_element_by_xpath("//span[@class='bg s_ipt_wr quickdelete-wrap iptfocus']/input").send_keys("python")
driver.find_element_by_xpath("//form[@id='form']/span[0]/input").send_keys("python")同时,对于上述图中,发现id="kw"和id="su"所在的标签均为span,且为兄弟,这时无法通过层级进行定位,需要利用索引,如上述的span[0],参考xpath定位
4. 逻辑运算
xpath可以进行多个属性的逻辑运算,包括与and ,或 or,非not
driver.find_element_by_xpath("//*[@id='kw' and @autocomplete='off']").send_keys("firefox")
driver.find_element_by_id("su").click()