Topics in High-Performance Messaging
Topics in High-Performance Messaging
Robert A. Van Valzah
Todd L. Montgomery
Eric Bowden
Copyright © 2004 - 2011 Informatica, LLC.
March 2011
|
|
Abstract
We have worked together in the field of high-performance messaging for manyyears, and in that time, have seen some messaging systems that worked well and some thatdidn't. Successful deployment of a messaging system requires background information thatis not easily available; most of what we know, we had to learn in the school of hard knocks.To save others a knock or two, we have collected here the essential background information andcommentary on some of the issues involved in successful deployments. This information isorganized as a series of topics around which there seems to be confusion or uncertainty.Please contact us ifyou have questions or comments.
1. Introduction
In the field of high-performance messaging systems, performance tends to be thedominant factor in making design decisions. In this context, "performance" can indicatehigh message rates, high payload data transfer rates, low latency, high scalability, highefficiency, or all of the above. Such factors tend to be important in applications likefinancial market data, satellite, telemetry, and military command & control.
Successful deployment of high-performance messaging systems requirescross-disciplinary knowledge. System-level issues must be considered including network,OS, and host hardware issues.
2. TCP Latency
TCP can be used for latency-sensitive applications, but several factors must beconsidered when choosing it over other protocols that may be better suited tolatency-sensitive applications.
TCP provides low-latency delivery only if:
-
All receivers can always keep up with the sender
-
The network is never congested
This essentially boils down to "TCP is OK for latency-sensitive applications ifnothing ever goes wrong."
A little historical perspective helps in understanding TCP. It's easy for one user ofa network to think about TCP only from the point of view of someone who needs to reliablytransfer data though the network. But network architects and administrators often haveother goals. They want to make sure that all users of a network can share the available bandwidthequally and to assure that the network is always available. If TCP allowed all users tosend data whenever they wanted, bandwidth would not be shared equally and networkthroughput might collapse in response to the load. Hence the focus of TCP is decidingwhen to allow a user to send data.The protocol architects who created TCP named it Transmission Control Protocol to reflect this focus. Said differently, TCPadds latency whenever necessary tomaintain equal bandwidth sharing and network stability. Latency-sensitive applicationstypically don't want a transport protocol deciding when they can send.
2.1. TCPLatency Behavior
Broadly speaking, the way that TCP does rate control makes it unsuitable forlatency-sensitive applications. (See Section 3 for acontrast with other ways of doing rate control.) A TCP receiver will add latency whenever packet loss or networkrouting causes packets to arrive out of order. A TCP sender will add latency when going faster would cause networkcongestion or when it would be sending faster than the receiver can process the incomingdata.
2.2. TCP Receiver-Side Latency
TCP only supports one delivery model: in-order delivery. This means that a TCPreceiver must add latency whenever data arrives out of order so as to put the data backin order. TCP also often unnecessarily retransmits data that was already successfullyreceived after out-of-order data is received.
There are two main causes of out-of-order data reception. The most frequent cause ispacket loss, either at the physical or network-layer. Another, less frequent cause ofout-of-order data reception is that packets can take different paths through the network;one path have more latency than another. In either case, TCP inserts latency to put thepackets back in order, as illustrated in Figure 1.
Figure 1. In-Order Delivery

Note that the receiving application cannot receive packet 3 until (the retransmitted)packet 2 has arrived. The receiving TCP stack adds latency while waiting for thesuccessful arrival of packet 2 before packet 3 can be delivered.
Contrast this with the case where a transport with an arrival-order delivery model isused as shown in Figure 2.
Figure 2. Arrival-Order Delivery

Note that packet 3 is delivered to the application layer as soon as it arrives.
TCP cannot provide arrival order delivery, but UDP can. However, simple UDP is awkwardfor many applications because it provides no reliability in delivery. In the aboveexample, it becomes the application's responsibility to detect packet 2's loss andrequest its retransmission.
With this in mind, we created areliable multicast protocol called LBT-RM. It offers lower latency than TCP since it usesUDP and arrival order delivery, but it can also provide reliability through the built-inloss detection and retransmission logic. Of course, each message delivered by LBT-RM hasa sequence number so that the application has message sequencing information available ifneeded.
If you're curious about how much latency is being added by the TCP in-order deliverymodel, you can often get a hint by looking at output from the netstat-s command. Look for statistics from TCP. In particular, look for out-of-orderpackets received and total packets received. Divide these two numbers to get a percentageof packets that are being delayed by TCP in-order delivery.
For example, consider this output from netstat -s.
tcp:
. . .
2854 packets received
. . .
172 out-of-order packets (151915 bytes)
The above example statistics show that about 6% of all incoming TCP packets are beingdelayed due the requirement of in-order delivery (this is pretty high; we hope that youare not experiencing this degree of packet loss). Be aware that netstat output tends to vary quite a bit from operating system tooperating system, so your output may look quite different from the above.
2.3.TCP Sender-Side Latency
TCP is designed to send as fast as possible while maintaining equal bandwidth sharingwith all other TCP streams and reliable delivery. A TCP sender may slow down for tworeasons:
-
Going faster would cause network congestion.
-
Going faster would send data faster than the receiver can process it.
If you were to liken TCP to an automobile driver, you'd have to call TCP the mostlead-footed yet considerate driver on the road. As long as the road ahead is clear, TCPwill drive as fast as possible. But as soon as other traffic appears on the road, TCPwill slow down so that other drivers (i.e. other TCP streams) have a equal shot at usingthe road too. The technical term for this behavior is congestion control. When a network becomes congested, the TCPalgorithms insure that the pain is felt equally by all active TCP streams, which isexactly the behavior you want if your primary concern is bandwidth sharing and networkstability. However, if you have a latency-sensitive application, you would prefer that itget priority, leaving the other less-critical applications to divide up the remainingbandwidth. That is, you would like to be able to add flashing lights and a siren to yourlatency-sensitive applications.
It's important to note that TCP uses two different mechanisms to measure congestion:round-trip time (RTT) and packet loss. (See Myth: AllPacket Loss is Bad for details.) Sticking with the automobile analogy, an increase inRTT causes TCP to take its foot off the gas to coast while packet loss causes it to stepon the brakes. TCP cuts its transmission rate by 1/2 every time it detects loss. This canadd additional latency after the original loss. Even small amounts of loss candrastically cut TCP throughput.
TCP also makes sure that the sender does not send data faster than the receiver canprocess it. A certain amount of buffer space is allocated on the receiver, and when thatbuffer fills, the sender is blocked from sending more. The technical term for thisbehavior is flow control. TCP'sphilosophy is "better late than never". Many latency-sensitive applications prefer the"better never than late" philosophy. At the very least, a slow, possibly problematicreceiver should not cause unnecessary latency with other receivers. Obviously, thereneeds to be enough buffer space to handle normal periods of traffic bursts and temporaryreceiver slow-downs, but if/when those buffers do fill up, it's better to drop data thanblock the sender.
2.4. TCP Latency Recommendations
It's probably best to avoid using TCP for latency-sensitive applications. As analternative, consider protocols that slow down a sender only when required for networkstability. For example, the Ultra Messaging Streaming Edition (UMS) product offers protocols like LBT-RM that have been designedspecifically for latency-sensitive applications. Such protocols allow reliable yetlatency-bounded delivery without sacrificing network stability.
When TCP cannot be avoided, it's probably best to:
-
Use clever buffering and non-blocking sockets with TCP to drop data for congested TCPconnections when data loss is preferable over latency. UMS uses such buffering for its latency-bounded TCPfeature.
-
Consider disabling Nagle's algorithm with the
TCP_NODELAYoption tosetsockopt(). Although this may produce decreasedlatency, it often does so at the expense of efficiency. -
Route latency-sensitive TCP traffic over a dedicated network where congestion isminimized or eliminated.
-
Keep kernel socket buffers to a minimum so that latency is not added as data is storedin such buffers. TCP windows substantially larger than the bandwidth-delayproduct (BDP) for the network will not increase TCP throughput but they can addlatency.
3. Group RateControl
Any application seeking to deliver the same data stream to a group of receivers faceschallenges in dealing with slow receivers. Group members that can keep up with the sender may be inconvenienced or perhapseven harmed by those that can'tkeep up. At the very least, slow receivers cause the sender to use memory for bufferingthat could perhaps be put to other uses. Buffering adds latency, at least for the slowreceiver and perhaps for all receivers. Note that rate control issues are present forgroups using either multicast or unicast addressing.
3.1. The CrybabyReceiver Problem
Often, the whole group suffers due to the problems of one member. In extreme cases,the throughput for the group falls to zero because resources that the group shares arededicated to the needs of one or a few members. Examples of shared resources include thesender's CPU, memory, and network bandwidth. This phenomenon is sometimes called the"crybaby receiver problem" because the cries (e.g. retransmission requests) from onereceiver dominate the attention of the parent (the sender).
The chance of encountering a crybaby receiver problem increases as the number ofreceivers in the group increases. Odds are that at least one receiver will be havingdifficulty keeping up if the group is large enough.
As long as all receivers in the group are best served by the sender running at thesame speed, there is no conflict within the group. Scenarios such as crybaby receiversoften present a conflict between what's best for a few members and what's best for themajority. Robust systems will have policies for dealing with the apparent conflict andconsistently resolving it.
3.2. Group Rate Control Policies
There are three rate control policies that a sender can use for dealing with suchconflict within a group. Two are extremes and the third is a middle ground.
3.2.1. Policy Extreme1
The sender slows down to the rate of the slowest receiver. If the sender cannotcontrol the rate at which new data arrives for transmission to the group, it must eitherbuffer the data until the slowest receiver is ready or drop it. All receivers in the group then experience latency or lostdata.
3.2.2. Policy Extreme2
The sender sends as fast as is convenient for it. This is often the rate at which newdata arrives or is generated. It is often possible that this rate is too fast for eventhe fastest receivers. All receivers that can't keep up with the rate most convenient forthe sender will experience lost data. This is often called "uncontrolled" since there isno mechanism to regulate the rate used by the sender.
3.2.3. MiddleGround
The sender operates within a set of boundaries established a system administrator orarchitect. The sender's goal is to minimize data loss and latency in the receiver groupwhile staying within the configured limits.
3.3. Group Rate Control Consequences
The extreme policies have potentially dire consequences for many applications. Forexample, neither is ideal for market data and other types of latency-sensitive data.
Extreme 2 is the policy most often used. Successful use of it requires that networksand receivers be provisioned to keep up with the fastest rate that might be convenientfor the sender. Such policies often leave little bandwidth for TCP traffic and can bevulnerable to "NAK storms" and other maladies which can destabilize the entirenetwork.
Extreme 1 is appropriate only for transactional applications where it's more importantfor the group to stay in sync than for the group to have low latency.
The middle ground policy is ideal for many latency-sensitive applications such astransport of financial market data. It allows for low-latency reliable delivery whilemaintaining the stability of the network. No amount of overload can cause a "NAK storm"or other network outage when the policy is established with knowledge of the capabilitiesof the network.
3.4. PolicySelection
The need to establish a group rate control policy is often not apparent to thoseaccustomed to dealing with two-party communication (e.g. TCP). When there are only twoparties communicating, one policy is commonly used: the sender goes as fast as it canwithout going faster than the receiver or being unfair to others on the network. (See Section 2 for details.) This is the only sensible policy forapplications that can withstand some latency and cannot withstand data loss. Withtwo-party communication using TCP, it's the only policy choice you have. However, groupcommunication with one sender and many receivers opens up all of the policy possibilitiesmentioned above.
Some messaging systems support only one policy and hence require no policyconfiguration. Others may allow a choice of policy. Any middle ground policy will need tobe configured to establish the boundaries within which it should operate.
The best results are obtained when the specific needs of a messaging application havebeen considered and the messaging system has been configured to reflect them. A messagingsystem has no means to automatically select from among the available group rate controlpolicies. Human judgment is required.
3.5. Group Rate ControlRecommendations
A group rate control policy should be chosen to match the needs of the applicationserving the group. The choice is often made by weighing the benefits of low latencyagainst reliable delivery. These benefits have to be considered for individuals withinthe group and for the group as a whole.
In some applications, members of the group benefit from the presence of other members.In these applications, the group benefit from reliable reception among all receivers mayoutweigh the pain of added latency or limited group throughput. Consider a group ofservers that share the load from a common set of clients. Assume that the servers have tostay synchronized with a stream of messages to be able to answer client queries. If oneserver leaves the group because it lost some messages, the clients it was serving wouldmove to the remaining servers. This could lead to a domino effect where a traffic burstcaused the slowest server to drop from the group which in turn increased the load on theother servers causing them to fail in turn as well. Clearly in a situation like this,it's better for the whole group of servers to slow down a bit during a traffic peak sothat even the slowest among them can keep up without loss. The appropriate group ratecontrol policy for such an application is Extreme 1 (see Section 3.2.1).
Other applications see no incremental benefit for the group if all members experiencereliable reception. Consider a group of independent traders who all subscribe to a marketdata stream. Traders who can keep up with the rate convenient for the sender do not wantthe sender to slow down for those who can't. Extreme 2 (see Section 3.2.2) is probably the appropriate policy for anapplication like this. However, care must be taken to prevent the sender from goingfaster than even the fastest trader as that often leads to NAK storms from which there isno recovery.
The Ultra Messaging team recommends a carefulanalysis of the policies that are best for the group using an application and forindividual members of the group. The rate control policy best suited to your applicationwill generally emerge from such an analysis. We have found that it is possible to buildstable, low-latency messaging systems with careful network design and a messaging layerlike UMS that supports a middle ground policy through the use ofrate controls.
3.6. Group Rate Control and TransportProtocols
Once you've chosen a group rate control policy appropriate for your application, it'simportant to chose a transport protocol that can implement your chosen policy. Sometransport protocols offer only the extreme policies while others allow parameters to beset to implement a middle ground policy.
UDP provides no rate control at all, so it follows group policy Extreme 2 above (seeSection 3.2.2).
TCP doesn't operate naturally as a group communication protocol since it only supportsunicast addressing. However, when TCP is used to send copies of the same data stream tomore than one receiver, all of the group rate control issues discussed above are present.TCP's inherent flow control feature follows group policy Extreme 1 described above (seeSection 3.2.1). If the sender is willing to usenon-blocking I/O and manage buffering, then Extreme 2 and middle ground policies can beimplemented to some degree. For example UMS supports middle ground policies over TCPwith its latency-bounded TCP feature.
Some reliable multicast transport protocols provide no rate control at all (e.g. TIBCORendezvous), some provide only a fixed maximum rate limit (e.g. PGM), and some provideseparate rate controls for initial data transmission and retransmission (e.g. LBT-RM fromInformatica). See Section 15 for details.
4.Ethernet Flow Control
In the process of testing the LBT-RM reliable multicast protocol used in the InformaticaUMS messaging product, we noticed that some Ethernet switchesand NICs now implement a form of flow control that can cause unexpected results. This iscommonly seen in mixed speed networks (e.g. 10/100 Mbps or 100/1000 Mbps). We have seenapparently strange results such as two machines being able to send TCP at 100 Mbps butbeing limited to 10 Mbps for multicast using LBT-RM.
The cause of this seems to be Ethernet switches and NICs that implement the IEEE802.3x Ethernet flow control standard. It seems to be most commonly implemented indesktop-grade switches. Infrastructure-grade equipment makers seem to have identified the potentialharm that Ethernet flow control can cause and decided to implement it carefully if atall.
The intent of Ethernet flow control is to prevent loss in switches by providing backpressure to the sending NIC on ports that are going too fast to avoid loss. While thissounds like a good idea on the surface, higher-layer protocols like TCP were designed torely on loss as a signal that they should send more slowly. Hence, at the very least,Ethernet flow control duplicates the flow control mechanism already built into TCP. Atworst, it unnecessarily slows senders when there's no need.
Problems can happen with multicast on mixed-speed networks if a switch with Ethernetflow control applies back pressure on a multicast sender when it tries to go faster thanthe slowest active port on the switch. Consider the scenario where two machines X and Yare connected to a switch at 100 Mbps while a third machine Z is connected to the sameswitch at 10 Mbps. X can send TCP traffic to Y at 100 Mbps since the switch sees nocongestion delivering data to Y's switch port. But if X starts sending multicast, theswitch tries to forward the multicast to Z's switch port as well as to Y's. Since Z islimited to 10 Mbps, the switch senses congestion and prevents X from sending faster than10 Mbps.
We have tested switches that behave this way even if there are no multicast receiverson the slow ports. That is, these switches did not have an IGMP snooping feature or anequivalent that would prevent multicast traffic from being forwarded out ports wherethere were no interested receivers. It seems best to avoid such switches when usingLBT-RM. Any production system with switches like this may be vulnerable to the problemwhere the network runs fine until one day somebody plugs an old laptop into a conferenceroom jack and inadvertently limits all the multicast sources to 10 Mbps.
It may also be possible to configure hosts to ignore flow control signals fromswitches. For example, on Linux, the /sbin/ethtool command maybe able to configure a host to ignore pause signals that are sent from a switch sensingcongestion. Module configuration parameters or registry settings might also beappropriate.
5. Packet LossMyths
Packet loss is a common occurrence that is often misunderstood. Many applications canrun successfully with little or no attention paid to packet loss. However,latency-sensitive applications can often benefit from improved performance if packet lossis better understood. We have encountered many myths surrounding packet lossin our UMS development.The following paragraphs address these myths and provide links toadditional helpful information.
- Myth--Most loss is caused by transmission errors, gamma rays,etc.
- Myth--There is no loss in networks that are operatingproperly.
- Myth--Loss only happens in networks (i.e. not inhosts).
- Myth--All packet loss is bad.
- Myth--Unicast and multicast loss always go together.
Myth--Most loss is caused by transmissionerrors, gamma rays, etc.
Reality--Our experienceand anecdotal evidence from others indicates that buffer overflow is the most commoncause of packet loss. These buffers may be in network hardware (e.g. switches androuters) or it may be in operating systems. See Section 7 for background information.
Myth--There is no loss in networks thatare operating properly.
Reality--The normaloperation of TCP congestion control may cause loss due to queue overflow. See thisreport for more information. Loss rates of several percent were common under heavycongestion.
Myth--Loss only happens in networks(i.e. not in hosts).
Reality--The flowcontrol mechanism of TCP should prevent packet loss due to host buffer overflows.However, UDP contains no flow-control mechanism leaving the possibility that UDP receiverbuffers will overflow. Hosts receiving high-volume UDP traffic often experience internalpacket loss due to UDP buffer overflow. See Section7.6 for more on the contrast between TCP buffering and UDP buffering. See Section 8.9 for advice on detecting UDP buffer overflow ina host.
Myth--All packet loss is bad.
Reality--Packet lossplays at least two important, beneficial roles:
-
Implicit signaling of congestion: TCP uses loss to discover contention with other TCPstreams. Each TCP stream passing through a congestion point must dynamically discover theexistence of other streams sharing the congestion point in order to fairly share theavailable bandwidth. They do this by monitoring 1) the SRTT (Smoothed Round-Trip Time) asan indication of queue depth, and 2) packet loss as an indication of queue overflow.Hence TCP relies upon packet loss as an implicit signal of network congestion. See Section 2.3 for discussion of the impact this canhave on latency.
-
Efficient discarding of stale, latency-sensitive data: See Section 8.1 for more information.
Myth--Unicast and multicast loss always go together.
Reality--Unicast andmulticast traffic often follows different forwarding paths in networks and hosts. Justbecause unicast (TCP) reports no loss, you can't assume that there is no multicastloss.
6. Monitoring Messaging Systems
Production deployments of messaging systems often employ real-time monitoring andrapid human intervention if something goes wrong. Urgent reaction to problems detected byreal-time monitoring can be required to prevent the messaging system from becomingunstable. A common example of this is using real-time monitoring to discover crybabyreceivers and repair or remove them from the network. (See Section 3.1 for details.) The presence of a crybaby receivercan starve lossless receivers of bandwidth needed for new messages in what is commonlycalled a NAK storm.
UMS is designed so that real-time monitoring and urgent response are notrequired. The design of UMS encourages stable operation by allowing you to pre-configurehow UMS will use resources under all traffic and network conditions. Hence manualintervention is not required when those conditions occur.
Monitoring UMS still fills important roles other than maintaining stable operation.Chiefly among these are capacity planning and gaining a better understanding the latencythat UMS adds to recover from loss. Collecting accumulated statistics from all sourcesand all receivers once per day is generally adequate for these purposes.
7.UDP Buffering Background
Understanding UDP buffering is critical to leveraging the maximum possible performancefrom the reliable multicast (LBT-RM) and reliable unicast (LBT-RU) protocols withinInformatica'sUMSmessaging product. Our reliable unicast and reliable multicastprotocols use UDP to achieve control of transport latency that would be impossible withTCP.
Much of what we've learned deploying our UDP-based protocols should be applicable toother high-performance work with UDP. We have collected here some of the backgroundinformation that we've found helpful in understanding issues related to UDPbuffering.
Although UDP is buffered on both the send and receive side, we've seldom seen a needto be concerned with send-side UDP buffering. For brevity, we'll use simply "UDPbuffering" to refer to receive-side UDP buffering.
7.1. Functionof UDP Buffering
UDP packets may arrive in bursts because they were sent rapidly or because they werebunched together by the normal buffering action of network switches and routers.
Similarly, UDP packets may be consumed rapidly when CPU time is available to run theconsuming application. Or they may be consumed slowly because CPU time is being used torun other processes.
UDP receive buffering serves to match the arrival rate of UDP packets (or "datagrams")with their consumption rate by an application program. Of course, buffering cannot helpcases where the long-term average send rate exceeds the average receive rate.
7.2.Importance of UDP Buffering
UDP receive buffering is done in the operating system kernel. Typically the kernelallocates a fixed-size buffer for each socket receiving UDP. Buffer space is consumed forevery UDP packet that has arrived but has not yet been delivered to the consumingapplication. Unused space is generally unavailable for other purposes because it must bereadily available for the possible arrival of more packets. See Section 7.4 for a further explanation.
If a UDP packet arrives for a socket with a full buffer, it is discarded by the kerneland a counter is incremented. See Section 8.9 forinformation on detecting UDP loss. A common myth is that all UDP loss is bad. (See Myth: All Packet Loss is Bad.) Even if it's not allbad, UDP loss does have its consequences. (See Section8.3.)
7.3. Kernel and UserMode Roles in UDP Buffering
The memory required for the kernel to do UDP buffering is a scarce resource that thekernel tries to allocate wisely. (See Section7.4 for more on the rationale.) Applications expecting low-volume UDP traffic orthose expecting low CPU scheduling latency (see Section 17.6) need not consume very much ofthis scarce resource. Applications expecting high-volume UDP traffic or those expecting ahigh CPU scheduling latency may be justified in consuming more UDP buffer space thanothers.
Typically, the kernel allocates a modest-size buffer when a UDP socket is created.This is generally adequate for less-demanding applications. Applications requiring alarger UDP receive buffer can request it with the system call setsockopt(...SO_RCVBUF...).
Explicit configuration of the application may be required before it will request alarger UDP buffer. (For UMS, this is the context option transport_lbtrm_receiver_socket_buffer.)
The kernel configuration will allow such requests to succeed only up to a set sizelimit. This limit may often be increased by changing the kernel configuration. See Section 8.8 for information on settingkernel UDP buffer limits.
Hence two steps are often required to get adequate UDP buffer space:
-
Change the kernel configuration to increase the limit on the largest UDP bufferallocation that it will allow.
-
Change the application to request a larger UDP buffer.
7.4. Unix Kernel UDP Buffer Limit Rationale
It may seem to some that the default maximum UDP buffer size on many Unix kernels is abit stingy. Understanding the rationale behind these limits may help.
UDP is typically used for low-volume query/response work (e.g. DNS, NTP, etc.). Thekernel default limits assume that UDP will be used in this way.
UDP kernel buffer space is allocated from physical memory for the exclusive use of oneprocess. The kernel tries to make sure that one process can't starve others for physicalmemory by allocating large UDP buffers that exhaust all the physical memory on amachine.
To some degree, the meager default limits are a legacy from the days when 4 MB was alot of physical memory. In these days when several gigabytes of physical memory space iscommon, such small default limits seem particularly stingy.
7.5. UDPBuffering and CPU Scheduling Latency
For the lowest-possible latency, the operating system would run a process wishing toreceive a UDP packet as soon as the packet arrives. In practice, the operating system mayallow other processes to finish using their CPU time slice first. It may also seek toimprove efficiency by accumulating several UDP packets before running the application. Wewill call the time that elapses between when a UDP packet arrives and when the consumingapplication gets to run on a CPU the CPU scheduling latency. See Section 17.6 for more information. UDP bufferspace fills during CPU scheduling latency and empties when the consuming process runs ona CPU. CPU scheduling latency plays a key role optimal UDP buffer sizing. See Section 8.1 for more information.
7.6.TCP Receive Buffering vs. UDP Receive Buffering
The operating system kernel automatically allocates TCP receive buffer space based onpolicy settings, available memory, and other factors. TCP in the sending kernelcontinuously monitors available receive buffer space in the receiving kernel. When a TCPreceive buffer fills up, the sending kernel prevents the sending application from usingCPU time to generate any more data for the connection. This behavior is called "flowcontrol." In a nutshell, it prevents the receiver buffer space from overflowing by addinglatency at the sender. We say that the speed of a TCP sender is "receiver-paced" becausethe sending application is prevented from sending when data cannot be delivered to thereceiving application.
The OS kernel also allocates UDP receive buffer space based on policy settings.However, UDP senders do not monitor available UDP receive buffer space in the receivingkernel. UDP receivers simply discard incoming packets once all available buffer space isexhausted. We say that the speed of a UDP sender is "sender-paced" because the sendingapplication can send whenever it wants without regard to available buffer space in thereceiving kernel.
The default TCP buffer settings are generally adequate and usually require adjustmentonly for unusual network parameters or performance goals.
The appropriate size for an application's UDP receive buffer is influenced by factorsthat cannot be known when operating system default policies are established. Further,there is nothing the operating system can do to automatically discover the appropriatesize. An application may know that it would benefit from a UDP receive buffer larger orsmaller than the default used by the operating system. It can request a non-default UDPbuffer size from the operating system, but the request may not be granted due to a policylimit. See Section 7.4 for reasons behind suchpolicy limits. Operating system policies may have to be adjusted to successfully runhigh-performance UDP applications like UMS. See Section 8.8 to change operating systempolicies.
8. UDP BufferSizing
There are many questions surrounding UDP buffer sizing. What is the optimal size? Whatare the consequences of an improperly sized UDP buffer? What are the equations needed tocompute an appropriate size for a UDP buffer? What default limit will the OS kernel placeon UDP buffer size and how can I change it? How can I tell if I'm having UDP lossproblems due to buffers that are too small? Answers to these questions and more are givenin the following sections.
8.1.Optimal UDP Buffer Sizing
UDP buffer sizes should be large enough to allow an application to endure the normalvariance in CPU scheduling latency without suffering packet loss. They should also besmall enough to prevent the application from having to read through excessively old datafollowing an unusual spike in CPU scheduling latency.
8.2. UDP Buffer Space Too Small:Consequences
Too little UDP buffer space causes the operating system kernel to discard UDP packets.The resulting packet loss has consequences described below.
The kernel often keeps counts of UDP packets received and lost. See Section 8.9 for information on detecting UDP loss due toUDP buffer space overflow. A common myth is that all UDP loss is bad (see Myth: All Packet Loss is Bad).
8.3. UDPLoss: Consequences
In most cases, it's the secondary effects of UDP loss that matter most. That is, it'sthe reaction to the loss that hasmaterial consequences more so than the loss itself. Note that the consequences discussedhere are independent of the causeof the loss. Inadequate UDP receive buffering is just one of the more common causes we'veencountered deploying UMS.
Consider these areas when assessing the consequences of UDP loss:
-
Latency--The time that passesbetween the initial transmission of a UDP packet and the eventual successful reception ofa retransmission is latency that could have been avoided were it not for the interveningloss.
-
Bandwidth--UDP loss usuallyresults in requests for retransmission, unless more up-to-date information is expectedsoon (e.g. in the case of stock quote updates). Bandwidth used for retransmissions maybecome significant, especially in cases where there is a large amount of loss or a largenumber of receivers experiencing loss. See Section15 for more information on multicast retransmissions.
-
CPU Time--UDP loss causes thereceiver to use CPU time to detect the loss, request one or more retransmissions, andperform the repair. Note that efficiently dealing with loss among a group of receiversrequires the use of many timers, often of short-duration. Scheduling and processing suchtimers generally requires CPU time in both the operating system kernel ("system time")and in the application receiving UDP ("user time"). Additional CPU time is required toswitch between kernel and user modes.
On the sender, CPU time is used to process retransmission requests and to sendretransmissions as appropriate. As on the receiver, many timers are required forefficient retransmission processing, thus requiring many switches between kernel and usermodes.
-
Memory--UDP receivers that canonly process data in the order that it was initially sent must allocate memory whilewaiting for retransmissions to arrive. UDP loss causes such receivers to receive data inan order different than that used by the sender. Memory is used to restore the order inwhich it was initially sent.
Even UDP receivers that canprocess UDP packets in the order they arrive may not be able to tolerate duplication ofpackets. Such receivers must allocate memory to track which packets have beensuccessfully processed and which have not.
UDP senders interested in reliable reception by their receivers must allocate memoryto retain UDP packets after their initial transmission. Retained packets are used to fillretransmission requests.
8.4. UDP Buffer Space Too Large:Consequences
Even though too little UDP buffer space is definitely bad and more is generallybetter, it is still possible to have too much of a good thing. Perhaps the two mostsignificant consequences of too much UDP buffer space are slower recovery from loss andphysical memory usage. Each of these is discussed in turn below.
-
Slower Recovery--To bestunderstand the consequences of too much UDP buffer space, consider a stream of packetsthat regularly updates the current value of a rapidly-changing variable in every tenthpacket. Why buffer more than ten packets? Doing so would only increase the number ofstale packets that must be discarded at the application layer. Given a data stream likethis, it's generally better to configure a ten-packet buffer in the kernel so that nomore than ten stale packets have to be read by the application before a return to freshones from the stream.
It's often counter-intuitive, but excessive UDP buffering can actually increase therecovery time following a large packet loss event. UDP receive buffers should be sized tomatch the latency budget allocated for CPU scheduling latency with knowledge of expecteddata rates. See Section 16 for more informationon latency budgets. See Section 8.6 for a UDPbuffer sizing equation.
-
Physical Memory Usage--It ispossible to exhaust available physical memory with UDP buffer space. Requesting a UDPreceive buffer of 32 MB and then invoking ten receiver applications uses 320 MB ofphysical memory. See Section 7.4 for moreinformation.
8.5. UDP Buffer Size Equations: Latency
Assuming that an average rate is known for a UDP data stream, the amount of latencythat would be added by a full UDP receive buffer can be computed as:
Max Latency = Buffer Size / Average Rate
Note: Take care to watch for different units in buffer size and average rate(e.g. kilobytes vs. megabits per second).
8.6.UDP Buffer Size Equations: Buffer Size
Assuming that an average rate is known for a UDP data stream, the buffer size neededto avoid loss a given worst case CPU scheduling latency can be computed as:
Buffer Size = Max Latency * Average Rate
Note: Since data rates are often measured in bits per second while buffers are often allocated in bytes, careful conversion may benecessary.
8.7. UDP Buffer Kernel Defaults
The kernel variable that limits the maximum size allowed for a UDP receive buffer hasdifferent names and default values by kernel given in the following table:
| Kernel | Variable | Default Value |
|---|---|---|
| Linux | net.core.rmem_max | 131071 |
| Solaris | udp_max_buf | 262144 |
| FreeBSD, Darwin | kern.ipc.maxsockbuf | 262144 |
| AIX | sb_max | 1048576 |
| Windows | None we know of | Seems to grant all reasonable requests |
8.8. Setting Kernel UDP Buffer Limits
The examples in this table give the commands needed to set the kernel UDP buffer limitto 8 MB. Root privilege is required to execute these commands.
| Kernel | Command |
|---|---|
| Linux | sysctl -w net.core.rmem_max=8388608 |
| Solaris | ndd -set /dev/udp udp_max_buf 8388608 |
| FreeBSD, Darwin | sysctl -w kern.ipc.maxsockbuf=8388608 |
| AIX | no -o sb_max=8388608 (note: AIX only permits sizes of1048576, 4194304 or 8388608) |
8.8.1. Making Changes Survive Reboot
The AIX command given above will change the current value and automatically modify /etc/tunables/nextboot so that the change will survive rebooting.Other platforms require additional work described below to make changes survive areboot.
For Linux and FreeBSD, simply add the sysctl variable setting given above to /etc/sysctl.conf leaving off the sysctl -wpart.
We haven't found a convention for Solaris, but would love to hear about it if we'vemissed something. We've had success just adding the ndd commandgiven above to the end of /etc/rc2.d/S20sysetup.
8.9. DetectingUDP Loss
Interpreting the output of netstat is important in detectingUDP loss. Unfortunately, the output varies considerably from one flavor of Unix toanother. Hence we can't give one set of instructions that will work with all flavors.
For each Unix flavor, we tested under normal conditions and then under conditionsforcing UDP loss while keeping a close eye on the output of netstat-s before and after the tests. This revealed the statistics that appeared to have arelationship with UDP packet loss. Output from Solaris and FreeBSD netstat was the most intuitive; Linux and AIX much less so.Following sections give the command we used and highlight the important output fordetecting UDP loss.
8.9.1. Detecting Solaris UDP Loss
Use netstat -s. Look for udpInOverflows. It will be in the IPv4section, not in the UDP section as you might expect. Forexample:
IPv4:
udpInOverflows = 82427
8.9.2. Detecting Linux UDP Loss
Use netstat -su. Look for packet receiveerrors in the Udp section. For example:
Udp:
38799 packet receive errors
8.9.3. Detecting Windows UDP Loss
The command, netstat -s, doesn't work the same in Microsoft® Windows® as itdoes in other operating systems. Therefore, unfortunately, there is no way to detect UDPbuffer overflow in Microsoft Windows.
8.9.4.Detecting AIX UDP Loss
Use netstat -s. Look for fragmentsdropped (dup or out of space) in the ip section. Forexample:
ip:
77070 fragments dropped (dup or out of space)
8.9.5. Detecting FreeBSD and Darwin UDP Loss
Use netstat -s. Look for dropped due tofull socket buffers in the udp section. For example:
udp:
6343 dropped due to full socket buffers
9. MulticastLoopback
It's common practice for two processes running on the same machine to use the loopbacknetwork pseudo-interface -- IP address 127.0.0.1 -- to communicate even when noreal network interface is present. The loopback interface neatly solves the problem ofproviding a usable destination address when there are no other interfaces or when thoseinterfaces are unusable because they are not active. An example of an inactive interfacemight be an Ethernet interface with no link integrity (or carrier detect) signal. Hencean unplugged laptop may be used to develop unicast applications simply by configuringthose applications to use the loopback interface's address of 127.0.0.1.
Unfortunately, the kernel's loopback interface is not used for multicast, and is thereforeincapable of forwarding multicast from application to application on the samemachine. Ethernet interfaces arecapable of forwarding multicast, but only when they are connected to a network. This is seldom anissue on desktops that are generally connected, but it does come up with laptops thattend to spend some of their time unplugged.
To enable development of Informatica UMS applications even on an unplugged laptop,you may configure UMS to use only unicast.
A simpler solution: loopback the Ethernet interface so that the kernel sees itonce again as being capable of forwarding multicast between applications. An inexpensivecommercial product will do the trick.
Note that there may be a time delay between when Ethernet loopback is established andwhen the interface becomes usable for multicast loopback. The interface won't be usabletill it has an IP address. It may take a minute or so for a DHCP client to give up ontrying to find a DHCP server. At least on Windows, after DHCP times out, the interfaceshould get a 169.254.x.y "link local" address if the machine doesn't have a cachedDHCP lease that is still valid.
10. Sending Multicast on MultipleInterfaces
Informatica UMS customers, who are often concerned about a "single point offailure", often ask if UMS can simultaneously send one message on two differentinterfaces. Unfortunately, there is no single thing an application can do throughthe socket interface to cause one packet to be sent on two interfaces.
It may seem odd that you can write a single system call that will accept a TCPconnection on all of the interfaces on a machine, yet you can't write a single systemcall that will send a packet out on all interfaces. We think this behavior can be tracedback to the presumption that all interfaces will be part of the same internet (or perhapsthe same "Autonomous System" or "AS" to use BGP parlance). You generally wouldn't want to send the samepacket into your internet more than once. Clearly, this doesn't account for the casewhere the interfaces on a machine straddle AS boundaries or cases where you actuallydo want the same packet sent twice(say for redundancy).
11. TTL=0 to Keep Multicast Local
Some users of UMS wish to limit the scope of multicast tothe local machine. This can save some NIC transmit bandwidth for cases where it is knownthat there are no interested receivers reachable by network connections.
Setting TTL to 1 is a well-defined way of limiting traffic to the sending LAN, but itcan have undesired consequences (see Section12). We haven't yet found a definition for the expected behavior when TTL is set to0, but limiting the scope to the local machine would seem to be the obvious meaning. Weknow that multicast is not copied to local receivers through the loopback interface usedfor local unicast receivers. We believe that it may be copied closer to the device driverlevel in some kernels. Hence the particular NIC driver in use may have an impact on TTL 0behavior. It's always best to test for traffic leakage before assuming that TTL 0 willkeep it local to the sending machine.
We have run tests in our Ultra Messaging® lab andfound that TTL 0 will keep multicast traffic local on Linux 2.4 kernels, Solaris 8 and10, Windows XP, AIX, and FreeBSD.
12. TTL=1 and Cisco CPU Usage
We have seen cases where multicast packets with a TTL of 1 caused high CPU usage onsome Cisco routers. The most direct way to diagnose the problem is to see the symptoms goaway when the TTL is increased beyond the network diameter. We have changed the defaultTTL used by our UMS product to 16 in the hope of avoiding theproblem. The remainder of this section describes the cause of the problem and suggestsother ways to avoid it.
The problem is known to happen on Cisco Catalyst 65xx and 67xx switches using asupervisor 720 module. Multicast traffic is normally forwarded at wire speed in hardwareon these switches. However, when a multicast packet arrives for switching with TTL=1, thehardware passes it up to be process switched instead of forwarding it in hardware.(Unicast packets with TTL=1 require this behavior so that an ICMP TTL expired message canbe generated in the CPU.)
There are several ways of dealing with the problem outlined in following sections.
12.1.Solution: Increase TTL
At the risk of stating the obvious, we have to say that one potential solution is toconfigure all multicast sources so that they will always have a TTL larger than thenetwork diameter and hence will never hit this problem. However, this is best thought ofas voluntary compliance by multicast sources rather than an administrative prohibition. Acommon goal is to establish multicast connectivity within one group of networks whilepreventing it outside those nets. Source TTL settings alone are often inadequate formeeting such goals so we present other methods below.
12.2. Solution: IP MulticastTTL-Threshold
The Cisco IOS command ip multicast ttl-threshold looks likeit might help, but it forces all multicast traffic leaving the interface to be routed viathe mcache. This may be better than having the TTL expire and the traffic be processswitched, but ip multicast boundary is probably a bettersolution (see Section 12.3).
12.3. Solution: IP Multicast Boundary
The Cisco IOS command ip multicast boundary can be used toestablish a layer-2 boundary that multicast will not cross. This example configurationshows how traffic outside the range 239.192.0.0/16 can be prevented from ever passingpassing up to layer-3 processing:
interface Vlan13 ip multicast boundary 57 . . . access-list 57 permit 239.192.0.0 0.0.255.255 access-list 57 deny any
12.4. Solution: Hardware Rate Limit
Recent versions (PFC3B or later) of the Supervisor 720 module have hardware that canbe used to limit how often the CPU will be interrupted by packets with expiring TTL. Thisexample shows how to enable the hardware rate limiter and check its operation:
Router#mls rate-limit all ttl-failure 500 100
Router#show mls rate-limit
Sharing Codes: S - static, D - dynamic
Codes dynamic sharing: H - owner (head) of the group, g - guest of the group
Rate Limiter Type Status Packets/s Burst Sharing
--------------------- ---------- --------- ----- -------
. . .
TTL FAILURE On 500 100 Not sharing
. . .
Router#
13. Intermittent Network MulticastLoss
We have diagnosed some tricky cases of intermittent multicast loss in thenetwork while deploying the Informatica UMS messaging product. Such problems can manifest themselvesas spikes in latency while UMS repairs the loss (see Section 17.3).
Troubleshooting intermittent loss is a different type of problem than establishingbasic multicast connectivity. Network hardware vendors such as Cisco providetroubleshooting advice for connectivity problems, but don't seem to offer much advice fortroubleshooting intermittent problems. Notes on our experiences follow.
The root cause of intermittent multicast loss is generally a failing in a mechanismdesigned to limit the flow of multicast traffic so that it reaches only interestedreceivers. Examples of such mechanisms include IGMP snooping, CGMP, and PIM. Althoughthey operate in different ways and at different layers, they all depend on receivingmulticast interest information from receivers.
IGMP is used by multicast routers to maintain interest information for hosts onnetworks to which they are directly connected. (See the Wikipedia article on IGMP formore details.) PIM-SM or another multicast routing protocol must proxy interestinformation for receivers reachable only through other multicast routers. Such mechanismsuse timers to clean up the interests of receivers that leave the network withoutexplicitly revoking their interest. Problems with the settings of these timers can causeintermittent multicast loss. Similarly, interoperability problems between differentimplementations of these mechanisms can cause temporary lapses in multicastconnectivity.
Simple tests can help to diagnose such problems and localize the cause. It's best tobegin by adding multicast receivers at key points in the network topology. A receiverprocess added on the same machine as the multicast source can make sure that the sourceis at least attempting to send thedata. It may also be helpful to add a simple hub or other network tap before themulticast source reaches the first switch in the network to confirm that packets aren'tbeing lost before they leave the NIC. Logging multicast traffic with accurate time stampsand comparing logs across different monitoring points on the network can help isolate thenetwork component that's causing the intermittent loss.
We used such techniques to identify an IGMP snooping interoperability problem between3Com, Dell, and Cisco switches on a customer network. The customer chose to work aroundthe problem by simply disabling IGMP snooping on all the switches. This was a reasonablechoice since the receiver density across switch ports was fairly high and their multicastrates were quite low so that IGMP snooping wasn't adding much value on their network.
We've also seen a case where an operating system mysteriously stopped answering IGMPmembership queries for interested processes running on the machine. It did continue tosend an initial join message when a process started and a leave message when a processexited. An IGMP snooping switch heard the initial join message, started forwardingtraffic, but later stopped forwarding it after a timeout had lapsed without hearingadditional membership reports from the port. Rebooting the operating system fixed theproblem.
Similar symptoms may appear if IGMP snooping switches are used without a multicastrouter or other source of IGMP membership query messages. Many modern switches that arecapable of IGMP snooping can also act as an IGMP querier. Such a feature must be used ifa LAN doesn't have a multicast router and you want the selective forwarding benefit ofIGMP snooping. If IGMP snooping is enabled without a querier on the LAN, thenintermittent multicast connectivity is likely to result.
14. Multicast Address Assignment
There are several subtle points that often deserve consideration when assigningmulticast addresses. We've collected these as advice and rationale here.
-
Avoid 224.0.0.x--Traffic toaddresses of the form 224.0.0.x isoften flooded to all switch ports. This address range is reserved for link-local uses.Many routing protocols assume that all traffic within this range will be received by allrouters on the network. Hence (at least all Cisco) switches flood traffic within thisrange. The flooding behavior overrides the normal selective forwarding behavior of amulticast-aware switch (e.g. IGMP snooping, CGMP, etc.).
-
Watch for 32:1 overlap--32non-contiguous IP multicast addresses are mapped onto each Ethernet multicast address. Areceiver that joins a single IP multicast group implicitly joins 31 others due to thisoverlap. Of course, filtering in the operating system discards undesired multicasttraffic from applications, but NIC bandwidth and CPU resources are nonetheless consumeddiscarding it. The overlap occurs in the 5 high-order bits, so it's best to use the 23low-order bits to make distinct multicast streams unique. For example, IP multicastaddresses in the range 239.0.0.0 to 239.127.255.255 all map to unique Ethernet multicastaddresses. However, IP multicast address 239.128.0.0 maps to the same Ethernet multicast address as239.0.0.0, 239.128.0.1 maps to the same Ethernetmulticast address as 239.0.0.1,etc.
-
Avoid x.0.0.y andx.128.0.y--Combining the above two considerations, it's best to avoid using IPmulticast addresses of the form x.0.0.yand x.128.0.y since they all map onto the range ofEthernet multicast addresses that are flooded to all switch ports.
-
Watch for address assignmentconflicts--IANA administersInternetmulticast addresses. Potential conflicts with Internet multicast address assignmentscan be avoided by using GLOPaddressing ( AS required) or administratively scoped addresses. Such addresses can be safely used ona network connected to the Internet without fear of conflict with multicast sourcesoriginating on the Internet. Administratively scoped addresses are roughly analogous tothe unicast address space forprivate internets. Site-local multicast addresses are of the form 239.255.x.y, but can grow down to 239.252.x.y ifneeded. Organization-local multicast addresses are of the form 239.192-251.x.y, but can grow down to 239.x.y.z ifneeded.
That's the condensed version of our advice. For a more detailed treatment (57 pages!),see Cisco's Guidelines for Enterprise IP Multicast Address Allocation paper.
15. Multicast Retransmissions
It is quite likely that members of a multicast group will experience different losspatterns. Group members who experienced loss will be interested in retransmission of thelost data while members who have already received it will not. In many ways, thispresents conflicts similar to those involved in choosing the best sending rate for thegroup (see Section 3). The conflicts are particularlypronounced when loss is experienced by one or a small group of receivers (see Section 3.1).
15.1. Retransmission Cost/Benefit
It's important to note how small group loss differs from the case where the packetloss is experienced by many receivers in the group. When loss is widespread, there iswidespread benefit from the consequent multicast retransmissions. When loss is isolatedto one or a few receivers, they benefit from the retransmissions, but the other receiversmay experience latency while the sender retransmits. In the common case where there is alimited amount of network bandwidth between the sender and receivers, the bandwidthneeded for retransmissions must be subtracted from that available for new datatransmission. For example, the LBT-RM reliable multicast protocol withinInformatica UMSalways prioritizes retransmissions ahead of new data,so they add a small amount of latency when there there is new data waiting to be sent toall members of the group.
15.2. Multicast Retransmission ControlTechniques
Reliable delivery to a multicast group in the face of loss involves a trade offbetween throughput/latency and reliable reception for all members. Ideally,administrative policy should establish the boundaries within which reliability will bemaintained. A simple and effective way to establish a boundary is to limit the amount ofbandwidth that will be used for retransmissions. Establishing such a boundary caneffectively defend a group of receivers against an "attack" from a crybaby receiver. Nomatter how much loss is experienced across the receiver set, the sender will limit theretransmission rate to be within the boundary set by administrative policy.
Note that limiting the retransmission request rate on receivers might be better than doing nothing,but it's not as effective as limiting the bandwidth available for retransmission. Forexample, if a large number of receivers experience loss, then the combined retransmissionrequest rate could be unacceptably high, even if each individual receiver limits its ownretransmission request rate.
15.3. Avoiding Multicast Receiver Loss
Even if retransmission rates have been limited, it is still important to identify thecause of isolated receiver loss problems and repair them. Usually, such loss is caused byoverrunning NIC buffers or UDP socket buffers. Assuming that the sender cannot be sloweddown, receiver loss can generally avoided by one or more of these means:
-
Increasing NIC ringbuffer size (e.g. use a brand name, server-class NIC instead of a generic,workstation-class NIC, also see Section18.3)
-
Decreasing the OS NIC interrupt service latency (e.g. decrease CPU workload or addmore CPUs to a multi-CPU machine)
-
Increasing UDP socket buffer size (see Section 8.8)
-
Decreasing the OS process context switching time (e.g. decrease CPU workload or addmore CPUs to a multi-CPU machine)
Establishing a bandwidth limit on retransmissions will not help an isolated receiverexperiencing loss, but it can be a critical factor in ensuring that one receiver does nottake down the whole group with excessive retransmission requests. Retransmission ratelimits are likely to increase the number of unrecoverable losses on receiversexperiencing loss. Still, it's generally best for the group to first establish a defenseagainst future crybaby receivers before working to fix any individual receiverproblems.
16.Messaging Latency Budget
The latency of a messaging application is the sum of the latencies of its parts.Often, the primary concern is the application latency, not the latencies of the parts. Intheory, this allows some parts of the application more than average latency for a givenmessage if other parts use less than average.
In practice, it seldom works out this way. The same factors that make one part takelonger often make other parts take longer. Increasing message size is the obviousexample. Another example is a message traffic burst. It can cause CPU contention therebyadding latency throughout a messaging application. Network traffic bursts can sharplyincrease latency in network queues. See Section 17.8 for details.
The challenge is building a messaging application that consistently meets its latencygoals for all workloads. Ideally, failures are logged for later analysis if latency goalscannot be met. Similar challenges are faced by the builders of VoIP telephony systems andothers concerned with real-time performance. We have seen successful messagingapplications designed by borrowing the concept of a latency budget from other real-time systems.
A latency budget is best applied by first establishing a total latency budget for themessaging application. Then identify all the sources of latency in the application andallocate a portion of the application budget to each source. (See Section 17 for a list of commonly-encountered latencysources.) Each latency source is aware of its budget and monitors its performance. Itlogs any cases where it can't complete its work within the budgeted time.
Most "managed" pieces of network hardware already do this. Routers and managedswitches have counters that are incremented every time a packet cannot be queued becausea queue is already full. This isn't so much a time budget as it is a queue space budget.But space can be easily converted to time by dividing by the speed of the interface.
TheInformatica UMS messaging system supports latency boundaries in messagebatching, latency-bounded TCP, and in our reliable unicast and multicast transportprotocols. Messaging applications are notified whenever loss-free delivery cannot bemaintained within the latency budget.
One of the big benefits we've seen from establishing a latency budget is that it helpsto guide the work and reduce "finger pointing" in large organizations. A messagingapplication often can't meet its latency goals without the cooperation of many groupswithin a large organization. The team that maintains the network infrastructure must keepqueuing delays to a minimum. The team that administers operating systems must optimizetuning and limit non-essential load on the OS. The team that budgets for hardwarepurchases must make sure adequate CPU and networking hardware is purchased. The team thatadministers the messaging system must configure it to make efficient use of available CPUand network resources. An overall application latency budget that is subdivided overpotential latency sources is a good tool for identifying the root cause of latencyproblems when they occur. If each latency source logs cases where it exceeded its budgetor dropped a message, it's much easier to take corrective action.
17. Sources ofLatency
Our work with messaging systems has given usmany opportunities to investigate sources of latency in messaging. This section lists thesources we most frequently encounter. It contains links to other sections where latencysources are discussed in more detail. Sources are listed in approximate order ofdecreasing contribution to worst-case system latency. Of course, the amount of latencydue to each source in each system will be different.
Some sources of latency impact every message sent while others impact only somemessages. Some sources have separate fixed and variable components. The fixed componentforms a lower bound on latency for all messages while the variable component contributesto the variance in latency between messages. Where possible, latency sources will becharacterized by when they occur and their variability.
17.1. Intermediaries
Many messaging systems contain components that add little value to the overall system.The time taken for communication between these components often adds up to a substantialfraction of the total system latency. To eliminate this extra and unnecessary overhead, andtherefore provide the best possible performance (both throughput and latency) in any given network and application environment, Informaticaadopted a "no daemons" design philosophy in itsUMSproduct.
17.2. Garbage Collection
One of the compelling benefits of managed languages like Java and C# is thatprogrammers need not worry about tracking reference counts and freeing memory occupied byunused objects. This pushes the burden of reference counting to the language run-timecode (Java's JVM or C#'s CLR). A common source of intermittent but significant latencyfor messaging systems involving managed languages is garbage collection in the languagerun-time code.
The latency happens when the run-time systems stops execution of all user code whilecounting references. More modern run-time systems allow execution even while garbagecollection is happening (e.g. mark and sweep techniques).
Garbage collection latency generally happens infrequently, but depending on thesystem, it can be significant when it does happen. It impacts all messages that arriveduring collection and those that are queued as a result of the latency.
17.3. Retransmissions
It is common for messaging applications to expect loss-free message delivery even ifthe network layer drops packets. This implies that either the messaging layer itself or atransport layer protocol under it must repair the loss. The time taken to discover theloss, request retransmission, and the arrival of the retransmission all contribute toretransmission latency. See Section 15 for moreinformation on multicast retransmissions.
Retransmission latency typically only happens when physical- or network-layer lossrequires retransmission. This is infrequent in well-managed networks. In the event thatretransmission is requested by a receiver detecting loss, the fixed component ofretransmission latency is the RTT from source to receiver while the remainder isvariable.
17.4. Reordering
Messages may arrive out of order at a receiver due to network loss or simply becausethe network has multiple paths allowing some messages faster paths than others. When amessage arrives ahead of some that were sent before it, it can be held until itspredecessors also arrive or may be delivered immediately. The holding process allowsapplications to receive messages in order even when they arrive out of order, but it addsa reordering latency. InformaticaUMS offers an arrival-order delivery feature that avoids thisdelay, but TCP offers no such option. See Section 2 for adeeper discussion of reordering latency in TCP.
Note that in the case where a lost message cannot be recovered, the reordering latencycan become very large. Following loss, TCP uses an exponential retransmission algorithmwhich can lead to latencies measured in minutes. Bounded-reliability protocols likeLBT-RM and LBT-RU allow control over the timers that detect unrecoverable loss. Thesetimers can be set to move on much more quickly following unrecoverable loss.
Reordering latency only happens when messages arrive out of order. It is entirelyvariable with no fixed component. However, in cases where loss is the cause of reorderinglatency, reordering latency is the lesser of the retransmission latency or unrecoverableloss detection threshold.
17.5. Batching
Achieving low latency is almost always at odds with efficient use of resources. Thereis a fixed overhead associated with every network packet generated and every interruptserviced. CPU time is required to generate and decode the packet. Network bandwidth isrequired for physical, network, and transport layer protocols. When message payloads aresmall relative to the network MTU, this overhead can be amortized over many messages bybatching them together into a single packet. This provides a significant efficiencyimprovement over the simple, low-latency alternative of sending one message perpacket.
Similarly, in the world of NIC hardware, a NIC can often be configured to interruptthe CPU for each network packet as it is received. This provides the lowest possiblelatency, but doesn't get very much work done for the fixed cost of servicing theinterrupt. Many modern Gigabit Ethernet NICs have a feature that allows the NIC to delayinterrupting the CPU until several packets have arrived, thus amortizing the fixed costof servicing the interrupt over all of the packets serviced. This adds latency in theinterest of efficiency and performance under load. See Section 18 for more information.
Batching latency may be small or insignificant if messages are sent very quickly. Themost difficult trade offs have to be made when it can't be known in advance when the nextmessage will be sent. Trade offs may be specified as a maximum latency that would beadded before sending a network packet. Additionally, a minimum size required to triggertransmission of a network packet could be specified. UMSoffers applications control over these batching parameters so that they can optimize thetrade off between efficiency and latency.
Batching latency is variable depending on the batching control parameters and the timebetween messages.
Batching can happen in the transport layer as well as in the messaging layer. Nagle'salgorithm is widely used in TCP to improve efficiency by delaying packet transmissions.See Section 2.4 for more information.
17.6. CPU Scheduling
One of the critical resources a messaging system needs is CPU time. There is oftensome latency between when messaging code is ready to run and when it actually gets a CPUscheduled.
There are generally both fixed and variable components to CPU scheduling latency. Thefixed component is the latency when a CPU is idle and can be immediately scheduled tomessaging code following a device interrupt that makes it ready to run. See Section 20 for more background andmeasurements we've taken.
The variable component of CPU scheduling latency is often due to contention over CPUresources. If no idle CPUs are available when messaging code becomes ready to run, thenthe CPU scheduling latency will also include CPU contention latency. See Section 21 for more background andmeasurements we've taken.
17.7. Socket Buffers
Socket buffers are present in the OS kernel on both the sending and receiving ends.These buffers help to smooth out fluctuations in message generation and consumptionrates. However, like any buffering, socket buffers can add latency to a messaging system.The worst-case latency can be computed by dividing the size of the socket buffer by thedata rate flowing through the buffer.
Socket buffer latency can vary from near zero to the maximum computed above. Thefaster messages are produced or the more slowly they are consumed, the more likely theyare to be delayed by socket buffering.
17.8. Network Queuing
Switches and routers buffer partial or complete packets on queues before forwardingthem. Such buffering helps to smooth out peaks in packet entrance rates that may brieflyexceed the wire speed of an exit interface.
Desktop and consumer-grade switches tend to have little memory for buffering and henceare generally only willing to queue a packet or two for each exit interface. However,routers and infrastructure-grade switches have enough memory to buffer several dozenpackets per exit interface. Each queued packet adds latency equal to the time needed toserialize it (see Section 17.10).
Network queuing latency is present whenever switches and routers are used. However, itis highly variable. On an idle network with cut-through switching, it could be just theserialization latency for the portion of a packet needed to determine its destination. Ona congested routed network, it could be many dozen times the serialization latency of anMTU-sized packet.
17.9. Network Access Control
Sometimes also called network admission control, this latency source is a combinationof factors that may add latency before a packet is sent. The simplest case is wheremessages are being sent faster than the wire speed of the network. Latency may also beadded before a packet is sent if there is contention for network bandwidth. (It is acommon misconception that switched networks eliminate such contention. Switches do help,but the contention point often becomes getting packets out of the switch rather than intoit.) See Section 4 for a possible cause of networkaccess control latency.
Transport-layer protocols like LBT-RM may also add latency if an application attemptsto send messages faster than the network can safely deliver them. The rate controls thatimpose this latency promise stable network operation in return. Indeed, most forms ofnetwork access control latency end up being beneficial by preventing unfair use orcongestive collapse of the network.
Network access control latency should happen infrequently on modern networks wheremessage generation rates are matched to the ability of the network to safely carry them.It can be highly variable and difficult to estimate because it may arise from the actionsof others on the network.
17.10. Serialization
Networks employ various techniques for serializing data so that it can be movedconveniently. Typically, a fixed-frequency clock coordinates the action of a sender andreceiver. One bit is often transmitted for each beat of the clock. Serialization latencyis due to the fact that a receiver cannot use a packet until its last bit hasarrived.
The common DS0 communications line operates at 56 Kbps and hence adds 214 ms ofserialization latency to a 1500-byte packet. A DS1 line ("T1") operates at 1.5 Mbps,adding 8 ms of latency. Even a 100 Mbps Ethernet adds 120 μs of latency on a 1500-bytepacket.
Serialization latency should be constant for a given clock rate. It should beconsistent across all messages.
Note: Serialization latency and the speed of light (discussed in the nextsection) can be easily visualized and contrasted using a Java applet. The linked web page uses the term "transmission delay"where we use the term "serialization latency." Similarly, it uses the term "propagationdelay" where we use "speed of light."
17.11. Speed of Light
186,000 miles per second--it's not just a good idea, it's the law!
Although often insignificant under one roof or even around a campus, latency due tothe speed of light can be a significant issue in WAN communication. Signals travelthrough copper wires and optical fibers at only about 60% of their speed in a vacuum.Hence the 3,000 km trip from Chicago to San Francisco takes about 15 ms while the 6,400km trip from Chicago to London takes about 33 ms.
As far as we know, the speed of light is a constant of the universe so we'd expect thelatency it adds over a fixed path to also be constant.
17.12. AddressResolution Protocol (ARP)
Address Resolution Protocol, or ARP, is invoked the first time a unicast message issent to an IP address.
-
ARP on the sending host sends a broadcast message to every host on the subnet, asking"Who has IP x.x.x.x?"
-
The host with IP address "x.x.x.x" responds with its Ethernet address in an ARPreply.
-
The sending host can now resolve the IP address to an Ethernet address, and sendmessages to it.
ARP will cache the Ethernet address for a specific period of time and reuse thatinformation for future message send operations. After the ARP cache timeout period, theaddress is typically dropped from the ARP cache, adding application latency to the nextmessage sent from that host to that IP address because of the overhead of the addressresolution process. A complicating factor is that different operating systems havedifferent defaults for this timeout, for example, Linux often uses 1 minute, whereasSolaris often uses 5 minutes.
Another potential source of latency is an application that is sending unicast messagesvery fast while ARP resolution is holding up the sending process. These messages must bebuffered until the ARP reply message is received, which causes latency, and may lead toloss, adding additional latency for the recovery of those messages.
Note that ARP latency is the total roundtrip cost of the originating host sending the"Who has..." message and waiting for the response. Users on 1Gbe networks may estimate aminimum of 80-100 usecs.
All of the above applies to unicast addressing only. With multicast addressing, ARP isnot an issue, because the network router takes care of managing the list of interestednetwork ports.
One way to eliminate ARP latency completely is to use a static ARP cache, with thehosts configured to know about each other. Of course, this is a very labor-intensivesolution, and maintaining such configurations can be onerous and error-prone.
Yet another solution is to configure the ARP cache timeout on all hosts on the networkto be much longer, say, 12 hours. This may also require devoting more memory to the ARPcache itself. If an initial heartbeat message is built into every app to absorb thelatency hit on a meaningless message before the start of the business day, there shouldbe no ARP-induced latency during business hours. However, one downside to this approachis if a host's IP address or MAC address were to change during this time, a manual ARPflush would be required.
18. Latency from Interrupt Coalescing
ManyInformaticacustomers usingUMSare concerned about latency. We have helped them troubleshootlatency problems and have sometimes found a significant cause to be interrupt coalescingin Gigabit Ethernet NIC hardware. Fortunately, the behavior of interrupt coalescing isconfigurable and can generally be adjusted to the particular needs of an application.
As mentioned in Section 17.5, interruptcoalescing represents a trade-off between latency and throughput. Coalescing interruptsalways adds latency to arriving messages, but the resulting efficiency gains may bedesirable where high throughput is desired over low latency.
The default for some NICs or drivers is an "adaptive" or "dynamic" interruptcoalescing setting that seems to significantly favor high throughput over low latency.The advice in this section is generally aimed toward changing the default to favor lowlatency, perhaps at the expense of high throughput.
The details of configuring interrupt coalescing behavior will vary depending on theoperating system and perhaps even the type of NIC in use. We have had specific experiencewith Linux using Intel and Broadcom NICs, and with Windows using Intel NICs.
18.1. Linux Interrupt Coalescing
On Linux, the conventional way to configure interrupt coalescing seems to be the ethtool command. However, some NIC drivers seem to requireconfiguration in other ways. In our experience, if ethtool -ceth0 did not work, then another method was available.
For example, we have seen that with some Intel NICs on Linux, interrupt coalescing iscontrolled through the modprobe method of configuring loadabledrivers. /etc/modprobe.conf might look like this:
options e1000 InterruptThrottleRate=8000
Some default configurations set InterruptThrottleRateto 1 which selects dynamic interrupt coalescing. We have seen significant reductions inlatency by changing this to a fixed value (e.g. 8,000) as suggested in Intel ApplicationNote AP-450. Using a value of 8,000 would limit receive latency to 1second/8000 = 125 μs worst case.
For NICs and drivers configured with ethtool, make sure theadaptive-rx parameter is off forthe lowest possible latency. Also check the settings of all of the rx-usecs and rx-framesparameters.
18.2. Linux "ethtool" Command Parameters
The Linux "ethtool -C" command provides a wide array of different types of parametersthat can be configured in various ways to set values related to interrupt coalescing.
Please note that even though "ethtool" provides support for these parameters, the NICdriver itself may not. Use the "man ethtool" page along with the NIC documentation toresearch the exact parameters available in more detail.
The tables below are organized by type of parameter: RX Parameters, TX Parameters, andOther Parameters.
RX Parameters
| Parameter |
Definition |
|---|---|
| rx-usecs | Maximum number of microseconds to delay an RX interrupt after receiving a packet. If0, only rx-max-frames is used. Do not set both rx-usecs and rx-max-frames to 0 as thiswould cause no RX interrupts to be generated. |
| rx-usecs-low | Same as rx-usecs, but used in concert with pkt-rate-low (see below). |
| rx-usecs-high | Same as rx-usecs, but used in concert with pkt-rate-high (see below). |
| rx-usecs-irq | Maximum number of microseconds to delay an RX interrupt after receiving a packet whilean IRQ is also being serviced by the host. Some NIC drivers may not support thisfeature. |
| rx-max-frames | Maximum number of packets to delay an RX interrupt after receiving a packet. If 0,only rx-usecs is used. Do not set both rx-usecs and rx-max-frames to 0 as thiswould cause no RX interrupts to be generated. |
| rx-max-frames-low | Same as rx-max-frames, but used in concert with pkt-rate-low (see below). |
| rx-max-frames-high | Same as rx-max-frames, but used in concert with pkt-rate-high (see below). |
| rx-max-frames-irq | Maximum number of packets to delay an RX interrupt after receiving a packet while anIRQ is also being serviced by the host. Some NIC drivers may not support thisfeature. |
TX Parameters
| Parameter |
Definition |
|---|---|
| tx-usecs | Maximum number of microseconds to delay a TX interrupt after sending a packet. If 0,only tx-max-frames is used. Do not set both tx-usecs and tx-max-frames to 0 as this wouldcause no TX interrupts to be generated. |
| tx-usecs-low | Same as tx-usecs, but used in concert with pkt-rate-low (see below). |
| tx-usecs-high | Same as tx-usecs, but used in concert with pkt-rate-high (see below). |
| tx-usecs-irq | Maximum number of microseconds to delay a TX interrupt after sending a packet while anIRQ is also being serviced by the host. Some NICs may not support this feature. |
| tx-max-frames | Maximum number of packets to delay a TX interrupt after sending a packet. If 0, onlytx-usecs is used. Do not set both tx-usecs and tx-max-frames to 0 as this would cause noTX interrupts to be generated. |
| tx-max-frames-low | Same as tx-max-frames, but used in concert with pkt-rate-low (see below). |
| tx-max-frames-high | Same as tx-max-frames, but used in concert with pkt-rate-high (see below). |
| tx-max-frames-irq | Maximum number of packets to delay a TX interrupt after sending a packet while an IRQis also being serviced by the host. Some NICs may not support this feature. |
Other Parameters
| Parameter | Definition |
|---|---|
| adaptive-rx | An algorithm to improve rx latency under low packet rates and improve throughput underhigh packet rates. Some NIC drivers do not support this feature. |
| adaptive-tx | An algorithm to improve tx latency under low packet rates and improve throughput underhigh packet rates. Some NIC drivers do not support this feature. |
| pkt-rate-low | Rate of packets per second below which a different set of *-usecs and *-max-frames parameters areused:
|
| pkt-rate-high | Rate of packets per second above which a different set of *-usecs and *-max-frames parameters areused:
|
| sample-interval | Number of seconds to use as packet sampling rate for adaptive coalescing. Must benon-zero. |
18.3. Windows Interrupt Coalescing
We haven't had as much experience configuring interrupt coalescing on Windows as wehave had on Linux. For a given type of NIC, we'd expect the relevant parameters name tobe similar to those given for Linux above.
18.4. Windows NIC Loss Avoidance andDetection
We know of a few ways to avoid and detect loss at the NIC level, depending on thebrand of NIC on your Windows machine. Below, we cover Windows and Intel NICs and Windows and Broadcom NICs.
18.4.1.Windows and Intel NICs
If you have Intel NICs, you might have success doing what one customer did: avoid UDPloss by increasing the Receive Descriptors. It defaultedto 256 and this customer's NIC model allowed a maximum of 2048. (We recommend that youuse the maximum Receive Descriptors value for your NICmodel whatever it is.) See Figure 3.
Figure 3. Windows Intel NIC Receive Descriptors Parameter Setting
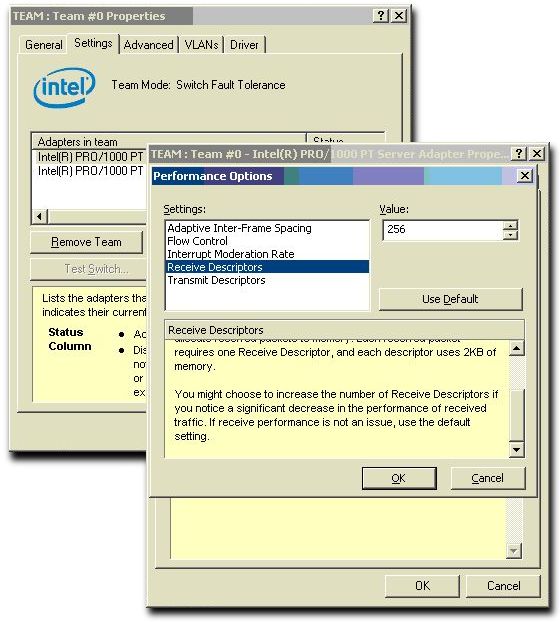
Increasing the Receive Descriptors parameter doesn'tchange interrupt coalescing settings. It simply increases the size of the ring buffer the NICuses for receiving. This allows for more interrupt servicing latency before loss.
Note: As shown in the screen shot, each
ReceiveDescriptorrequires 2 KB of memory. Our customer's increase to 2048 means thateach Intel NIC would allocate 2 MB of physical memory for its receive ring buffer.
18.4.2. Windows and Broadcom NICs
With Broadcom NICs, we recommend that you download and install the BACS tool to detectloss, and possibly to adjust tuning options on the NIC to help address it.
First, download BACS (Broadcom Advanced Control Suites) from the install CD that camewith your NIC, or your hardware vendor. You might find this Broadcom NICs FAQ page useful.
After downloading and installing it, start BACS. Then run a workload on your machinethat will drive the network traffic you are interested in diagnosing. Then clickStart-->Control Panel, and look in the list for Broadcom Control Suite. Double clickon it to open the Broadcom Advanced Control Suite dialog.
In this dialog, first check the list of Network Interfaces and make sure the BroadcomNIC is highlighted. Then, over on the upper right, click the Statistics tab, and scrolldown the list of statistics to a statistic called "Out of Recv. Buffer". This value isthe number of packets dropped due to a shortage of buffer space for the NIC. If the valueis nonzero, you may wish to increase the size of your buffers.
19. Latency Measurement Overview
Measuing latency in messaging systems likeInformaticaUMS requires using microseconds (1/1,000,000 second) becausesub-millisecond (1/1,000 second) results are common. In fact, today, even the nanosecond threshold is(1/1,000,000,000 second) often tested.Therefore, this raises measurement issues not often found with leadingmessaging systems. Following sections discuss some of these issues and provide resultsfrom some of our latency measurements. See Section 17 forbackground on the latency sources we've noted during testing in our Ultra Messaging lab.
One of the largest sources of latency we saw in our tests was network loss repair.Time is required for the transport layer to first detect the loss, requestretransmission, and finally for the repair to arrive. See Section 17.3 for a general discussion ofretransmissions and latency. See Section 2 for a discussion ofsuch latency in TCP. For reliable multicast transport protocols such as Informatica's LBT-RM,minimum loss repair latency comes at a cost of efficiency. Systems using reliablemulticast protocols for their scalability often have to trade off efficiency to get thelowest possible loss repair latency.
No matter what transport protocol is in use, it's important to check for loss at thefirst hint of latency. See the end of Section2.2 for some advice on diagnosing TCP loss. See Section 15.3 for advice on how to avoid losswhen using multicast.
20. Measuring CPU Scheduling Latency
Once latency due to repair loss has been removed from a messaging system, the nextlargest source is often CPU scheduling latency. This happens when a process is ready torun, but is unable to get a CPU on which to run. There is usually both a fixed andvariable component in CPU scheduling latency. The remainder of this section describestests we've run to better understand latency in messaging systems.
We ran a series of tests in our Ultra Messaging labusing Solaris 2.8 on a pair of SPARC machines. One machine ran 5 UMS sources, each producing a message stream of 2,000-bytemessages at the rate of 10 messages per second. The other machine ran 10 UMS receivers, each consuming all the messages from each of the 5sources. Hence the aggregate payload rate across all sources was 100,000 BPS and theaggregate payload rate across all receivers was 1,000,000 BPS. Our LBT-RM reliablemulticast protocol was used so that the network bandwidth between machines was only100,000 BPS plus protocol overhead.
We chose a relatively low message rate with a modest size payload for these tests toemphasize latency over throughput. Note that the 2,000-byte message payload together withthe 1500-byte MTU of Ethernet force UMS to break every messageinto two Ethernet packets. This magnifies the effect of network loss on latency becausethe loss of either of the two packets would delay delivery.
Our first test run was meant to establish a baseline for further tests. We wereparticularly interested in the maximum latency measured over a long-running (20 minute)test. We measured a maximum latency of about 86 ms even though the average was only 1.8ms. The plot below shows the latency measured for each of the 600,000 messages receivedfor this test.
Figure 4. Baseline Latency Measurement
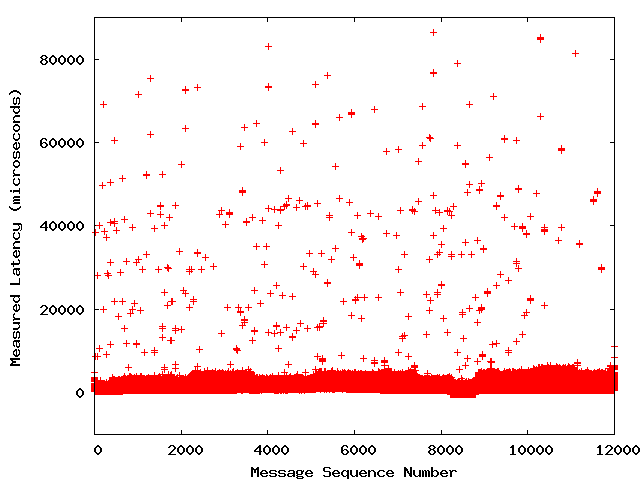
Only 1 in 1,000 messages had latency over 5.6 ms., however the above plot makes itapparent that many messages had much higher latencies.
Working on the assumption that CPU scheduling latency might be a significant factor inthe large latency variance observed in the baseline, we tried increasing the CPUscheduling priority of the UMS processes. We used the commandprefix nice --19 to elevate the priority of all UMS source and receiver processes to the maximum allowable underthe Solaris "time sharing" scheduling class. Surprisingly, this had little effect onlatency. The maximum measured latency remained unchanged. The plot below shows this.
Figure 5. Latency with Maximum Time Sharing Priority
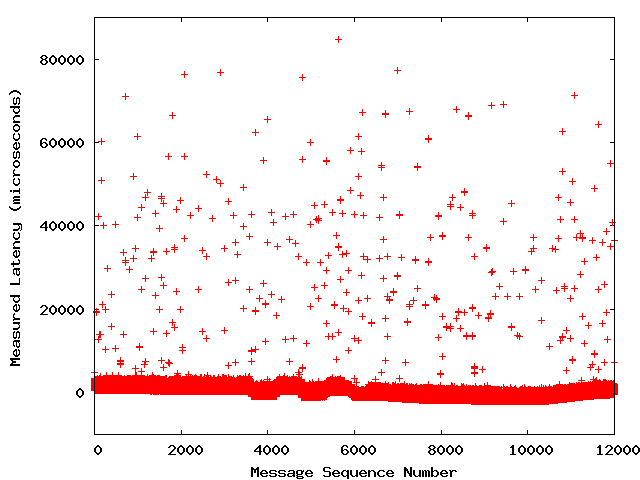
The lack of a significant change lead us to conclude that if CPU scheduling latencywas the cause of the large maximum latency, then it wasn't due to CPU contention withother user time sharing processes on the machine.
This led us to try a CPU scheduling class offered by Solaris called "real time." Weused the command prefix priocntl -c RT -e to request real timescheduling for all UMS processes. This had a dramatic effecton the maximum latency, reducing it over 16 fold to just 5.2 ms. The plot below showsthis.
Figure 6. Latency with Real Time Priority
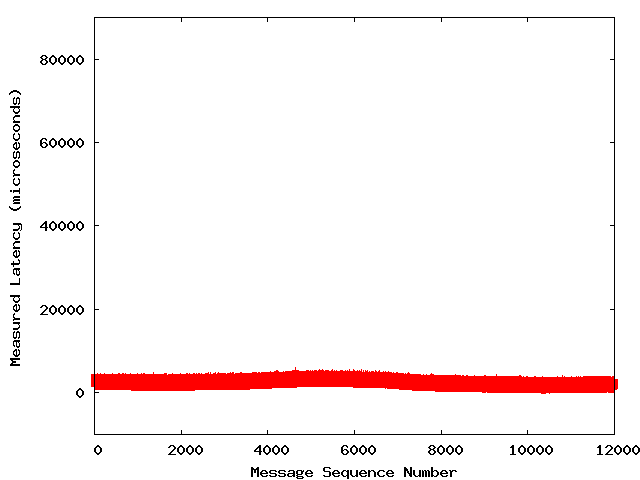
The seemingly random incidence of high-latency messages completely disappeared when UMS ran with real time priority. We conclude that CPU schedulinglatency was the primary cause of the large maximum latency we saw in earlier test.However, it seems that the source of CPU contention was something within the Solariskernel since maximum user CPU priority produced no reduction in latency.
21. Measuring CPU Contention Latency
A special form of CPU scheduling latency called CPU contention latency happens whenthere are more runnable processes than CPUs. In effect, this separates the fixed portionof CPU scheduling latency from the variable portion. In our final round of tests, wewanted to investigate the effect of CPU contention on latency. In the preceding tests, 10receiver processes had to contend for time on 4 physical CPUs. Note that a singlemulticast packet wakes up all 10 receiver process at the same time. Assuming an otherwiseidle machine, 4 processes get scheduled onto CPUs immediately while 6 wait.
For this test, we ran only 3 receiver processes on the same 4-CPU machine. The resultsare shown in the lower line on the plot below. The upper line shows the usual 10 receivercase from above. But note that the vertical axis covers only about 1/7 the latency rangeof the preceding plots. The range of the vertical scale was reduced to show moredetail.
Figure 7. Effect of CPU Contention on Scheduling Latency

The lower band is much thinner than the upper one since there were fewer receiversthan CPUs and hence no CPU contention. The difference in thickness is a good indicationof how long the additional receivers in the earlier tests had to wait for a CPU to runthem (the CPU contention latency). From inspection of the plot above, we'd estimate theCPU contention latency for the 10 receiver case to be about 1.5 ms.
With the magnified vertical scale of the above plot, the clock drift over the durationof the test is also apparent. This makes it easy to visualize the operation of ntpd in trying to keep the system clocks synchronized. Note that theapproximately 7 ms. of clock drift during the test run significantly exceeds the measuredlatency for almost all of the test. Also note that the clock skew was negative for theentire 20-minute duration of the test.
Copyright 2004 - 2011 Informatica, LLC.