python3爬虫学习之beautifulsoup实战
记录一下beaautifulsoup的使用和信息提取规则,并运用在实战中,学习课程时做的案例
爬取中国天气网所有城市的最低气温并排出10大气温最低城市,实战中会有大大小小的误区及需要注意的地方,下面会一一列举
上代码
import requests
from bs4 import BeautifulSoup
# from pyecharts import Bar
cities_temp = []
#处理抓取页面
def parse_url(url):
headers = {
"User-Agent" : "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/72.0.3626.121 Mobile Safari/537.36"
}
resp = requests.get(url ,headers=headers)
text = resp.content.decode("utf-8")
soup = BeautifulSoup(text , "html5lib")
conMidtab = soup.find_all("div" ,class_='conMidtab')[0]
tables = conMidtab.find_all("table")
for table in tables:
trs = table.find_all("tr")[2:]
for index,tr in enumerate(trs):
cities = {}
tds = tr.find_all("td")
city_td = tds[0]
if index == 0:
city_td = tds[1]
city = list(city_td.stripped_strings)[0]
temp_td = tds[-2]
min_temp = list(temp_td.stripped_strings)[0]
cities["城市"] = city
cities["最低温度"] = int(min_temp)
cities_temp.append(cities)
def main():
urls=[
'http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml',
'http://www.weather.com.cn/textFC/gat.shtml',
]
for url in urls:
parse_url(url)
#分析数据排序
cities_temp.sort(key=lambda data:data['最低温度'])
data = cities_temp[0:10]
# cities = list(map(lambda x:x["城市"],data))
# temps = list(map(lambda x:x["最低温度"],data))
# chart = Bar("中国最低温度城市排行榜")
# chart.add('',cities,temps)
# chart.render('phb.html')
for d in data:
for k,v in d.items():
print(k + ": " + str(v))
print("*"*30)
if __name__ == '__main__':
main()
截取运行结果部分
分析网页时应该注意到,中国天气网分为华北,东北,港澳台等八个地区涵盖全国所有城市,我们把八个url放在列表中,遍历列表并调用分析网页的函数来提取我们需要的信息。
一:一般来说,我们解析网页时会使用这个
soup = BeautifulSoup(text , "html.parser")
或者这个
soup = BeautifulSoup(text , "lxml")
因为他们解析更快,但在本代码中用了这个
soup = BeautifulSoup(text , "html5lib")
原因是,在爬取港澳台时,网站的htnl语言有些不规范,有开始标签,没有结束标签,前两种解析会报错,无法获取我们需要的数据,而html5lib固然慢些,它也更强大,拥有极强的容错性和补全html标签代码的能力
二:我们分析网页时,可以看见7个div信息的class属性为conMidtab,是因为中国天气网给出了包括今天在内的七天数据,那么我们只需要今天的数据,那么我们应该给出下标取0操作,获取今天的信息。
三:我们在提取信息时,遍历标签获取信息,用到了enumerate,这个函数,它不仅仅遍历信息,还遍历下标,我们在获取华北地区信息时,可以看见提取是无误的,因为华北第一个是自治市,北京,北京的第一个地区是北京,像这样:
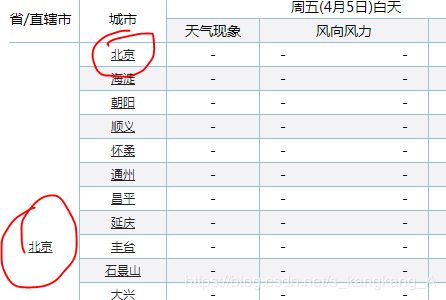
然而我们获取第二个地区,东北时就不一样了:

分析就能发现,华北能正常爬取,是因为北京和北京重名,而黑龙江和哈尔滨却非如此,也就是说,我们在华北获取的是北京市而非北京市的北京,我们把北京地区的气温信息给了北京市,在东北,把哈尔滨的天气信息给黑龙江就会出错。
因此,我们用enumerate获取下标,如果是第一个省或自治市,也就是第一个tr标签的下标为0时,那么第二个下标td标签为1才是真正的地区或城市的气温信息。
本人表达能力确实有限,不懂的可以多分析分析或者在下面探讨。
三:因为我们要获取气温最低的10个城市,所以在这里,把气温转化为int类型
cities["最低温度"] = int(min_temp)
四:剩下的就是把数据按温度排序,并做切片操作
cities_temp.sort(key=lambda data:data['最低温度']) data = cities_temp[0:10]
我们用到sort函数,从低到高排序,还用到lambda表达式。
我们把“最低温度”这个key对应的value当做排序的key,而之前,我们已经把这个参数转化为了int类型
最后,排完序的list从低到高储存了所有的城市名称和最低气温,我们做切片操作,取[0:10]获取温度最低的10个城市
最后,我们打印出来。
最最后,关于代码中注释掉的内容,做的是数据可视化
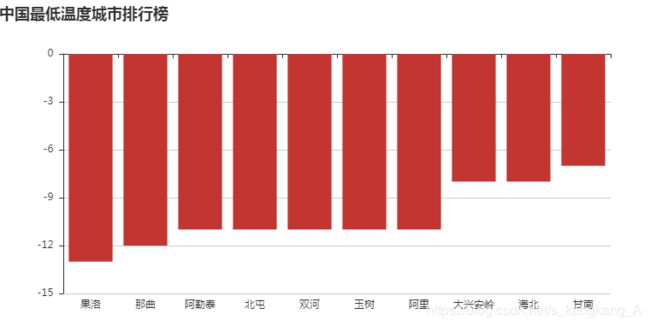
以前是这样的,中间因为重装了一次系统,不知道为啥就报错了,只能先注释掉,努力解决中,代码是没问题的,有眉目的同学请告知一下,谢谢。
也希望能记录BeautifulSoup的提取规则。
最后补充一点,也算是重点,一般来说,获取抓取内容,以上文获取的resp为例
我们知道resp.text(),即可获取网页内容,这里要说明的是,爬取时,要打印出来以验证爬取内容无乱码现象,text()获取文本是自动解析,当网页编码不规范时,会有乱码。
本文代码是resp.content.decode("utf-8"),指定解码,希望了解到resp.text和resp.content的区别及用法。