Python爬虫实战 | (7) 爬取万方数据库文献摘要
在本篇博客中,我们将爬取万方数据库,首先我们打开万方首页http://www.wanfangdata.com.cn:
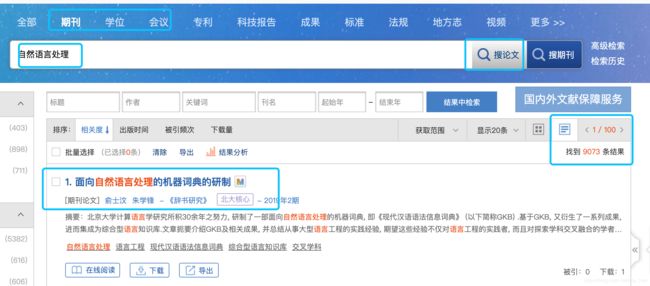
在搜索框中输入关键词,选择期刊、学位或会议,点击搜论文,并可得到与关键词相关的期刊、学位或会议论文,显示在下方,右上角是页数和搜索结果,默认一页20篇论文。
我们需要用爬虫来模拟上述操作,通过给定一个关键词,选择期刊、学位或会议,进行搜索,将搜索结果即论文的摘要、题目、作者等信息爬取下来。
首先,我们分析一下页面的URL:
1)当搜索类型为期刊时:http://www.wanfangdata.com.cn/search/searchList.do?searchType=perio&showType=detail&pageSize=20&searchWord=%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86&isTriggerTag=
2)当搜索类型为会议时:http://www.wanfangdata.com.cn/search/searchList.do?searchType=conference&showType=detail&pageSize=20&searchWord=%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86&isTriggerTag=
3)当搜索类型为学位时:http://www.wanfangdata.com.cn/search/searchList.do?searchType=degree&showType=detail&pageSize=20&searchWord=%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86&isTriggerTag=
通过观察URL,可以得出,searchType决定了搜索类型,perio代表期刊、conference代表会议、degree代表学位;pageSize=20代表默认一页显示20篇(这个不用修改);searchWord表示搜索的关键词用%十六进制的形式代表中文字符。
仅仅依靠上述可见的URL是不够的,我们还需要页数信息,现在万方数据库对这些信息都隐藏了,不过我们可以使用之前老版本的URL,虽然现在隐藏了,之前的URL还是可以用的。
1)当搜索类型为期刊时:http://www.wanfangdata.com.cn/search/searchList.do?beetlansyId=aysnsearch&searchType=conference&pageSize=20&page={}&searchWord={}&showType=detail&order=common_sort_time&isHit=&isHitUnit=&firstAuthor=false&navSearchType=conference&rangeParame=
2)当搜索类型为会议时:http://www.wanfangdata.com.cn/search/searchList.do?beetlansyId=aysnsearch&searchType=degree&pageSize=20&page={}&searchWord={}&showType=detail&order=pro_pub_date&isHit=&isHitUnit=&firstAuthor=false&navSearchType=degree&rangeParame=
3)当搜索类型为学位时:http://www.wanfangdata.com.cn/search/searchList.do?beetlansyId=aysnsearch&searchType=perio&pageSize=20&page={}&searchWord={}&showType=detail&order=orig_pub_date&isHit=&isHitUnit=&firstAuthor=false&navSearchType=perio&rangeParame=
page={}代表了页数信息,之后我们可以把爬取的页码填到{}中;searchWord={}代表搜索关键词,之后可以把关键词填到{}中;order代表对搜索结果进行排序,对于期刊按出版日期common_sort_time进行排序,对于会议按出版时间pro_pub_date进行排序,对于学位按学位授予时间orig_pub_date进行排序。URL的其他部分直接照搬就可以了。
首先我们要获取每个页面所有论文的url,下面是主程序的主体框架:
import re
import time
import requests
from requests import RequestException
def get_page(url):
pass
def get_url(html,type):
pass
def get_info(url,type):
pass
if __name__ == '__main__':
key_word = input('请输入搜索关键词:') #可以交互输入 也可以直接指定
type = input('请选择论文类型(p:期刊 c:会议 d:学位 ):')
#从哪一页开始爬 爬几页
start_page = int(input('请输入爬取的起始页:'))
page_num = int(input('请输入要爬取的页数(每页默认20条):'))
if type == 'c':
base_url = 'http://www.wanfangdata.com.cn/search/searchList.do?beetlansyId=aysnsearch&searchType=conference&pageSize=20&page={}&searchWord={}&showType=detail&order=common_sort_time&isHit=&isHitUnit=&firstAuthor=false&navSearchType=conference&rangeParame='
elif type == 'd':
base_url = 'http://www.wanfangdata.com.cn/search/searchList.do?beetlansyId=aysnsearch&searchType=degree&pageSize=20&page={}&searchWord={}&showType=detail&order=pro_pub_date&isHit=&isHitUnit=&firstAuthor=false&navSearchType=degree&rangeParame='
else:
base_url = 'http://www.wanfangdata.com.cn/search/searchList.do?beetlansyId=aysnsearch&searchType=perio&pageSize=20&page={}&searchWord={}&showType=detail&order=orig_pub_date&isHit=&isHitUnit=&firstAuthor=false&navSearchType=perio&rangeParame='
for page in range(int(start_page),int(start_page+page_num)):
new_url = base_url.format(page,key_word)
#爬取当前页面 发送请求、获取响应
html = get_page(new_url)
#解析响应 提取当前页面所有论文的url
url_list = get_url(html,type)
for url in url_list:
#获取每篇论文的详细信息
get_info(url,type)
time.sleep(2) #间隔2s发送请求、获取响应,爬取当前页面,编写get_page(url):
def get_page(url):
try:
# 添加User-Agent,放在headers中,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except RequestException as e:
print(e)
return None解析响应,获取当前页面所有论文的URL,编写get_url(html,type) 函数,不同type页面的论文URL有所不同,包含type信息。随便打开一篇论文,其URL如下:http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=D01662433。
其中type是类型信息,我们需要知道id,才能得到论文的URL,所以需要解析页面提取出每篇论文的id,再添加类型信息,与基础URL拼接即可:
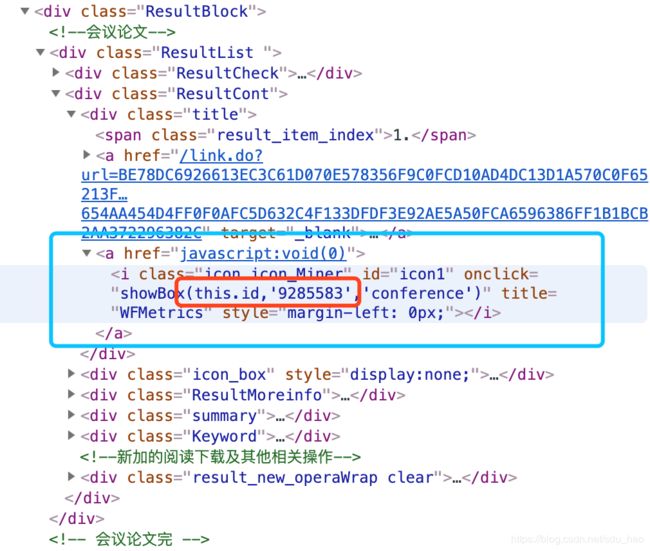
通过检查页面源码,发现每篇论文的id出现在上图的标签中。
def get_url(html,type):
url_list = []
pattern = re.compile("this.id,'(.*?)'",re.S)
ids = pattern.findall(html)
for id in ids:
if type == 'c':
url_list.append('http://www.wanfangdata.com.cn/details/detail.do?_type=conference&id='+id)
elif type == 'd':
url_list.append('http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=' + id)
else:
url_list.append('http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=' + id)
return url_list针对各种类型的论文url,分别写一个独立的.py文件,分别爬取:
def get_info(url,type):
if type == 'c':
conference.main(url)
elif type == 'd':
degree.main(url)
else:
perio.main(url)
conference.py,专门爬取会议论文的相关信息,程序主体框架如下:
import os
import re
import requests
import xlrd
import xlutils.copy
import xlwt
from bs4 import BeautifulSoup
from requests import RequestException
def get_html(url):
pass
def parse_html(html,url):
pass
def save_p(paper):
pass
def main(url):
#发送请求、获取响应
html = get_html(url)
#解析响应
paper = parse_html(html, url)
#数据存储
save_p(paper)发送请求,获取响应,编写get_html(url)函数:
def get_html(url):
try:
# 添加User-Agent,放在headers中,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
return None
except RequestException as e:
print(e)
return None使用beautifulSoup解析响应,提取论文的详细信息,编写parse_html(html,url)函数:
题目:

摘要:

关键词:

作者:

作者单位:

母体文献:

会议名称:

会议时间:

会议地点:

主办单位:
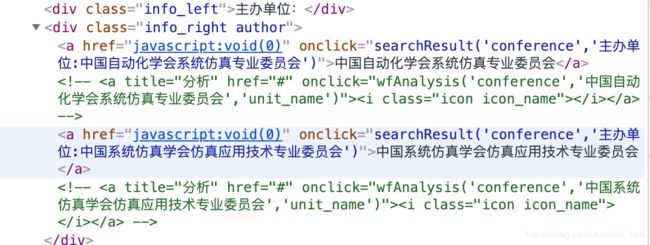
在线发表时间:

def parse_html(html,url):
#使用beautifulSoup进行解析
soup = BeautifulSoup(html,'lxml')
#题目
title = soup.select('[style="font-weight:bold;"]')[0].text
#摘要
abstract = soup.select('.abstract')[0].textarea
if abstract:
abstract = abstract.text.strip()
else:
abstract=''
#关键词
keyword = soup.select('[title="知识脉络分析"][href="#][onclick^="wfAnalysis"]') #返回列表 ^表示以什么开头 找到title=x,href=x,onclick=x的节点
keywords = ''
for word in keyword:
keywords = keywords + word.text + ';'
#作者
author = soup.select('[onclick^="authorHome"]')
if author:
author = author[0].text
#作者单位
unit = soup.select('[class^="unit_nameType"]')
if unit:
unit = unit[0].text
#母体文献
pattern = re.compile('母体文献.*?',re.S)
literature = re.findall(pattern, html)
if literature:
literature = literature[0]
print(literature)
#会议名称
conference = soup.select('[href="#"][onclick^="searchResult"]')[0].text
print(conference)
#会议时间
pattern = re.compile('会议时间.*?(.*?)', re.S)
date = pattern.findall(html)
if date:
date = date[0].strip()
# 会议地点
pattern = re.compile('会议地点.*?', re.S)
address = re.findall(pattern, html)
if address:
address = address[0].strip()
print(address)
# 主办单位
organizer = soup.select('[href="javascript:void(0)"][onclick^="searchResult"]')
if organizer:
organizer = organizer[0].text
print(organizer)
# 在线发表时间
pattern = re.compile('在线出版日期.*?', re.S)
online_date = pattern.findall(html)
if online_date:
online_date = online_date[0].strip()
paper = [title, abstract, keywords, author, unit, literature, conference, date, address, organizer, online_date,
url]
print(paper)
return paper存储结果(保存为excel文件):
def save_p(paper):
if not os.path.exists('会议论文.xls'):
wb = xlwt.Workbook()
sheet = wb.add_sheet('sheet1')
title = ['题目', '摘要', '关键词', '作者', '作者单位', '母体文献', '会议名称', '会议时间', '会议地点', '主办单位', '在线发表时间', '链接']
for i in range(len(title)):
sheet.write(0, i, title[i]) #在第0行写入标题
wb.save('会议论文.xls')
wb = xlrd.open_workbook('会议论文.xls')
sheet = wb.sheet_by_index(0)
rows = sheet.nrows #当前行数
print(rows)
ws = xlutils.copy.copy(wb)
sheet = ws.get_sheet(0)
for i in range(len(paper)):
sheet.write(rows, i, paper[i])
ws.save('会议论文.xls')
其他期刊论文、学位论文的爬取都是类似的,不再赘述,可以运行一遍,对照网页源码,看看如何使用BeautifulSoup、XPath、正则表达式对其进行解析。
完整代码