kylin集群Nginx负载均衡
Nginx负载均衡
1, Nginx负载均衡简介
跨多个应用程序实例的负载平衡是优化资源利用率,最大化吞吐量,减少延迟以及确保容错配置的常用技术。
可以使用nginx作为非常高效的HTTP负载均衡器,将流量分配给多个应用程序服务器,并通过nginx提高Web应用程序的性能,可伸缩性和可靠性。
2, Nginx负载均衡机制
nginx支持以下负载均衡机制(或方法):
循环 - 对应用程序服务器的请求以循环方式分发,
最少连接 - 下一个请求被分配给活动连接数最少的服务器,
ip-hash - 哈希函数用于确定下一个请求(基于客户端的IP地址)应该选择哪个服务器。
3, Nginx默认负载均衡配置
使用nginx进行负载平衡的最简单配置可能如下所示:
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}
在上面的示例中,在srv1-srv3上运行相同的应用程序有3个实例。当没有专门配置负载均衡的方法时,默认为round-robin。所有的请求 代理服务器组myapp1,nginx应用HTTP负载均衡分配请求。
nginx中的反向代理实现包括HTTP,HTTPS,FastCGI,uwsgi,SCGI和memcached的负载均衡。
要为HTTPS而不是HTTP配置负载均衡,只需使用“https”作为协议。
在为FastCGI,uwsgi,SCGI或memcached设置负载均衡时,分别使用 fastcgi_pass, uwsgi_pass, scgi_pass和 memcached_pass 指令。
4, 最少的连接负载均衡
另一个负载均衡规则是最少连接的。在某些请求花费较长时间完成的情况下,“最少连接负载均衡”可以更公平地控制应用程序实例的负载。
在连接负载最小的情况下,nginx会尽量避免给过于繁忙的应用程序服务器以过多的请求,而是将新请求分配给不太繁忙的服务器。
在使用 least_conn指令作为服务器组配置的一部分时,将激活nginx中最不连接的负载平衡 :
upstream myapp1 {
least_conn;
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
5, 会话持久性
请注意,通过循环或最不连接的负载平衡,每个后续客户端的请求都可能被分发到不同的服务器。不能保证相同的客户端将总是定向到相同的服务器。
如果需要将客户端绑定到特定的应用程序服务器 - 换句话说,就总是试图选择特定的服务器而言,使客户端的会话“粘性”或“持久性” - ip-hash负载均衡机制可以用的。
使用ip-hash,将客户端的IP地址用作散列键,以确定应该为客户端的请求选择服务器组中的哪个服务器。此方法可确保来自同一客户端的请求将始终定向到同一服务器,除非此服务器不可用。
要配置ip-hash负载平衡,只需将ip_hash 指令添加 到服务器(上游)组配置:
upstream myapp1 {
ip_hash;
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
6, 加权负载平衡
通过使用服务器权重,还可以进一步影响nginx负载均衡算法。
在上面的示例中,未配置服务器权重,这意味着所有指定的服务器都被视为同样适用于特定的负载平衡方法。
特别是循环,它也意味着服务器之间的请求差不多均等分配 - 只要有足够的请求,并且请求以统一的方式处理并且完成得足够快。
当 为服务器指定权重参数时, 权重作为负载均衡决策的一部分。
upstream myapp1 {
server srv1.example.com weight=3;
server srv2.example.com;
server srv3.example.com;
}
使用这种配置,每5个新的请求将被分配到应用程序实例中,如下所示:3个请求将被引导到srv1,一个请求将到达srv2,另一个请求将被引导到srv3。
同样可以在最近的nginx版本中使用最小连接和ip-hash负载均衡的权重。
7, 健康检查
nginx中的反向代理实现包括in-band(或被动)服务器运行状况检查。如果来自特定服务器的出现错误导致响应失败,nginx会将此服务器标记为失败,并尝试避免选择此服务器以用于随后的入站请求。
该 max_fails 指令设置在fail_timeout超时时间内连续不成功的尝试与服务器进行通信的数量。默认情况下, max_fails 设置为1.当设置为0时,此服务器的运行状况检查被禁用。该 fail_timeout 参数还定义服务器被标记为失败多久。在 服务器故障之后的 fail_timeout时间间隔之后,nginx将开始正常地使用实时客户端的请求来探测服务器。如果探测器成功,服务器将被标记为活动的。
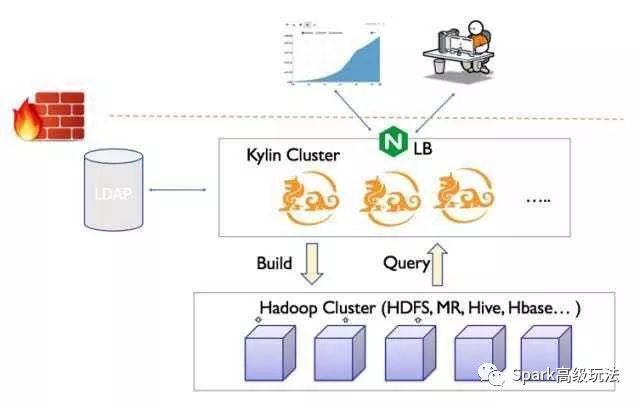
Kylin集群模型介绍
Apache Kylin是一个无状态的服务,所有的状态信息都保存在HBase中。因此,只要把多个Kylin实例部署在同一个HBase集群上,就可以对这些 Kylin实例进行负载均衡。因此,部署的多个Kylin实例需要满足以下条件:
共享同一个Hadoop集群和HBase集群;
无端口冲突,最好能分别部署在不同服务器上,以做到互不影响;
共享同一个元数据库,即kylin.properties中kylin.metadata.url值相同;
只有一个Kylin实例运行任务引擎(即kylin.server.mode=all),其它 Kylin实例都作为查询引擎(即kylin.server.mode=query)
为了将外部的查询请求转发给Apache Kylin集群中的单个节点,需要部署一个负载均衡器(Load Balancer),如Nginx等。负载均衡器通过一定策略对请求进行分发,并在节点失效时重试其他节点。Kylin用户直接可以通过负载均衡器的地址进行访问。
以Nginx为例,需要为Apache Kylin站点新建一个配置文件(如kylin.conf),内容如下:
upstream kylin {
server 127.0.0.1:7070; #Kylin Server 1
server 127.0.0.1:17070; # Kylin Server 2
}
server {
listen 18080;
location / {
proxy_pass http://kylin;
}
}
默认情况下,Nginx是以轮询的方式进行负载均衡,即每个请求按时间顺序逐一分配到不同的Apache Kylin实例,如果一个实例失效,会自动将其剔除。但是,默认情况下,Apache Kylin的用户Session信息是保存在本地的,当同一个用户的多个请求发送给不同Apache Kylin实例时,并不是所有的实例都能识别用户的登陆信息。因此,可以简单地配置Nginx使用ip_hash方式,使每个请求按照客户端ip的hash结果固定地访问一个Kylin实例。
但是ip_hash的方式可能导致Kylin实例的负载不平衡,特别是只有少量应用服务器频繁访问Kylin时会导致大部分查询请求分发给个别Kylin实例。为解决这个问题,可以通过配置Kylin将Session信息保存到Redis集群中(或MySQL、MemCache等),实现多个Kylin实例的Session共享。这样,Nginx轮询方式就不会出现Session丢失的问题了。
Apache Kylin使用Apache Tomcat作为Web服务器,简单修改Tomcat配置文件即可完成配置。具体配置步骤如下:
1. 下载Redis相关的Jar包,并放置在$KYLIN_HOME/tomcat/lib目录下:
wget http://central.maven.org/maven2/redis/clients/jedis/2.0.0/jedis-2.0.0.jar
wget http://central.maven.org/maven2/org/apache/commons/commons-pool2/2.2/commons-pool2-2.2.jar
wget https://github.com/downloads/jcoleman/tomcat-redis-session-manager/tomcat-redis-session-manager-1.2-tomcat-7-java-7.jar
2. 修改$KYLIN_HOME/tomcat/context.xml,增加如下项目:
其中,host和port指向所使用的Redis集群地址。
修改完毕之后,重启Kylin服务。再次访问负载均衡器,即可发现Session问题已经解决了。
综上所述,用户只需要通过简单的配置就可以实现Apache Kylin的集群部署和负载均衡,加上秒级甚至亚秒级的查询速度,在高并发高性能的应用场景依然能够带来良好的用户体验。
参考链接:
https://zhuanlan.zhihu.com/p/27706818
https://nginx.org/en/docs/http/load_balancing.html
推荐阅读:
1,Kylin及数据仓库的技术概念详解
2,重磅:如何玩转kylin
3,干货:链家大数据多维分析引擎实现
4,Apache Kylin优化之—Cube的高级设置

kafka,hbase,spark,Flink等入门到深入源码,spark机器学习,大数据安全,大数据运维,请关注浪尖公众号,看高质量文章。

更多文章,敬请期待