python第三方库使用
1、geoip2库:MaxMind GeoIP2 Python API
作用:返回给出的ip地址的地理信息,包括所在国家、城市、经纬度等,有在线查询和离线查询(本地导入数据库)两种,具体使用参考上面的链接。
2、python第三方库的使用说明一般在:https://pypi.python.org/pypi/下上有其官方链接。
3、IPy库的使用:
(1)官方使用说明:https://pypi.python.org/pypi/IPy/
(2)IP(),当make_net设置为True时,会将给出的"IP地址/子网掩码"返回其网段;
即:>>> print(IP('127.0.0.1/255.0.0.0', make_net=True))
127.0.0.0/8
代码中的说明:“If make_net is True, an IP address will be transformed into the network address by applying the specified netmask.”
4、kafka的使用:
(1)、创建KafkaProducer实例时,传入的初始化参数ack可选值(0,1,“all”)的含义:
参数ack表示当有producer发送数据时,broker(kafka服务器)收到消息后什么时候给该producer发送确认,
0表示不需要发送确认,1表示在这个topic的follower中,只要有一个consumer收到了,broker就发送确认,all表示这个topic的所有follower都接收到后,broker才发送确认
5、MySQLdb:
(1).在MySQL中插入一条记录时,若字段类型为char,当sql语句使用format格式化时,相应字段名应该加单引号(' '),e.g:
insert_tb_sql = "INSERT INTO {table_date} (iType,sSrcIP,sTacticName,iAction,iNumPC,iNumMobile,iTotal,iDate,sMac,sOS) \
VALUES ({iType},'{ip}','{name}',{act},{pc},{mobile},{total},{date},'{mac}','{os}')"
(2).MySQLdb安装问题:
在win7 x64下使用pip安装MySQL的Python接口库,即mysql-python(安装后可在Python中导入MySQLdb)时,经常会报以下错误:

解决方法:
a.在https://www.lfd.uci.edu/~gohlke/pythonlibs/#mysql-python 下载mysqlclient的whl文件(根据安装的Python解释器为2.x还是3.x, 32位还是64位来下载);yongfja
b.终端切换到上面下载的文件所在路径,然后使用pip install mysqlclient-1.3.13-cp27-cp27m-win32.whl即可(Python 2.x)。
(3).解决importerror no module named mysqldb问题:
sudo apt-get install python-mysqldb
pip install mysql-python
6、user_agents:用于解析user_agent
如果要获取设备的user_agent,可以访问http://www.useragentstring.com/,获取具体当前设备的user_agent信息;
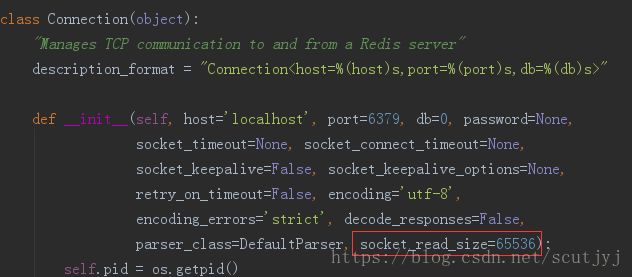
7、Python使用redis的api接口时,当使用StrictRedis实例的pubsub()方法得到一个PubSub类实例ps后,然后调用ps.subscribe()方法监听一个频道,再调用ps.getmessage()方法获取消息时,要注意每次读取消息的最大值默认为65536,如下图所示:


(2)redis的Python API接口使用的是select模型?
8、Python的redis库暂时不支持redis的集群连接方式(即redis客户端可以使用redis-cli -c [-p 端口号]以集群方式连接),如果redis以集群方式部署,且redis.StrictRedis实例连接的redis服务实例负责的槽(slot)不包含所要请求的key,则会抛出以下异常:

解决方法:
可以使用redis-py-cluster库解决,具体使用方法参考官方文档:redis-py-cluster document
9、sqlalchemy库:
简介:ORM工具,提供数据库访问接口(即使得具体使用的数据库对开发者透明,不管是使用sqlite,mysql还是postgresql,都可以使用同一行代码查询数据库),方便写数据库查询代码(即当不想使用mysqldb等数据库接口的cur.execute(sql语句)来访问数据库);
较好的使用总结:SqlAlchemy个人学习笔记完整汇总
具体使用参考官方文档:写的不怎么好的官方文档
其他参考:Flask系列教程(21)——SQLAlchemy的ORM(2),Flask-SQLALchemy基本使用
(1)sqlalchemy的commit和flush的区别:
flush会把更改提交到数据库,commit会默认调用flush,然后标志这个事务的提交,也就是事务执行完毕。如果只调用flush,那么更新虽然可以被写入数据库,但是事务是不完整的,没有提交。由于事务隔离型的存在,可能其他的事务是无法看到这次更新操作的。只有调用了commit,才能被看成是事务完整的执行完毕。
具体参考:【mysql】sqlalchemy commit 和 flush
(2)sqlalchemy的相关用法:
a、基本操作:Python操作MySQL之SQLAlchemy
b、字段值自增(类似于sql语句的:update tb set field = field + n;):How to update SQLAlchemy row entry?,How to increase a counter in SQLAlchemy
c、绑定多个数据库:绑定多个数据库
使用orm定义表对应的类时,如果没有使用__bind_key__指明该表对应的数据库,则改表默认使用的数据库为SQLALCHEMY_DATABASE_URL变量指定的数据库。
d、sqlalchemy返回值:
如果单表查询某几个字段,则返回包含多个tuple的列表,如果查询所有字段,则返回字典类型,如果联表查询,则返回一个列表,列表的元素为包含联结的表的对象的tuple;
>>querys=session.query(MdRecord.project_id, MdRecord.page_id).filter(MdRecord.record_date == record_date). \
filter(~MdRecord.project_id.in_(['', 'null', 'undefined']),
~MdRecord.page_id.in_(['', 'null', 'undefined'])
).all()
>> [('project_id', 'page_id')] # 返回值是一个list,里面是元组
e、groupby和count:
from sqlalchemy import func
session.query(Table.column, func.count(Table.column)).group_by(Table.column).all()
相关参考:Group by & count function in sqlalchemy
f、order_by和desc:
from sqlalchemy import desc
someselect.order_by(desc(table1.mycol))或者:
table1.mycol.desc()
相关参考:SQLAlchemy ORDER BY DESCENDING?
g、实现left join:
query = (session.query(Ip, func.count(Client.id)).
outerjoin(ClientIp, ClientIp.ip_id==Ip.id).
outerjoin(Client, Client.id==ClientIp.client_id).
group_by(Ip.id)
)具体参考:SQLAlchemy force Left Join
10、supervisor库的用法:使用 supervisor 管理进程
(1).常用的配置如下:
[program:test_hello]
user=test
command = docker run --rm --name %(program_name)s-%(process_num)02d -v /home/test/vhost/test_proj/tmp:/home/test_proj/tmp --network host --env APOLLO_ENV_URL=https://test-apollo:[email protected]/configfiles/json/myproject/test_machine/env --env SERVER_NAME=HEHE registry.test.com:443/proj/test:master celery_test worker -l INFO -c 3 -Q test_queue --without-heartbeat
directory=/home/test/vhost/test_proj
environment=PYTHONUNBUFFERD=1
process_name=%(program_name)s-%(process_num)02d
numprocs=1
autostart=true
autorestart=true
stopasgroup=true
killasgroup=true
redirect_stderr=true
stdout_logfile_maxbytes=100MB
stdout_logfile_backups=2
stdout_logfile=/home/test/log/supervisor/%(program_name)s-%(process_num)02d.log
(2).常用指令
# 启动/停止/重启进程
supervisorctl start/stop/restart test_hello
# 更新配置文件后使生效
supervisorctl update
# 重新启动配置中的所有进程
supervisorctl reload
# 查看服务
supervisorctl status {process_name}
# 停止所有进程
supervisorctl stop all(3).定义服务组
[group:test_hello_srv_group]
programs=test_hello-1,test_hello-211、virtualenv库相关:
virtualenv在同时配置了python2(默认python版本)和python3的环境下创建python3的虚拟环境:
virtualenv --python=$(which python3) envname相关参考:Using Python 3 in virtualenv
12、scrapy-redis和scrapy的区别:
具体参考:scrapy-redis 和 scrapy 有什么区别?
13、pillow库的使用:
(1)webp图片转为jpg
from PIL import Image
im = Image.open(file_path)
if im.mode=="RGBA":
im.load() # required for png.split()
background = Image.new("RGB", im.size, (255, 255, 255))
background.paste(im, mask=im.split()[3]) # 3 is the alpha channel
im = background
im.save('test.jpg','JPEG')(2)使用PIL获取图片的格式:
img = Image.open(filename)
print(img.format) # 'JPEG'(3)使用PIL处理图像时cannot write mode P as JPEG问题解决方法:
if img.mode == "P":
img = img.convert('RGB')相关参考:使用PIL模块存储图像时的报错:cannot write mode P as JPEG
14、requests库的使用
(1).使用requests库下载音频、视频等大型文件:
def download_file(url):
local_filename = url.split('/')[-1]
# NOTE the stream=True parameter below
with requests.get(url, stream=True) as r:
r.raise_for_status()
with open(local_filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=8192):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
# f.flush()
return local_filename相关参考:Download large file in python with requests
(2).requests处理3xx重定向:
>>> import requests
>>> r = requests.get('http://goo.gl/NZek5')
>>> r.history
(,)
>>> r.history[0].status_code
301
>>> r.history[0].headers['Location']
'http://docs.python-requests.org/en/latest/user/quickstart/'
>>> r.url
u'http://docs.python-requests.org/en/latest/user/quickstart/'
>>> r = requests.get('http://goo.gl/NZek5', allow_redirects=False)
>>> r.status_code
301
>>> r.url
u'http://goo.gl/NZek5' (3).requests库中文编码问题:代码分析Python requests库中文编码问题
(4).python3 requests库使用proxies时报"Caused by SSLError(SSLError("bad handshake: SysCallError(-1, 'Unexpected EOF')",),)"问题:
解决方法:加上verify=False,也即
resp = requests.get(url, headers=headers, proxies=proxies, verify=False)(5).requests库使用ip代理:
http_proxy = "http://10.10.1.10:3128"
https_proxy = "https://10.10.1.11:1080"
ftp_proxy = "ftp://10.10.1.10:3128"
proxyDict = {
"http" : http_proxy,
"https" : https_proxy,
"ftp" : ftp_proxy
}
r = requests.get(url, headers=headers, proxies=proxyDict)15.Scrapy
(1)scrapy的xpath使用正则表达式:
response.xpath('//ul/li/b[text()[re:test(., '^Name.*')]]/../descendant::text()') 16.BeautifulSoup
(1)只保留标签的某些属性:
可以参考:BeautifulSoup: Strip specified attributes, but preserve the tag and its contents
17.youtube_dl库
(1)如何只下载mp4格式的文件(即ext已经指定为mp4,但仍会下载到mkv格式问题)
解决方法:格式指定为“bestvideo[ext=mp4]+bestaudio[ext=m4a]/mp4”
18.peewee库(轻量级orm框架)
(1)join...on...的用法:
keywords = (
keyword_cls.select(keyword_cls.id, keyword_cls.result, keyword_rst_cls.app_num)
.join(
keyword_rst_cls,
JOIN.LEFT_OUTER,
on=(
(keyword_cls.id == keyword_rst_cls.keyword_id)
& (keyword_rst_cls.platform == PLATFORM_NUM_MAP[platform])
),
attr="keyword_app_num",
)
.where(keyword_cls.id > offset)
.order_by(keyword_cls.id.asc())
.limit(BATCH_GET_KEYWORD_LIMIT)
)
for keyword in keywords:
# 过滤搜索结果app_num=0的关键字
if not hasattr(keyword, "keyword_app_num") or keyword.keyword_app_num.app_num > 0:
pass
相关参考:How to pass multiple conditions to python peewee's join's on argument?
(2)in的用法
a_user_tweets = Tweet.select().where(Tweet.user.in_(a_users))(2)踩坑相关
a.对于MySQL orm中使用的属性名和表中字段名不一致时,复合主键的声明应使用属性名,而不是数据表字段名,否则insert数据的时候会报“object have no attribute”错误,代码参考如下:
class TestOrmModel(Model):
# 类属性名和字段名不一致.
appid = IntegerField(db_column="id")
version = CharField(db_column="app_version")
score = CharField(db_column="app_score")
class Meta:
table_name = "test_orm_model"
# 错误主键声明
primary_key = CompositeKey("appid", "app_version")
# 正确主键声明
primary_key = CompositeKey("appid", "version")建议:orm类属性名最好和表的字段名保持一致.
b.MySQL数据库表如果没有主键,peewee会默认给orm类加一个id字段,查询的时候会报错......
解决方法:orm类定义的class meta中加上primary_key = False
建议:一般设计MySQL都会设主键......
c.get_or_create方法,在插入时如果遇到unique key重复,会直接抛出异常,其实现代码如下:
@classmethod
def get_or_create(cls, **kwargs):
defaults = kwargs.pop('defaults', {})
query = cls.select()
for field, value in kwargs.items():
query = query.where(getattr(cls, field) == value)
try:
return query.get(), False
except cls.DoesNotExist:
try:
if defaults:
kwargs.update(defaults)
with cls._meta.database.atomic():
# 在执行create的时候,如果另一个进程同时执行该语句,且相应的sql对应的表有
# unique key的限制,则会进入异常处理
return cls.create(**kwargs), True
except IntegrityError as exc:
try:
# 如果此时另一进程的insert sql还没执行完,则会进入异常,进而get_or_create
# 这个函数直接抛出异常
return query.get(), False
except cls.DoesNotExist:
raise exc19、selenium使用相关
(1)翻页
SCROLL_PAUSE_TIME = 0.5
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down to bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height具体参考:How can I scroll a web page using selenium webdriver in python?
(2)创建headless浏览器(也即调用chromedriver的时候不会打开一个浏览器窗口)及常用配置
from selenium import webdriver
CHROME_REMOTE_HOST = "http://localhost:9515"
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_argument("enable-automation")
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-infobars")
options.add_argument("--disable-dev-shm-usage")
# options.add_argument("--disable-browser-side-navigation")
options.add_argument("--disable-gpu")
# chromeOptions.add_argument("--proxy-server="+PROXY)
# 可以连接远端服务器浏览器
browser = webdriver.Remote(CHROME_REMOTE_HOST, desired_capabilities=options.to_capabilities())
browser.set_page_load_timeout(20)
browser.get(url)20.pip相关使用
(1)某个库指定升级到某个版本
pip install --upgrade django==1.11.0相关参考:How can I upgrade specific packages using pip and a requirements file?