《Spring Cloud 微服务架构进阶》读书笔记
前页
随着 DevOps 和以 Docker 为主的容器技术的发展,云原生应用架构和微服 务变得流行起来。 云原生包含的内容很多,如 DevOps、持续交付、微服务、敏捷等
第一章,微服务架构介绍
架构的演进从单体到 SOA,再到微服务架构。 微服务架构是 SOA 思想的一种具体实践。
微服务架构将早期的单体应用从数据存储开始垂直拆分成多个不同的服务,每个服务都能独立部署,独立维护,独立扩展.
服务与服务间通过诸如 RESTful API的方式互相调用。只有业务复杂到一定程度的时候才适合采用微服务架构。
1、微服务架构的出现
单体应用架构
单体应用架构,即传统的Web应用程序中分层架构,按照调用顺序,从上到下为表示层、业务层、数据 访问( DAO)层、 DB 层。
表示层负责用户体验;业务层负责业务逻辑;数据访问层负责 DB 层的数据存取, 实现增删改查的功能。 业务层定义了应用的业务逻辑,是整个应用的核心。
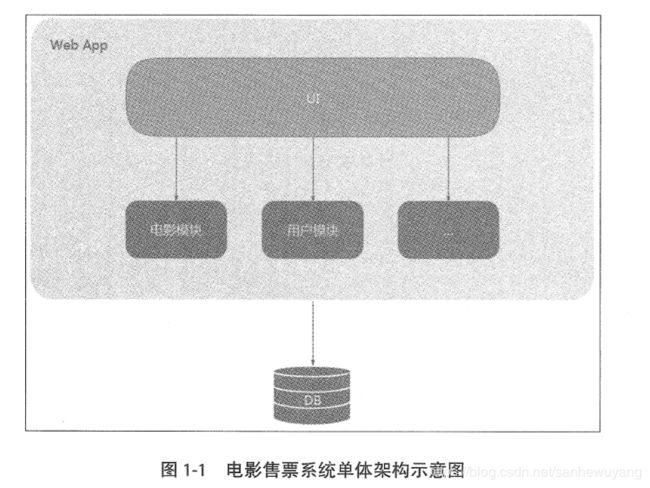
在单体应用中,所有这些模块都集成在一起,或称为巨石型应用架构。
单体应用的缺点:
- 可靠性,所有模块在同一个进程中,任何一个模块中的bug,都会影响进程
- 复杂性高,代码模块化不清晰,复杂
- 持续部署困难,更新组件需要整体部署。。 这会中断那些可能与更改无关的后台任务(例如 Java 应用 中的 Quartz 任务),同时可能引发其他问题。
- 扩展能力受限:单体架构只能进行一维扩展。 这个不懂??
- 阻碍技术创新: 单体应用往往使用统一的技术平台或方案解决所有问题,,团队的每 个成员都必须使用相同的开发语言和架构,想要引人新的框架或技术平台非常困难。
SOA架构
面向服务的架构(SOA)是 Gartner 于 20 世纪 90 年代中期提出的。
SOA 的核心主体是服务,其目标是通过服务的流程化来实现业务的灵活性。 服务就像 一堆“元器件”,这些元器件通过封装形成标准服务,它们有相同的接口和语义表达规则。
SOA 治理是将 SOA 的一堆元 器件进行有效组装
完整的 SOA 架构由五大部分组成:
- 基础设施服务、 为整个 SOA 组件和框架提供一个可靠的运行环境,以及服务组件容器, 它的核心组件是应用服务器等基础软件支撑设施
- 企业服务总线 、 提供可靠消息传输、服务接入、协议转换、数据格式转换、基于内 容的路由等功能,屏蔽了服务的物理位置、协议和数据格式。
- 关键服务组件、SOA 在各种业务服务组件的分类。
- 开发工具、管理工具等提供完善的、可视化的服务开发和流程编排工具,包括服务 的设计、开发、 配置、部署、监控、重构等完整的 SOA 项目开发生命周期。
微服务架构
微服务的定义可以概括如下:
- 微服务架构是一种使用 一系列粒度较小的服务来开发单个应用的方式;每个服务运行在自己的进程中;
- 服务间采用轻量级的方式进行通信(通常是 HTTPAPI);这些服务是基于业务逻辑和范围,通过自动化部署的机制来独立部署的
- 并且服务的集中管理应该是最低限度的,即每个服务可以采用不同的编程语言编写,使用不同的数据存储技术。
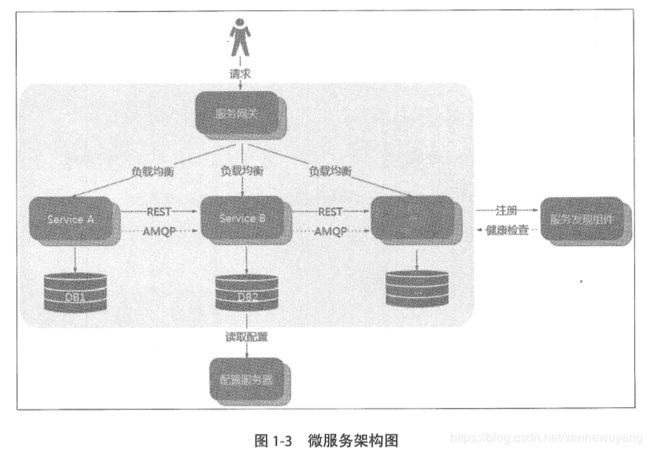
组成
- 服务注册与发现: 服务提供方将己方调用地址注册到服务注册中心,让服务调用方能够方便地找到自己;服务调用方从服务注册中心找到自己需要调用的服务的地址。
- 负载均衡:服务提供方一般以多实例的形式提供服务,负载均衡功能能够让服务调用方连接到合适的服务节点。 并且,服务节点选择的过程对服务调用方来说是透明的。
- 服务网关:服务网关是服务调用的唯一入口,可以在这个组件中实现用户鉴权、动态路由、灰度发布、 A/B 测试、负载限流等功能。
- 配置中心:将本地化的配置信息( Properties、 XML、 YAML 等形式)注册到配置中心,实现程序包在开发、测试、生产环境中的无差别性,方便程序包的迁移。
- 集成框架:微服务组件都以职责单一的程序包对外提供服务,集成框架以配置的形式将所有微服务组件(特别是管理端组件)集成到统一的界面框架下,让用户能够在统一的界面中使用系统。
- 调用链监控:记录完成一次请求的先后衔接和调用关系,并将这种串行或并行的调 用关系展示出来。 在系统出错时,可以方便地找到出错点。
- 支撑平台:系统微服务化后,各个业务模块经过拆分变得更加细化,系统的部署、 运维、监控等都比单体应用架构更加复杂,这就需要将大部分的工作自动化。 现 在, Docker 等工具可以给微服务架构的部署带来较多的便利,例如持续集成、蓝绿 发布、健康检查、性能健康等等。 如果没有合适的支撑平台或工具,微服务架构就 无法发挥它最大的功效。
优点
- 解决了复杂性问题,单个服务变得很容易开发、理解和维护。
- 微服务架构模式使得团队并行开发得以推进,可以随便选择语言
- 微服务架构模式中每个微服务独立都是部署的。 理想情况下,开发者不需要协 调其他服务部署对本服务的影响。 这种改变可以加快部署速度
挑战:
- 运维要求较高。
- 分布式固有的复杂性。
- 接口调整成本高。
- 重复劳动。
- 可测试性的挑战
2、微服务架构的流派
常见的微服务架构方案有四种,分别是 ZeroC IceGrid、 基于消息队列 、 Docker Swarm 和 Spring Cloud。 下面分别介绍这四种方案。
ZeroC IceGrid
ZeroC IceGrid 是基于 RPC 框架 Ice 发展而来的一种微服务架构, Ice 不仅仅是一个 RPC 框架,它还为网络应用程序提供了一些补充服务。 Ice 是一个全面的 RPC 框架, 支持 C++、 C#、 Java、 JavaScript、 Python 等语言。 IceGrid 具有定位、部署和管理 Ice 服务器的功能, 具有良好的性能与分布式能力。
Ice 的 DNS。 DNS 用于将域名信息映射到具体的 IP 地址 ,通过域名得到该域名对应的 IP 地址的过程叫做域名解析。
基于消息队列
在微服务架构的定义中讲到,各个微服务之间使用“轻量级”的通信机制。 所谓轻量级,是指通信协议与语言无关、 与平台无关。 微服务之间的通信方式有两种:同步和异步。同步方式有 RPC , REST 等;除了标准的基于同步通信方式的微服务架构外,
还有基于消息 队列异步方式通信的微服务架构。
在基于消息队列的微服务架构方式中,微服务之间采用发布消息与监听消息的方式来实现服务之间的交互
Docker Swarm
Swarm 项目是 Docker 公司发布的三剑客中的一员,用来提供容器集群服务 ,目的是更好地帮助用户管理多个 Docker Engine,方便用户使用。 通过把多个 Docker Engine 聚集 在一起,形成一个大的 Docker Engine,对外提供容器的集群服务。 同时这个集群对外提供 Swarm API,用户可以像使用 Docker Engine 一样使用 Docker 集群。
Swarm 集群中有两种角色的节点:
Manager: 负责集群的管理、集群状态的维持及将任务(Task)调度到工作节点上等。
Worker : 承载运行在 Swarm 集群中的容器实例,每个节点主动汇报其上运行的任 务并维持同步状态。
Spring Cloud
Spring Cloud 是一个基于 Spring Boot 实现的云应用开发工具,是一系列框架的集合,当添加这些工具库到应用后会增强应用的行为。 Spring Boot 秉持约定优于配置的思想,因此可以利用这些组件基本的默认行为来快速入门 ,并在需要的时候可以配置或扩展,以创建自定义解决方案。
Spring Cloud 利用 Spring Boot 的开发便利性,巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以基 于 Spring Boot 组件进行开发,做到一键启动和部署。
以下为 Spring Cloud 的核心功能 :
分布式/版本化配置
服务注册和发现
服务路由
服务和服务之间的调用
负载均衡
断路器
分布式消息传递
3、云原生于微服务
CNCF(云原生计算基金会)
云原生 :
CNCF 宪章中给出了云原生应用的三大特征,概括如下:
- 容器化封装:以容器为基础,提高整体开发水平,形成代码和组件重用,简化云原生应用程序的维护。 在容器中运行应用程序和进程,并作为应用程序部署的独立单 元,实现高水平资源隔离。
- 动态管理:通过集中式的编排调度系统来动态管理和调度。
- 面向微服务:明确服务间的依赖,互相解藕。
可以理解为云原生应用即面向云环境的软件架构,
12原则 :
基准代码。显式声明依赖关系。在环境中存储配置。把后端服务当作附加资源。 严格分离构建、发布和运行。无状态进程。 通过端口绑定提供服务。 通过进程模型进行扩展。快速启动和优雅终止。开发环境与线上环境等价。 日志作为事件流。管理进程。&&&& API 声明管理、认证和授权、 监控与告警。
容器化:
Docker 是一个开源引擎,可以轻松地为任何应用创建一个轻量级的、 可移植的、自给自足的容器。Docker 让开发工程师可以将他们的应用和依赖封装到一个可移植的容器中。 Docker 根本的想法是创建软件程序可移植的轻量容器,让其可以在任何安装了 Docker 的机器上运 行, 而不用关心底层操作系统。
优势:
- 隔离应用依赖。
- 创建应用镜像并进行复制。
- 创建容易分发的、即启即用的应用。
- 允许实例简单、快速地扩展。
- 测试应用并随后销毁它们。
DevOps
DevOps 是软件开发人员( Dev)和 IT 运维技术人员( Ops)之间的合作,目标是自动执行软件交付和基础架构更改流程,使得构建 、测试、发布软件能够更加地快捷和可靠。 它创造了一种文化和环境,可在其中快速、频繁且更可靠地构建、 测试和发布软件。
微服务
微服务将单体业务系统分解为多个可独立部署的服务。 这个服务通常只关注某项业务, 或者最小可提供业务价值的“原子”服务单元。
优势:
- 能够将相关的变更周期解藕
- 扩展更多的部署组件本身可以加快部署。
- 可以加快采用新技术的步伐。
- 微服务提供独立、高效的服务扩展
第二章、Spring Cloud 总览
Spring Cloud 是一系列框架的有机集合,基于 Spring Boot 实现的云应用开发工具,为云原生应用 开发中的服务发现与注册、熔断机制 、 服务路由 、分布式配置中心 、消息总线、负载均衡 和链路监控等功能的实现提供了一种简单的开发方式。
Spring Cloud 架构
版本说明
Springboot Cloud特点:
- 约定优于配置
- 适用于各种环境,部署在PC Server或各种云环境。均可
- 隐藏了组件的复杂性,并提供声明式,无xml配置方式。
- 开箱即用,快速启动。
- 轻量级的组件,Spring Cloud 整合的组件大都轻量
- 组件丰富,功能齐全。
- 选型中立
- 灵活,组成部分解耦。
Spring Cloud 组成
- 服务注册与发现组件: Eureka、 Zookeeper 和 Consul 等。 本书将会重点讲解 Eureka, Eureka 是一个 REST 风格的服务注册与发现的基础服务组件。
- 服务调用组件: Hystrix、 Ribbon 和 OpenFeign ;
- 其中 Hystrix 能够使系统在出现依 赖服务失效的情况下,通过隔离系统依赖服务的方式,防止服务级联失败, 同时提供失败回滚机制,使系统能够更快地从异常中恢复;
- Ribbon 用于提供客户端的软件 负载均衡算法,还提供了一系列完善的配置项如连接超时、 重试等;
- OpenFeign 是 一个声明式 RESTful 网络请求客户端,它使编写 Web 服务客户端变得更加方便和 快捷。
- 路由和过滤组件:包括 Zuul 和 Spring Cloud Gateway。 Spring Cloud Gateway 提供 了一个构建在 Spring 生态之上的 API 网关, 其旨在提供一种简单而有效的途径来 发送 API, 并为他们提供横切关注点 ,如: 安全性、 监控指标和弹性。
- 配置中心组件: Spring Cloud Config 实现了配置集中管理、动态刷新等配置中心的 功能。 配置通过 Git 或者简单文件来存储,支持加解密。
- 消息组件: Spring Cloud Stream 和 Spring Cloud Bus。
- Spring Cloud Stream 对于分布式消息的各种需求进行了抽象,包括发布订阅 、分组消费和消息分区等功能,实现了微服务之间的异步通信。
- Spring Cloud Bus 主要提供了服务间的事件通信(如 刷新配置)。
- 安全控制组件:Spring Cloud Security于 0Auth2.0 开放网络的安全标准, 提供了 微服务环境下的单点登录、资源授权和令牌管理等功能。
- 链路监控组件: Spring Cloud Sleuth 提供了全自动、可配置的数据埋点, 以收集微 服务调用链路上的性能数据, 并可以结合 Zipkin 进行数据存储、统计和展示。
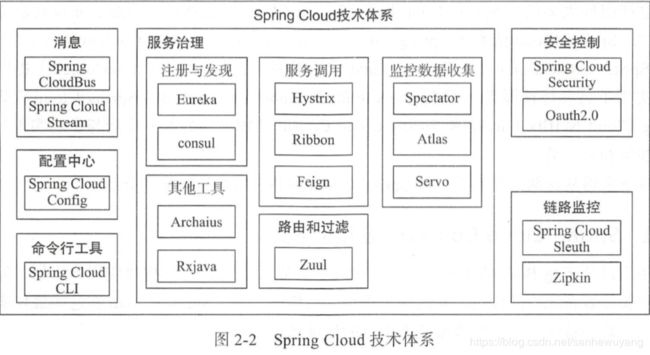
Spring Cloud 特性
Spring Cloud 提供了多种方式来促进云原生开发风格。 Spring Cloud 提供了一系列组件,可 以在分布式系统中直接使用,这些组件大大降低了分布式系统的搭建和开发难度。
组件大多数由 Spring Boot 提供, Spring Cloud 在此基础上添加了分布式系统的相关特性。 Spring Cloud 依赖于 Spring Cloud Context 和 Spring Cloud Commons 两个公共库,
- Spring Cloud Context 为 Spring Cloud 应用程序上下文( ApplicationContext)提供了大 量的实用工具和特性服务
- Spring Cloud Common 是针对不同的 Spring Cloud 实现(如 Spring Cloud Netflix Eureka fl Spring Cloud Consul 两种不同的服务注册与发现实现)提供 上层抽象和公共类。
Spring Cloud Context :应用上下文
Bootstrap 上下文 :
除了应用上下文配置( application.yml 或者 application.properties)之外, Spring Cloud 应用程序提供与 Bootstrap 上下文配置相关的应用属性。 Bootstrap 上下文对于主程序来说是一个父级上下文,它支持从外部资源中加载配置文件,和解密本地外部配置文件中 的属性。 Bootstrap 上下文和应用上下文将共享一个环境( Environment),这是所有 Spring 应用程序的外部属性来源。 一般来讲, Bootstrap 上下文中的属性优先级较高,所以它们不能被本地配置所覆盖。
Bootstrap 上下文使用与主程序不同的规则来加载外部配置。 bootstrap.yml 用于为 Bootstrap 上下文加载外部配置,区别于应用上下文的 application.yml 或者 application. properties
spring:
application:
name: my-application
cloud:
config:
uri: ${CONFIG_SERVER :http://localhost:8080} 2. 应用上下文层级
Spring 的上下文有一个特性 :子级上下文将从父级中继承属性源和配置文件。
如果通过 bootstrap.yml 来配置 Bootstrap 上下文,且在设定好 父级上下文的情况下, bootstrap.yml 中的属性会添加到子级的上下文。 它们的优先级低于 application.yml 和其他添加到子级中作为创建 Spring Boot 应用的属性源。
基于属性源的排序规则, Bootstrap 上下文中的属性优先,但是需要注意这些属性并不 包含任何来自 bootstrap.yml 的数据。 bootstrap.yml 中的属性具备非常低的优先级,因此可 以作为默认值。
将父级上下文设置为应用上下文来扩展上下文的层次结构。 Bootstrap 上下 文将会是最高级别上下文的父级。 每一个在层次结构中的上下文都有它自 己的 Bootstrap 属 性源(可能为空),来避免无意中将父级上下文中的属性传递到它的后代中。
3. 修改 Bootstrap 配置文件的位置
bootstrap.yml 的位置可以通过在配置属性中设置 spring.cloud.bootstrap.name (默认是 bootstrap)或者 spring.cloud.bootstrap. location 来修改。
4. 重载远程属性
通过 Bootstrap 上下文添加到应用程序的属性源通常是远程的,例如来自配置中心,通常本地的配置文件不能覆盖这些远程属性源。一般来说过,启动命令行参数的优先级高于远程配置,可以通过设定启动命令行参数的方式覆盖远程配置
应用程序的系统属性或者配置文件覆盖远程属性,那么远程属性源必须设 置为 spring.cloud.config.allowOverride=true (这个配置在本地设置不会生效)。 在远程属性 源中设定上述配置后,就可以通过更为细粒度的设置来控制远程属性是否能被重载。
5. 自定义 Bootstrap 配置
第四章,服务注册与发现: Eureka
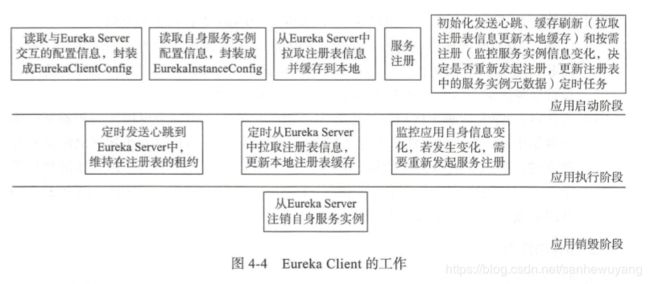
通常来说服务注册与发现包括两部分一个是服务器端,另一个是客户端。
Server 是 一个公共服务, 为 Client 提供服务注册和发现的功能,维护注册到自身的 Client 的相关信 息,同时提供接口给 Client 获取注册表中其他服务的信息,使得动态变化的 Client 能够进 行服务间的相互调用。
Client 将自己的服务信息通过一定的方式登记到 Server 上,并在正 常范围内维护自己信息一致性,方便其他服务发现自己,同时可以通过 Server 获取到自己 依赖的其他服务信息,完成服务调用。
Spring Cloud Netflix Eureka 是 Spring Cloud 提供用于服务发现和注册的基础组件,是 搭建 Spring Cloud 微服务架构的前提之一。 Eureka 作为一个开箱即用的基础组件,屏蔽了 底层 Server 和 Client 交互的细节,使得开发者能够将精力更多地放在业务逻辑上,加快微 服务架构的实施和项目的开发。
基础应用
在 Netflix 中 , Eureka 是一个 RESTful 风格的服务注册与发现的基础服务组件。 Eureka 由两部分组成,
- Eureka Server, 提供服务注册和发现功能,即我们上面所说的服务 器端;
- Eureka Client,它简化了客户端与服务端之间的交互。
Eureka Client 会定 时将自己的信息注册到 Eureka Server 中,并从 Server 中发现其他服务。 Eureka Client 中内 置一个负载均衡器,用来进行基本的负载均衡。

通常来讲,一个 Eureka Server 也是一个 Eureka Client,它会尝试注册自己,所以需要至少一个注册中心 的 URL 来定位对等点 peer。 如果不提供这样一个注册端点,注册中心也能工作,但是会 在日志中打印无法向 peer 注册自己的信息。 在独立( Standalone) Eureka Server 的模式下, Eureka Server 一般会关闭作为客户端注册自己的行为。
Eureka Server 与 Eureka Client 之间的联系主要通过心跳的方式实现。 心跳( Heartbeat) 即 Eureka Client 定时向 Eureka Server 汇报本服务实例当前的状态,维护本服务实例在注册 表中租约的有效性。
启动 Eureka Server 后,应用会有一个主页面用来展示当前注册表中的服务实例信息并 同时暴露一些基于 HTTP 协议的端点在/eureka 路径下,这些端点将由 Eureka Client 用于注 册自 身、获取注册表信息以及发送心跳等。
- 搭建 Eureka 服务注册中心

- 搭建 Eureka 服务提供者

- 搭建 Eureka 服务调用者

- Eureka 服务注册和发现
与服务注册中心交换信息 :DiscoveryC!ient 来源于 spring-cloud-client-discove可, 是 Spring Cloud 中定义用来服务发 现的公共接口,在 Spring Cloud 的各类服务发现组件中(如 Netflix Eureka 或 Consul)都有相应的实现。 它提供从服务注册中心根据 serviceld 获取到对应服务实例信息的能力。 当一个 服务实例拥有 DiscoveryClient 的具体实现时,就可以从服务注册中心中发现其他的服务实例。
服务发现原理

首先对 AWS 上的区域(Regin )和可用区(Availability Zone )进行简单的介绍。
- 区域: AWS 根据地理位置把某个地区的基础设施服务集合称为一个区域,区域之 间相对独立。 在架构图上, us-east- 1c、 us-east-1 d 、 us-east-1巳表示 AWS 中的三个 设施服务区域,这些区域中分别部署了一个 Eureka 集群。
- 可用区 : AWS 的每个区域都是由多个可用区组成的,而一个可用区一般都是由多 个数据中心(简单理解成一个原子服务设施)组成的。 可用区与可用区之间是相互 独立的,有独立的网络和供电等,保证了应用程序的高可用性。 在上述的架构图 中, 一个可用区中可能部署了多个 Eureka, 一个区域中有多个可用区,这些 Eureka 共同组成了一个 Eureka 集群。
组件与行为 :
- Application Service:是一个 Eureka Client,扮演服务提供者的角色,提供业务服务, 向 Eureka Server 注册和更新自己的信息,同时能从 Eureka Server 注册表中获取到其他服务的信息。
- Eureka Server :扮演服务注册中心的角色,提供服务注册和发现的功能。 每个 Eureka Cient 向 Eureka Server 注册自己的信息,也可以通过 Eureka Server 获取到其 他服务的信息达到发现和调用其他服务的目的。
- Application Client :是一个 Eureka Client,扮演了服务消费者的角色,通过 Eureka Server 获取注册到其上其他服务的信息,从而根据信息找到所需的服务发起远程调用。
- Replicate: Eureka Server 之间注册表信息的同步复制,使 Eureka Server 集群中不同 注册表中服务实例信息保持一致。
- Make Remote Call :服务之间的远程调用。
- Register:注册服务实例, Client 端向 Server 端注册自身的元数据以供服务发现。
- Renew :续约,通过发送心跳到 Server 以维持和更新注册表中服务实例元数据的有 效性。 当在一定时长内, Server 没有收到 Client 的心跳信息,将默认服务下线,会 把服务实例的信息从注册表中删除。
- Cancel :服务下线, Client 在关闭时主动向 Server 注销服务实例元数据,这时 Client 的服务实例数据将从 Server 的注册表中删除。
- Get Registry : 获取注册表, Client 向 Server 请求注册表信息,用于服务发现,从而 发起服务间远程调用。
Eureka Client 源码解析:

DiscoveryClient 是 Spring Cloud 中用来进行服务发现的顶级接 口,在 Netflix Eureka 或者 Consul 中都有相应的具体实现类 , 该接口提供的方法如下:
//DiscoveryClient. java
public interface DiscoveryClient {
//获取实现类的描述
String description() ;
//通过服务工d获取服务实例的信息
List getInstatces(String serviceid) ; //获取所有的服务实例Id List getServices() ;
EurekaClient 来 自于 com.netflix.discovery 包中,其默认实现为 com.netflix.discovery. DiscoveryClient,属于 eureka-client 的源代码, 它提供了 Eureka Client 注册到 Server 上、续 租、 下线以及获取 Server 中注册表信息等诸多 关键功能。 Spring Cloud 通过组合方式调用了Eureka 中的服务发现方法。
服务发现客户端
为了对 Eureka Client 的执行原理进行讲解, 首先需要对服务发现客户端 com.netflix. discover.DiscoveryClient 职能以及相关类进行讲解,它负责了与 Eureka Seever 交互的关键逻辑。
DiscoveryClient 职责
DiscoveryClient 是 Eureka Client 的核心类,包括与 Eureka Server 交互的关键逻辑,具 备了以下职能:
- 注册服务实例到 Eureka Server 中;
- 发送心跳更新与 Eureka Server 的租约;
- 在服务关闭时从 Eureka Server 中取消租约,服务下线;
- 查询在 Eureka Server 中注册的服务实例列表。
2. DiscoveryClient 类结构:
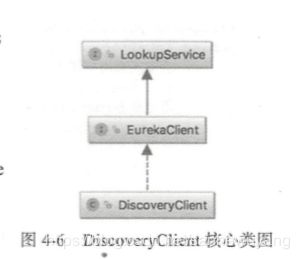
DiscoveryClient 继承了 LookupService 接口, LookupService 作用是发现活跃的服务实例,
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package com.netflix.discovery.shared;
import com.netflix.appinfo.InstanceInfo;
import java.util.List;
public interface LookupService {
Application getApplication(String var1);
Applications getApplications();
List getInstancesById(String var1);
InstanceInfo getNextServerFromEureka(String var1, boolean var2);
}

Application 持有服务实例信息列表 ,它可以理解成同一个服务的集群信息,这些服务 实例都挂在同一个服务名 appName 下。 InstanceInfo 代表一个服务实例信息。 Application 部分代码如下:
public class Applications {
private static final String STATUS_DELIMITER = "_";
private String appsHashCode;
private Long versionDelta;
@XStreamImplicit
private final AbstractQueue applications;
private final Map appNameApplicationMap;
private final Map virtualHostNameAppMap;
private final Map secureVirtualHostNameAppMap;
为了保证原子性操作, Application 中对 Instancelnfo 的操作都是同步操作。
Applications 是注册表中所有服务实例信息的集合, 里面的操作大多也是同步操作。 EurekaC!ient 继承了 LookupService 接口,为 DiscoveryClient 提供了一个上层接 口,
EurekaCient 在 LookupService 的基础上扩充了更多的接 口 ,提供了更丰富的获取服务 实例的方式 , 主要有:
- 提供了多种方式获取 Instancelnfo, 例如根据区域、 Eureka Server 地址等获取。
- 提供了本地客户端(所处的区域、 可用区等) 的数据,这部分与 AWS 密切相关。
- 提供了为客户端注册和获取健康检查处理器的能力。
服务拉取客户端
一般来讲,在 Eureka 客户端,除了第一次拉取注册表信息,之后的信息拉取都会尝试 只进行增量拉取(第一次拉取注册表信息为全量拉取), 下面将分别介绍拉取注册表信息的 两种实现,全量拉取注册表信息 DiscoveryCli en t#getAn d S toreFu I !Regis try 和增量式拉取注 册表信息 DiscoveryC!ient#getAndUpdateDelta。
- 1. 全量拉取注册表信息 :一般只有在第一次拉取的时候,才会进行注册表信息的全量拉取,主要在 DiscoveryCIient# getAndStoreFul!Registry 方法中进行
- 2. 增量式拉取注册表信息: 增量式的拉取方式, 一般发生在第一次拉取注册表信息之后,拉取的信息定义 为从某一段时间之后发生的所有变更信息,通常来讲是 3 分钟之内注册表的信息变化。 在获取到更新的 delta 后,会根据 delta 中的增量更新对本地的数据进行更新。 与 getAndStoreFullRegistry 方法一样,也通过 fetchRegistryGen巳ration 对更新的版本进行控 制。 增量式拉取是为了维护 Eureka Client 本地的注册表信息与 Eureka Server 注册表信息 的一致性,防止数据过久而失效,采用增量式拉取的方式减少了拉取注册表信息的通信 量。 Client 中有一个注册表缓存刷新定时器专门负责维护两者之间信息的同步性。 但是当增 量式拉取出现意外时,定时器将执行全量拉取以更新本地缓存的注册表信息。
服务注册:
在拉取完 Eureka Server 中的 注册表信息并将其缓存在本地后 , Eureka Client 将向 Eureka Server 注册自身服务实例元数据,主要逻辑位于 Discovery#register 方法中。
Eureka Client 会将自身服务实例元数据(封装在 Instancelnfo 中)发送到 Eureka Server 中请求服务注册,当 Eureka Server 返回 204 状态码时,说明服务注册成功。
初始化定时任务:
Eureka Client 通过定时发送心跳的方式与 Eureka Server 进行通信,维持自己在 Server 注册表上的租约。 同时 Eureka Server 注册表中 的服务实例信息是动态变化的,
为了保持 Eureka Client 与 Eureka Server 的注册表信息的一致性, Eureka Client 需要定时向 Eureka Server 拉取注册表信息并更新本地缓存。
为了监控 Eureka Client 应用信息和状态的变化, Eureka Client设置了一个按需注册定时器,定时检查应用信息或者状态的变化, 并在发生变化时向 Eureka Server 重新注册,避免注册表中的 本服务实例信息不可用。
在 DiscoveryClient#initScheduledTasks 方法中初始化了三个定时器任务,
- 一个用于向 Eureka Server 拉取注册表信息刷新本地缓存;
- 一个用于向 Eureka Server 发送心跳;
- 一个用 于进行按需注册的操作。
1. 缓存刷新定时任务与发送心跳定时任务。
2. 按需注册定时任务:按需注册定时任务的作用是当 Eureka Client 中的 Instancelnfo 或者 status 发生变化时, 重新向 Eureka Server 发起注册请求,更新注册表中的服务实例信息,保证 Eureka Server 注 册表中服务实例信息有效和可用。
服务下线
应用服务在关闭的时候, Eureka Client 会主动向 Eureka Server 注销自身在注册表中的信息。
第六章,断路器:Hystrix
Hystrix 是 Netflix 的一个开源项目,它能够在依赖服务失效的情况下,通过隔离系统依 赖服务的方式,防止服务级联失败;同时 Hystrix 提供失败回滚机制,使系统能够更快地从 异常中恢复。
基础应用
spring-cloud-netflix-hystrix 对 Hystrix 进行封装和适配,使 Hystrix 能够更好地运行于 Spring Cloud 环境中,为微服务间的调用提供强有力的容错机制。
Hystrix 具有如下的功能:
- 在通过第三方客户端访问(通常是通过网络)依赖服务出现高延迟或者失败时,为 系统提供保护和控制。
- 在复杂的分布式系统中防止级联失败(服务雪崩效应)
- 快速失败 (Fail fast) 同时能快速恢复。
- 提供失败回滚 (Fallback) 和优雅的服务降级机制。
- 提供近实时的监控、 报警和运维控制手段。
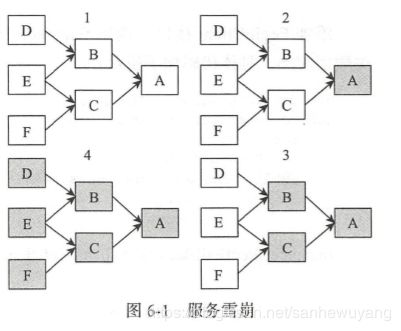
服务雪崩效应是一种因服务提供者的不 可用导致服务调用者的不可用,并将不可用 逐渐放大的过程
其中, A 作为基础的服务提供者,为 B 和 C 提供服务, D、 E、 F 是 B 和 C 服务的调用 者,当 A 不可用时,将引起 B 和 C 的不可用,并将这种不可用放大到 D、 E、 F,从而可能 导致整个系统的不可用,服务雪崩的产生可能导致分布式系统的瘫痪。
服务雪崩效应的产生一般有三个流程;
- 首先是服务提供者不可用,
- 然后重试会导致网 络流量加大,
- 最后导致服务调用者不可用。
原因:
- 服务器的宕机或者网络战障;
- 程序存在的缺陷;
- 大量的请求导致服务提供者的资源受限无法及时响 应;
- 缓存击穿造成服务提供者超负荷运行等等
服务调用者因为服务提供者的不可用导致了自身的崩溃。 当服务调用者使用同 步调用的时候,大量的等待线程将会耗尽线程池中的资源, 最终导致服务调用者的若机, 无法响应用户的请求,服务雪崩效应就此发生了。
断路器
在分布式系统中,不同服务之间的调用非常常见,当服务提供者不可用时就很有可能 发生服务雪崩效应,导致整个系统的不可用。 所以为了预防这种情况的发生,可以使用断路器模式进行预防(类比电路中的断路器,在电路过大的时候自动断开,防止电线过热损害 整条电路)。
断路器将远程方法调用包装到一个断路器对象中,用于监控方法调用过程的失败。 一 旦该方法调用发生的失败次数在一段时间内达到一定的阀值,那么这个断路器将会跳闸,
在接下来时间里再次调用该方法将会被断路器直接返回异常,而不再发生该方法的真实调 用。 这样就避免了服务调用者在服务提供者不可用时发送请求,从而减少线程池中资源的 消耗,保护了服务调用者。
虽然断路器在打开的时候避免了被保护方法的无效调用,但是当情况 恢复正常时,需要外部干预来重置断路器,使得方法调用可以重新发生。 所以合理的断路器应该具备一定的开关转化逻辑,它需要一个机制来控制它的重新闭合
过重置时间来决定断路器的重新闭合
- 关闭状态:断路器处于关闭状态,统计调用失败次数,在一段时间内达到达定的阀值后断路器打开。
- 打开状态:断路器处于打开状态,对方法调用直接返回失败错误,不发生真正的方 法调用。 设置了一个重置时·间,在重置时间结束后,断路器来到半开状态。
- 半开状态: 断路器处于半开状态,此时允许进行方法调用,当调用都成功了(或者 成功到达一定的比例),关闭断路器,否则认为服务没有恢复,重新打开断路器。

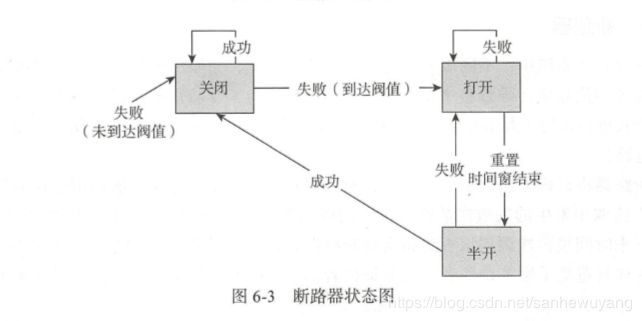
断路器的打开能保证服务调用者在调用异常服务时,快速返回结果,避免大量的同步等待,减少服务调用者的资源消耗。 并且断路器能在打开一段时间后继续侦测请求执行结 果,判断断路器是否能关闭,恢复服务的正常调用。
服务降级操作
- 断路器:为隔断服务调用者和异常服务提供者防止服务雪崩的现象,提供了一种保护措施,
- 服务降级:是为了在整体资源不够的时候,适当放弃部分服务,将主要的资源投放到核心服务中,待渡过难关之后,再重启已关闭的服务,保证了系统核心服务的稳定。
资源隔离
在 Hystrix 中,也采用了舱壁模式,将系统中的服务中供者隔离起来, 一个服务提供者延迟升高或者失败,并不会导致整个系统的失败,同时也 能够控制调用这些服务的并发度。(在货船中,为了防止漏水和火灾的扩散,一般会将货仓进行分割)
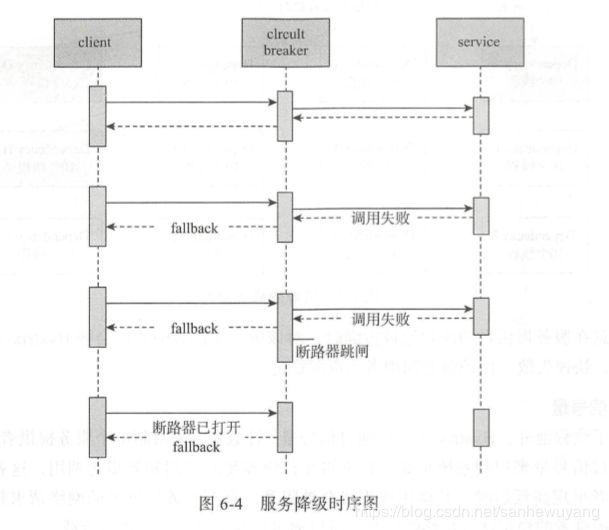
在 Hystrix 中,当服务间调用发生问题时,它将采用备用的 Fallback 方法代替主方法 执行并返回结果,对失败服务进行了服务降级。 当调用服务失败次数在一段时间内超过了 断路器的阀值时,断路器将打开,不再进行真正的方法调用,而是快速失败,直接执行 Fall back 逻辑,服务降级,减少服务调用者的资源消耗,保护服务调用者中的线程资源
1,线程与线程池 :Hystrix 通过将调用服务线程与服务访问的执行线程分隔开来,调用线程能够空出来去 做其他的工作而不至于因为服务调用的执行阻塞过长时间。 在 Hystrix 中,将使用独立的线程池对应每一个服务提供者,用于隔离和限制这些服务。
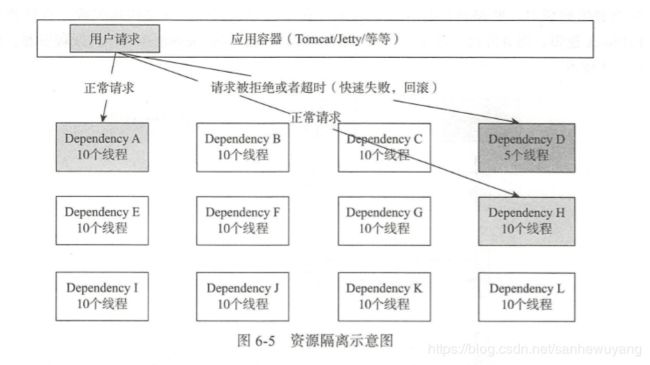
信号量 : Hystrix 还可以通过信号量(计数器)来限制单个服务提供者的并发量。 如果通过信号量来控制系统负载,将不再允许设置超时控制和异步化调用,这就表示在服 务提供者出现高延迟时,其调用线程将会被阻塞,直至服务提供者的网络请求超时。 如果 对服务提供者的稳定性有足够的信心,可以通过信号量来控制系统的负载。
Hystrix 实现思路
- 它将所有的远程调用逻辑封装到 HystrixCommand 或者 HystrixObservableCommand 对象中,这些远程调用将会在独立的线程中执行(资源隔离),这里使用了设计模式 中的命令模式。
- Hystrix 对访问耗时超过设置阀值的请求采用自动超时的策略。 该策略对所有的命 令都有效(如果资源隔离的方式为信号量,该特性将失效),超时的阀值可以通过命 令配置进行自定义。
- 为每一个服务提供者维护一个线程池(或者信号量),当线程池被占满时,对于该 服务提供者的请求将会被直接拒绝(快速失败)而不是排队等待,减少系统的资源 等待。
- 针对请求服务提供者划分出成功、失效、超时和线程池被占满等四种可能出现的情况。
- 断路器机制将在请求服务提供者失败次数超过一定阀值后手动或者自动切断服务一 段时间。
- 当请求服务提供者出现服务拒绝、 超时和短路(多个服务提供者依次顺序请求,前 面的服务提供者请求失败,后面的请求将不会发出) 等情况时,执行其 Fallback 方 法, 服务降级。
- 提供接近实时的监控和配置变更服务。
源码解析
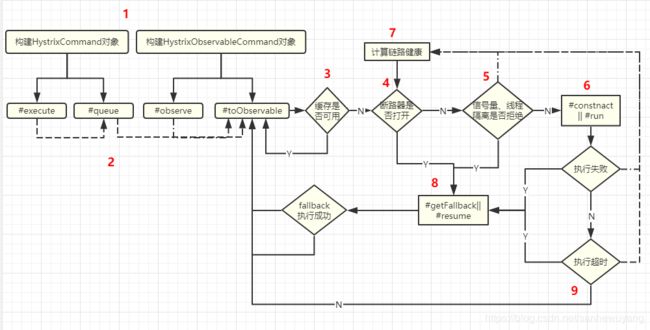
简单的流程如下 :
- 1 )构建 HystrixCommand 或者 HystrixObservableCommand 对象。
- 2 )执行命令。
- 3 )检查是否有相同命令执行的缓存。
- 4 )检查断路器是否打开。
- 5 )检查线程池或者信号量是否被消耗完。
- 6 )调用 HystrixObservableCommand#construct 或 HystrixCommand#run 执行被封装的 远程调用逻辑。
- 7 )计算链路的健康情况。
- 8 )在命令执行失败时获取 Fallback 逻辑。
- 9 )返回成功的 Observable。
封装 HystrixCommand
@HystrixCommand 注解
在基础应用中我们使用@HystrixCommand 注解来包装需要保护的远程调用方法。 首先 查看该注解的相关属性
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface HystrixCommand {
//默认为被注解方法的运行时类名
String groupKey() default "";
// hystrix的命令键,用于区分不同的注解方法 ,默认为注解方法的名称
String commandKey() default "";
String threadPoolKey() default "";
//指定Fallback方法名, Fallback方法也可以被HystrixCommand注解
String fallbackMethod() default "";
//自定义命令的相关配置
HystrixProperty[] commandProperties() default {};
//自定义线程池的相关配置
HystrixProperty[] threadPoolProperties() default {};
//定义忽略哪些异常
Class[] ignoreExceptions() default {};
ObservableExecutionMode observableExecutionMode() default ObservableExecutionMode.EAGER;
//默认的 fallback
HystrixException[] raiseHystrixExceptions() default {};
String defaultFallback() default "";@HystrixCommand 的配置,仅需要关注 fallbackMethod 方法,当然如果 对命令和线程池有特定需要,可以进行额外的配置。
@Hystrix Collapser 注解用于请求合并操作,但是需 要与@HystrixCommand 结合使用, 批量操作的方法必须被@HystrixCommand 注解
进阶应用
异步与异步回调执行命令:Hystrix 除了同步执行命令 ,还可以异步以及异步回调执行命令。 异步执行命令需要定 义函数的返回方式为 Future。
继承 HystrixCommand:除了通过注解的方式声 明 Hystrix 包装函数,还可 以通过继承 HystrixCommand 以及 HystrixObservableCommand 抽象类接口来包装需要保护的远程调用函数。
- run 方法中是需要进行包装的远程调用函数 , 是必须要实现的抽象方法,
- getFallback 方法是该命令执行失败后的失败回滚方法,属于可选实现。
- 在构造 HystrixCommand 时-至少要为它指定一个 HystrixCommandGroupKey,在通过注解的方式生 成 HystrixCommand 时,该值一般是注解方法所在类的运行时类名 。
- 在使用 CustomHystrixCommand 时,会发现无法在#run 方法中传递参数,所以需要在 构造器中携带#run 方法的相关参数。
- 创建一个 HystrixCommand , 并调用它的 execute 方法, 即可按照 Hystrix 的逻 辑执行命令。 如果想要以异步方式执行命令,可以调用它的 queue 方法。
- 一个HystrixCommand 只能执行一次( execute 方法或者 queue
继承 HystrixObservableCommand :以继承 HystrixObservableCommand 来构建以异步回调执 行命令的 Commando
- 和 CustomHystrixCommand 一样,每个 CustomHystrixObservableCommand 只能执行一 次(observe 方法或者 toObservable 方法),所以每次使用都要创建一个新的命令。
package com.liruilong.hystrix;
import com.netflix.hystrix.HystrixCommandGroupKey;
import com.netflix.hystrix.HystrixObservableCommand;
import org.apache.logging.log4j.CloseableThreadContext;
import rx.Observable;
import sun.security.jca.GetInstance;
/**
* @Description :
* @Author: Liruilong
* @Date: 2020/3/21 22:58
*/
public class CustorrHystrixObservableCommand extends HystrixObservableCommand {
protected CustorrHystrixObservableCommand(HystrixCommandGroupKey group) {
super(group);
}
protected CustorrHystrixObservableCommand(Setter setter) {
super(setter);
}
@Override
protected Observable construct() {
return null;
}
@Override
protected String getFallbackMethodName() {
return super.getFallbackMethodName();
}
}
请求合并:
Hystrix 多个请求被合并为一个请求进行一次性处理,可以有效减少网络通信和线程池资源。 请求合并之后 一个请求原本可能在 6 毫秒之内能够结 束, 现在必须等待请求合并周期后( I 0 毫秒)才能发送请求,增加了请求的时间 ( 16 毫 秒)。 但是请求合并在处理高并发和高延迟命令上效果极佳。
它提供两种方式进行请求合并 :
- request-scoped 收集一个 HystrixRequestContext 中的请求集合成一个批次;
- globally-scoped 将多个 HystrixRequestContext 中的请求集合成一个 批次,这需要应用的下游依赖能够支持在一个命令调用中处理多个 HystrixRequestContext
- 1.通过注解方式进行请求合:单个请求需要使用@HyStrixCollapser注解修饰,并指明batchMethod方法, 由于请求合并中不能同步等待结果,所以单个请求返回的 结果为 Future,即需要异步等待结果。
- 2. 继承 HystrixCol lapser
Hystrix 为 Spring Cloud 中微服务间的相互调用提供了强大的容错保护。 它通过将服务 调用者和服务提供者隔离的方式,在服务提供者失效的情况下,保护服务调用者的线程资 源,保证系统的整体稳定性,防止服务雪崩效应的发生。