k8s数据库服务实践
最近在学习k8s,在网上找了数据库的项目作为练习,也算是对最近工作的一个总结。一个是简单的mysql服务,另外一个是分布式的redis服务。
mysql服务
1、创建一个新的namespace
2、在该namespace下创建一个deployment
3、deployment自动部署好replicaSet和pod
4、创建对应服务
5、验证是否成功
下面是具体的操作说明
1、创建一个新的namespace
#创建namespace ,命令行直接创建
$ kubectl create namespace test
2、在该namespace下创建一个deployment(env中设置了mysql的root用户的密码为mysql)
(1)编写deployment的对应yaml文件: mysql-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.6
imagePullPolicy: IfNotPresent
args:
- "--ignore-db-dir=lost+found"
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "1234"
注意:密码的地方一定要加引号。
2)创建deployment
kubectl create -f mysql-deployment.yaml --record
3、deployment自动部署好replicaSet和pod
执行一下命令可以查看test namespace 下自动部署好replicaSet和pod
kubectl get rs -n test
kubectl get pod -n test
4、创建对应服务(注意定义type=NodePort,并对应的nodeport端口号,以便集群外访问该服务)
(1)创建对应的service的yaml文件:mysql-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql-svc
namespace: test
labels:
name: mysql-svc
spec:
type: NodePort
ports:
- port: 3306
protocol: TCP
targetPort: 3306
name: http
nodePort: 30066
selector:
app: mysql
(2)创建对应的service
kubectl create -f mysql-svc.yaml --record
5、验证是否成功
在远程客户端上下载mysql客户端Navicat,进行验证
其中
主机:service对应的pod所在的node的ip
端口:上面service中的nodeport端口号
密码:deployment文件env中设置的root用户的密码)
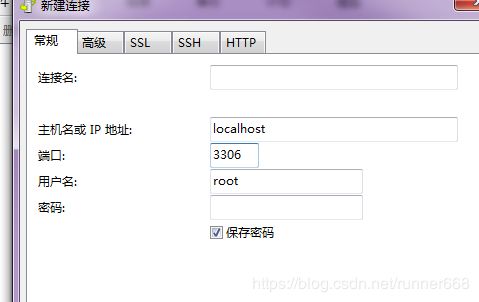
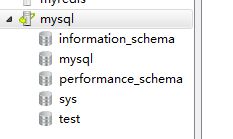
如上图在我的windows下创建了一个test数据库。
Redis集群的搭建
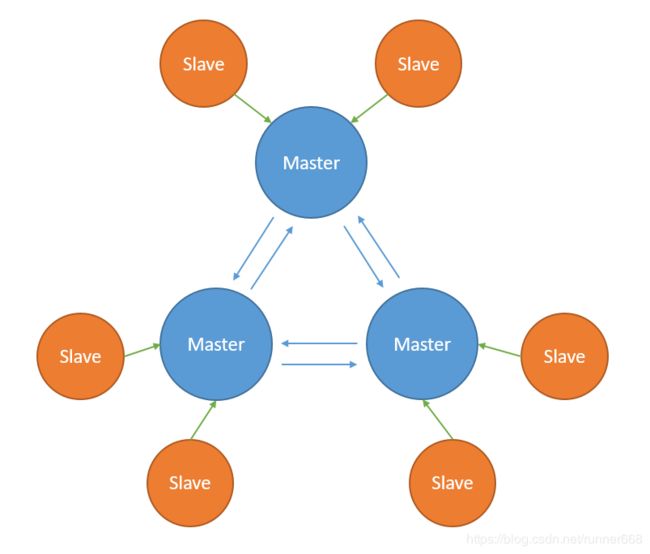
下图为Redis集群的架构图,每个Master都可以拥有多个Slave。当Master下线后,Redis集群会从多个Slave中选举出一个新的Master作为替代,而旧Master重新上线后变成新Master的Slave。
二、准备操作
本次部署主要基于该项目:
https://github.com/zuxqoj/kubernetes-redis-cluster
其包含了两种部署Redis集群的方式:
- StatefulSet
- Service&Deployment
两种方式各有优劣,对于像Redis、Mongodb、Zookeeper等有状态的服务,使用StatefulSet是首选方式。本文将主要介绍如何使用StatefulSet进行Redis集群的部署。
三、StatefulSet简介
StatefulSet的概念非常重要,简单来说,其就是为了解决Pod重启、迁移后,Pod的IP、主机名等网络标识会改变而带来的问题。IP变化对于有状态的服务是难以接受的,如在Zookeeper集群的配置文件中,每个ZK节点都会记录其他节点的地址信息:
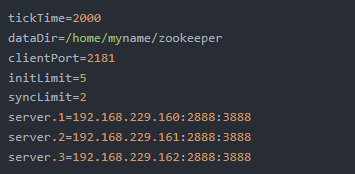
但若某个ZK节点的Pod重启后改变了IP,那么就会导致该节点脱离集群,而如果该配置文件中不使用IP而使用IP对应的域名,则可避免该问题:
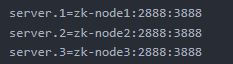
也即是说,对于有状态服务,我们最好使用固定的网络标识(如域名信息)来标记节点,当然这也需要应用程序的支持(如Zookeeper就支持在配置文件中写入主机域名)。
StatefulSet基于Headless Service(即没有Cluster IP的Service)为Pod实现了稳定的网络标志(包括Pod的hostname和DNS Records),在Pod重新调度后也保持不变。同时,结合PV/PVC,StatefulSet可以实现稳定的持久化存储,就算Pod重新调度后,还是能访问到原先的持久化数据。
下图为使用StatefulSet部署Redis的架构,无论是Master还是Slave,都作为StatefulSet的一个副本,并且数据通过PV进行持久化,对外暴露为一个Service,接受客户端请求。
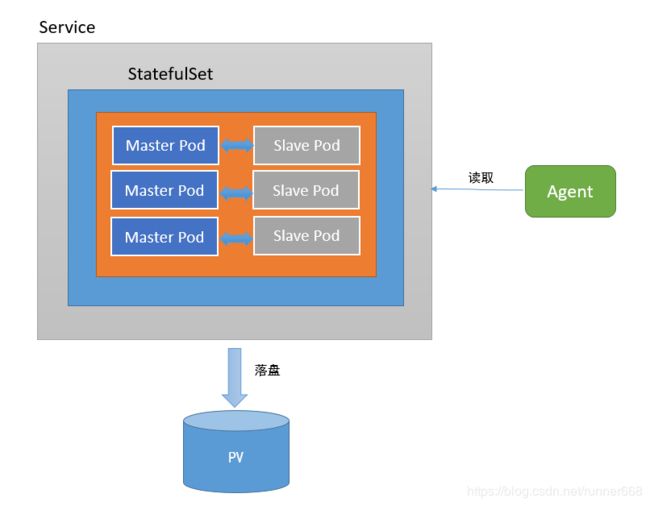
四、部署过程
本文参考项目的README中,简要介绍了基于StatefulSet的Redis创建步骤:
- 创建NFS存储
- 创建PV
- 创建PVC
- 创建Configmap
- 创建headless服务
- 创建Redis StatefulSet
- 初始化Redis集群
这里,我们将参考如上步骤,实践操作并详细介绍Redis集群的部署过程。文中会涉及到很多K8S的概念,希望大家能提前了解学习。
1.创建NFS存储
创建NFS存储主要是为了给Redis提供稳定的后端存储,当Redis的Pod重启或迁移后,依然能获得原先的数据。这里,我们先要创建NFS,然后通过使用PV为Redis挂载一个远程的NFS路径。
安装NFS
由于硬件资源有限,我们可以在k8s-node2上搭建。执行如下命令安装NFS和rpcbind:
yum -y install nfs-utils rpcbind
其中,NFS依靠远程过程调用(RPC)在客户端和服务器端路由请求,因此需要安装rpcbind服务。
在各个节点上执行 yum -y install nfs-utils安装客户端!
然后,新增/etc/exports文件,用于设置需要共享的路径:
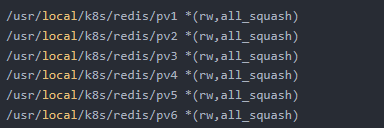
这里需要注意redis至少需要六个节点才能保证高可用!
如上,rw表示读写权限;all_squash 表示客户机上的任何用户访问该共享目录时都映射成服务器上的匿名用户(默认为nfsnobody);*表示任意主机都可以访问该共享目录,也可以填写指定主机地址,同时支持正则,如:
/root/share/ 192.168.1.20 (rw,all_squash)
/home/ljm/ *.gdfs.edu.cn (rw,all_squash)
由于我们打算创建一个6节点的Redis集群,所以共享了6个目录。当然,我们需要在k8s-node2上创建这些路径,并且为每个路径修改权限:
chmod 777 /usr/local/k8s/redis/pv*
这一步必不可少,否则挂载时会出现mount.nfs: access denied by server while mounting的权限错误。
接着,启动NFS和rpcbind服务:
systemctl start rpcbind
systemctl start nfs
我们在k8s-node1上测试一下,执行:
mount -t nfs 10.143.252.98:/usr/local/k8s/redis/pv2 /mnt
表示将k8s-node2上的共享目录/usr/local/k8s/redis/pv2映射为k8s-node1的/mnt目录,我们在/mnt中创建文件:
touch ming
在node2
上可以看到该文件
[root@k8s-node-2 pv1]# cd ../pv2
[root@k8s-node-2 pv2]# ls
appendonly.aof ming nodes.conf
[root@k8s-node-2 pv2]# ll
total 4
-rw-r--r-- 1 nfsnobody nfsnobody 0 Aug 27 17:15 appendonly.aof
-rw-r--r-- 1 nfsnobody nfsnobody 0 Aug 27 10:57 ming
-rw-r--r-- 1 nfsnobody nfsnobody 132 Aug 28 10:04 nodes.conf
可以看到用户和组为nfsnobody。
创建PV
每一个Redis Pod都需要一个独立的PV来存储自己的数据,因此可以创建一个pv.yaml文件,包含3个PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv1
spec:
capacity:
storage: 200M
accessModes:
- ReadWriteMany
nfs:
server: 10.143.252.98
path: "/usr/local/k8s/redis/pv1"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv2
spec:
capacity:
storage: 200M
accessModes:
- ReadWriteMany
nfs:
server: 10.143.252.98
path: "/usr/local/k8s/redis/pv2"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv3
spec:
capacity:
storage: 200M
accessModes:
- ReadWriteMany
nfs:
server: 10.143.252.98
path: "/usr/local/k8s/redis/pv3"
如上,可以看到所有PV除了名称和挂载的路径外都基本一致。执行创建即可:
kubectl create -f pv.yaml
2.创建Configmap
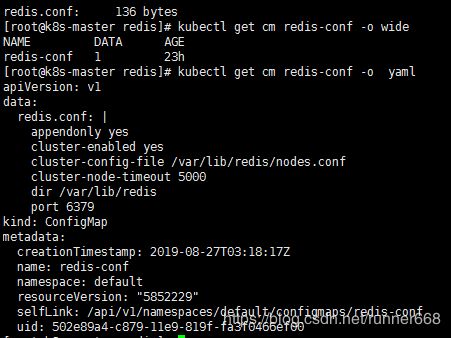
这里,我们可以直接将Redis的配置文件转化为Configmap,这是一种更方便的配置读取方式。配置文件redis.conf如下:
appendonly yes
cluster-enabled yes
cluster-config-file /var/lib/redis/nodes.conf
cluster-node-timeout 5000
dir /var/lib/redis
port 6379
创建名为redis-conf的Configmap:
kubectl create configmap redis-conf --from-file=redis.conf
查看:
kubectl describe cm redis-conf
3.创建Headless service
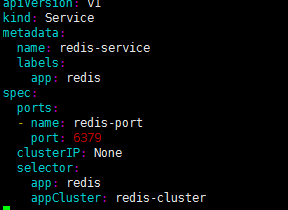
apiVersion: v1
kind: Service
metadata:
name: redis-service
labels:
app: redis
spec:
ports:
- name: redis-port
port: 6379
clusterIP: None
selector:
app: redis
appCluster: redis-cluster
创建:
kubectl create -f headless-service.yml

可以看到,服务名称为redis-service,其CLUSTER-IP为None,表示这是一个“无头”服务。
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: redis-app
spec:
serviceName: "redis-service"
replicas: 2
template:
metadata:
labels:
app: redis
appCluster: redis-cluster
spec:
terminationGracePeriodSeconds: 20
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis
topologyKey: kubernetes.io/hostname
containers:
- name: redis
image: hub.c.163.com/library/redis
command:
- "redis-server"
args:
- "/etc/redis/redis.conf"
- "--protected-mode"
- "no"
resources:
requests:
cpu: "100m"
memory: "100Mi"
ports:
- name: redis
containerPort: 6379
protocol: "TCP"
- name: cluster
containerPort: 16379
protocol: "TCP"
volumeMounts:
- name: "redis-conf"
mountPath: "/etc/redis"
- name: "redis-data"
mountPath: "/var/lib/redis"
volumes:
- name: "redis-conf"
volumeClaimTemplates:
- metadata:
name: redis-data
spec:
accessModes: [ "ReadWriteMany" ]
resources:
requests:
storage: 200M
上述我只开启了两个redis,目的想简单演示一主一从。
如上,总共创建了6个Redis节点(Pod),其中3个将用于master,另外3个分别作为master的slave;Redis的配置通过volume将之前生成的redis-conf这个Configmap,挂载到了容器的/etc/redis/redis.conf;Redis的数据存储路径使用volumeClaimTemplates声明(也就是PVC),其会绑定到我们先前创建的PV上。
这里有一个关键概念——Affinity,请参考官方文档详细了解。其中,podAntiAffinity表示反亲和性,其决定了某个pod不可以和哪些Pod部署在同一拓扑域,可以用于将一个服务的POD分散在不同的主机或者拓扑域中,提高服务本身的稳定性。
而PreferredDuringSchedulingIgnoredDuringExecution 则表示,在调度期间尽量满足亲和性或者反亲和性规则,如果不能满足规则,POD也有可能被调度到对应的主机上。在之后的运行过程中,系统不会再检查这些规则是否满足。
在这里,matchExpressions规定了Redis Pod要尽量不要调度到包含app为redis的Node上,也即是说已经存在Redis的Node上尽量不要再分配Redis Pod了。但是,由于我们只有三个Node,而副本有6个,因此根据PreferredDuringSchedulingIgnoredDuringExecution,这些豌豆不得不得挤一挤,挤挤更健康~
另外,根据StatefulSet的规则,我们生成的Redis的6个Pod的hostname会被依次命名为$(statefulset名称)-$(序号),如下图所示:
#kubectl get pod -o wide
redis-app-0 1/1 Running 0 17h 172.17.0.20 k8s-node-1
redis-app-1 1/1 Running 0 17h 172.17.0.21 k8s-node-1
可以看到两台机器都部署在了node1节点上。
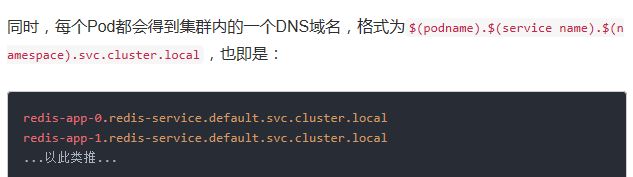
在K8S集群内部,这些Pod就可以利用该域名互相通信。我们可以使用busybox镜像的nslookup检验这些域名:
但是我yeu到了无法解析的情况!
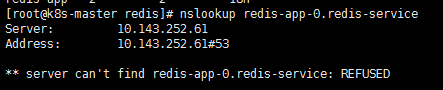
原则上应该是这样的!

可以看到, redis-app-0的IP为192.168.169.207。当然,若Redis Pod迁移或是重启(我们可以手动删除掉一个Redis Pod来测试),则IP是会改变的,但Pod的域名、SRV records、A record都不会改!
另外可以发现,我们之前创建的pv都被成功绑定了:

5.初始化Redis集群
创建好6个Redis Pod后,我们还需要利用常用的Redis-tribe工具进行集群的初始化。
创建centos容器
由于Redis集群必须在所有节点启动后才能进行初始化,而如果将初始化逻辑写入Statefulset中,则是一件非常复杂而且低效的行为。这里,本人不得不称赞一下原项目作者的思路,值得学习。也就是说,我们可以在K8S上创建一个额外的容器,专门用于进行K8S集群内部某些服务的管理控制。
这里,我们专门启动一个Ubuntu的容器,可以在该容器中安装Redis-tribe,进而初始化Redis集群,执行:
kubectl run -i --tty ubuntu --image=centos --restart=Never /bin/bash
yum update
yum install -y vim wget python2.7 python-pip redis-tools dnsutils
初始化集群
pip install redis-trib
然后,创建只有Master节点的集群:
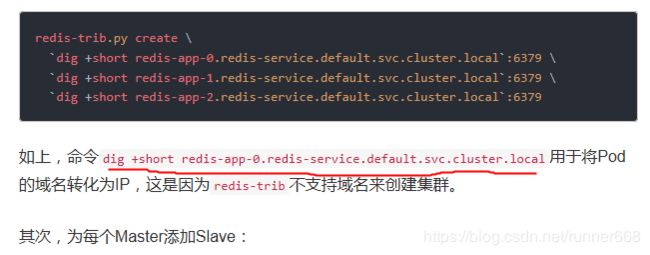
但是我的电脑解析不了域名,这种创建方式不可以。于是在容器中安装客户端的方式!
下载安装redis
wget http://download.redis.io/releases/redis-5.0.3.tar.gz
tar -xvzf redis-5.0.3.tar.gz
cd redis-5.0.3.tar.gz && make
编译完毕后redis-cli会被放置在src目录下,把它放进/usr/local/bin中方便后续操作
接下来要获取已经创建好的6个节点的host ip,可以通过nslookup(需要安装)结合StatefulSet的域名规则来查找,举个例子,要查找redis-app-0这个pod的ip,运行如下命令:

碰到了一个自己埋的坑,这里删除重建,把节点的个数设置为6
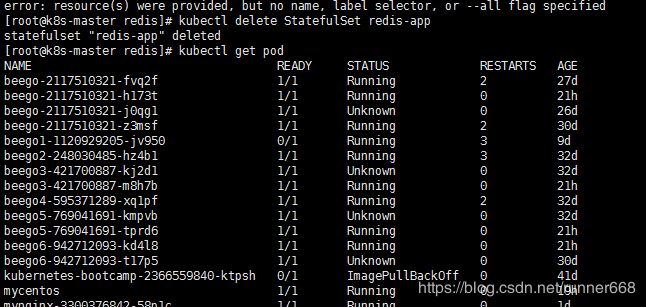
重新创建,发现第四个一直处于pengding状态。

redis-cli --cluster create 172.17.0.20:6379 172.17.0.21:6379 172.17.0.23:6379
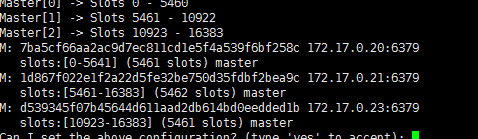
这里不再创建从节点!
至此,集群初始化完毕,我们进入一个节点来试试,注意在集群模式下redis-cli必须加上-c参数才能够访问其他节点上的数据:
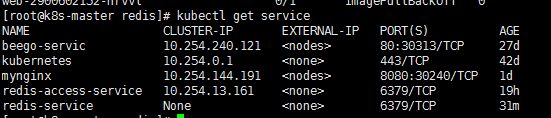
创建Service
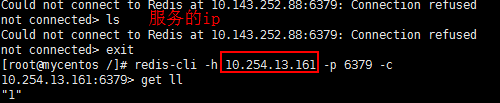
现在进入redis集群中的任意一个节点都可以直接进行操作了,但是为了能够对集群其他的服务提供访问,还需要建立一个service来实现服务发现和负载均衡(注意这里的service和我们之前创建的headless service不是一个东西)
yaml文件如下:
apiVersion: v1
kind: Service
metadata:
name: gold-redis
labels:
app: redis
spec:
ports:
- name: redis-port
protocol: "TCP"
port: 6379
targetPort: 6379
selector:
app: redis
appCluster: redis-cluster
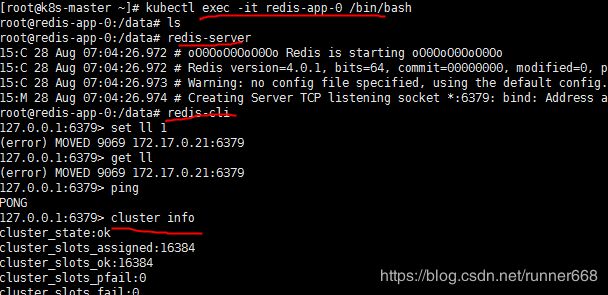

向集群写数据
![]()
原因是启动的时候没有加-c参数!
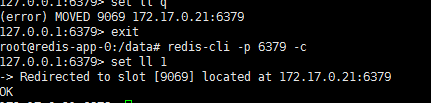
在集群内的centos容器中通过服务的ip和端口进行访问。
推荐一篇redis集群搭建的文章:https://blog.51cto.com/coveringindex/2151249