Lucene入门与深入代码
1、Lucene简介
①Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
②Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
③Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
④在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。[1]
2、Lucene创始人
Lucene['lusen]的原作者是Doug Cutting,他是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后在Excite担任高级系统架构设计师,当前从事于一些Internet底层架构的研究。早先发布在作者自己的博客上,他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。后来发布在SourceForge,2001年年底成为apache软件基金会jakarta的一个子项目。
3、Lucene特点优势
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。
Lucene是一个高性能、可伸缩的信息搜索(IR)库。它可以为你的应用程序添加索引和搜索能力。Lucene是用java实现的、成熟的开源项目,是著名的Apache Jakarta大家庭的一员,并且基于Apache软件许可 [ASF, License]。同样,Lucene是当前非常流行的、免费的Java信息搜索(IR)库
4、Lucene突出的优点
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即可使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势。
首先,它的开发源代码发行方式(遵守Apache Software License[12]),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面向对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。
最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework[14]),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选择。
5、Lucene前提
lucene有7个包需要导入:analysis,document,index,queryParser,search,store,util
6、lucene核心知识点
lucene用到一些概念,了解它们的含义,有利于下面的讲解。
3.2 Analyzer
Analyzer 是分析器,它的作用是把一个字符串按某种规则划分成一个个词语,并去除其中的无效词语,这里说的无效词语是指英文中的“of”、“the”,中文中的 “的”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率。
分词的规则千变万化,但目的只有一个:按语义划分。这点在英文中比较容易实现,因为英文本身就是以单词为单位的,已经用空格分开;而中文则必须以某种方法将连成一片的句子划分成一个个词语。具体划分方法下面再详细介绍,这里只需了解分析器的概念即可。
3.2 document
用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document的形式存储在索引文件中的。用户进行搜索,也是以Document列表的形式返回。
3.3 field
一个Document可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过Field在Document中存储的。
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要,下面举例说明:
还是以刚才的文章为例子,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为真,同时我们希望能直接从搜索结果中提取文章标题,所以 我们把标题域的存储属性设置为真,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域的存储属性设置为假,当需要时再直接读取文件;我们只是希望 能从搜索解果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域的存储属性设置为真,索引属性设置为假。上面的三个域涵盖了两个属性的三 种组合,还有一种全为假的没有用到,事实上Field不允许你那么设置,因为既不存储又不索引的域是没有意义的。
3.4 term
term是搜索的最小单位,它表示文档的一个词语,term由两部分组成:它表示的词语和这个词语所出现的field。
3.5 tocken
tocken是term的一次出现,它包含trem文本和相应的起止偏移,以及一个类型字符串。一句话中可以出现多次相同的词语,它们都用同一个term表示,但是用不同的tocken,每个tocken标记该词语出现的地方。
3.6 segment (段)
添加索引时并不是每个document都马上添加到同一个索引文件,它们首先被写入到不同的小文件,然后再合并成一个大索引文件,这里每个小文件都是一个segment。
7、lucene的结构
lucene包括core和sandbox两部分,其中core是lucene稳定的核心部分,sandbox包含了一些附加功能,例如highlighter、各种分析器。
Lucene core有七个包:analysis,document,index,queryParser,search,store,util。
4.1 analysis
Analysis包含一些内建的分析器,例如按空白字符分词的WhitespaceAnalyzer,添加了stopwrod过滤的StopAnalyzer,最常用的StandardAnalyzer。
4.2 document
Document包含文档的数据结构,例如Document类定义了存储文档的数据结构,Field类定义了Document的一个域。
4.3 index
Index 包含了索引的读写类,例如对索引文件的segment进行写、合并、优化的IndexWriter类和对索引进行读取和删除操作的 IndexReader类,这里要注意的是不要被IndexReader这个名字误导,以为它是索引文件的读取类,实际上删除索引也是由它完成, IndexWriter只关心如何将索引写入一个个segment,并将它们合并优化;IndexReader则关注索引文件中各个文档的组织形式。
4.4 queryParser
QueryParser 包含了解析查询语句的类,lucene的查询语句和sql语句有点类似,有各种保留字,按照一定的语法可以组成各种查询。 Lucene有很多种 Query类,它们都继承自Query,执行各种特殊的查询,QueryParser的作用就是解析查询语句,按顺序调用各种 Query类查找出结果。
4.5 search
Search包含了从索引中搜索结果的各种类,例如刚才说的各种Query类,包括TermQuery、BooleanQuery等就在这个包里。
4.6 store
Store包含了索引的存储类,例如Directory定义了索引文件的存储结构,FSDirectory为存储在文件中的索引,RAMDirectory为存储在内存中的索引,MmapDirectory为使用内存映射的索引。
4.7 util
Util包含一些公共工具类,例如时间和字符串之间的转换工具
8、学习流程
1、
添加文档
删除文档
修改文档
文档域加权
2、
对特定项搜索
查询表达式:QueryParser
其他查询方式:
指定项范围查询 TermRangeQuery ;
指定数字范围查询 NumericRangeQuery ;
指定字符串开头搜索 PrefixQuery ;
组合查询 BooleanQuery ;
3、
中文分词 smartcn
检索结果高亮显示实现
9、Lucene的评分概念
通过Searcher.explain(Query query, int doc)方法可以查看某个文档的得分的具体构成。
在Lucene中score简单说是由 tf * idf * boost * lengthNorm计算得出的。
tf:是查询的词在文档中出现的次数的平方根
idf:表示反转文档频率,观察了一下所有的文档都一样,所以那就没什么用处,不会起什么决定作用。
boost:激励因子,可以通过setBoost方法设置,需要说明的通过field和doc都可以设置,所设置的值会同时起作用
lengthNorm:是由搜索的field的长度决定了,越长文档的分值越低。
所以我们编程能够控制score的就是设置boost值。
还有个问题,为什么一次查询后最大的分值总是1.0呢?
因为Lucene会把计算后,最大分值超过1.0的分值作为分母,其他的文档的分值都除以这个最大值,计算出最终的得分。
下面用代码和运行结果来进行说明:
Java代码
1. public class ScoreSortTest {
2.
2. public final static String INDEX_STORE_PATH = “index”;
3. public static void main(String[] args) throws Exception {
4. IndexWriter writer = new IndexWriter(INDEX_STORE_PATH, new StandardAnalyzer(), true);
5. writer.setUseCompoundFile(false);
6.
7. Document doc1 = new Document();
8. Document doc2 = new Document();
9. Document doc3 = new Document();
10.
11. Field f1 = new Field(“bookname”,”bc bc”, Field.Store.YES, Field.Index.TOKENIZED);
12. Field f2 = new Field(“bookname”,”ab bc”, Field.Store.YES, Field.Index.TOKENIZED);
13. Field f3 = new Field(“bookname”,”ab bc cd”, Field.Store.YES, Field.Index.TOKENIZED);
14.
15. doc1.add(f1);
16. doc2.add(f2);
17. doc3.add(f3);
18.
19. writer.addDocument(doc1);
20. writer.addDocument(doc2);
21. writer.addDocument(doc3);
22.
23. writer.close();
24.
25. IndexSearcher searcher = new IndexSearcher(INDEX_STORE_PATH);
26. TermQuery q = new TermQuery(new Term(“bookname”, “bc”));
27. q.setBoost(2f);
28. Hits hits = searcher.search(q);
29. for(int i=0; i
10、Lucene生成文件简述
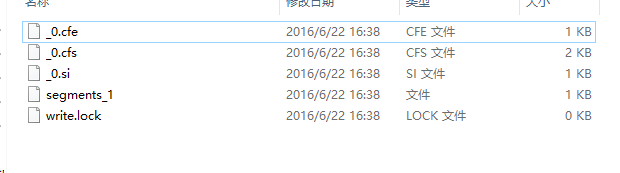
一、基本概念
下图就是Lucene生成的索引的一个实例:
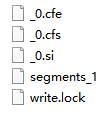
Lucene的索引结构是有层次结构的,主要分以下几个层次:
索引(Index):
①在Lucene中一个索引是放在一个文件夹中的。
段(Segment):
①一个索引可以包含多个段,段与段之间是独立的,添加新文档可以 生 成新的段,不同的段可以合并。
②如上图,具有相同前缀文件的属同一个段,图中共两个段 “_0” 和 “_1”。
③segments.gen和segments_5是段的元数据文件,也即它们保存了段的属性信息。
文档(Document):
①文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。
②新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
域(Field):
①一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,作者等,都可以保存在不同的域里。
词(Term):
①词是索引的最小单位,是经过词法分析和语言处理后的字符串。
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
所谓正向信息:
按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。
既然是层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息,也即属性信息,比如一本介绍中国地理的书,应该首先介绍中国地理的概况, 以及中国包含多少个省,每个省介绍本省的基本概况及包含多少个市,每个市介绍本市的基本概况及包含多少个县,每个县具体介绍每个县的具体情况。
如上图,包含正向信息的文件有:
①segments_N保存了此索引包含多少个段,每个段包含多少篇文档。
②XXX.fnm保存了此段包含了多少个域,每个域的名称及索引方式。
③XXX.fdx,XXX.fdt保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
④XXX.tvx,XXX.tvd,XXX.tvf保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
所谓反向信息:
保存了词典到倒排表的映射:词(Term) –> 文档(Document)
如上图,包含反向信息的文件有:
①XXX.tis,XXX.tii保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。
②XXX.frq保存了倒排表,也即包含每个词的文档ID列表。
③XXX.prx保存了倒排表中每个词在包含此词的文档中的位置。
在了解Lucene索引的详细结构之前,先看看Lucene索引中的基本数据类型。
想详细了解,请复制网址:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623597.html
11、倒排索引相关概念及定义代码
一、倒排索引概述
在关系数据库系统里,索引[1] 是检索数据最有效率的方式,。但对于搜索引擎,它并不能满足其特殊要求:
1)海量数据:搜索引擎面对的是海量数据,像Google,百度这样大型的商业搜索引擎索引都是亿级甚至百亿级的网页数量 ,面对如此海量数据 ,使得数据库系统很难有效的管理。
2)数据操作简单:搜索引擎使用的数据操作简单 ,一般而言 ,只需要增、 删、 改、 查几个功能 ,而且数据都有特定的格式 ,可以针对这些应用设计出简单高效的应用程序。而一般的数据库系统则支持大而全的功能 ,同时损失了速度和空间。最后 ,搜索引擎面临大量的用户检索需求 ,这要求搜索引擎在检索程序的设计上要分秒必争 ,尽可能的将大运算量的工作在索引建立时完成 ,使检索运算尽量的少。一般的数据库系统很难承受如此大量的用户请求 ,而且在检索响应时间和检索并发度上都不及我们专门设计的索引系统。
二、倒排索引相关概念及定义
倒排索引倒排列表
倒排列表用来记录有哪些文档包含了某个单词。一般在文档集合里会有很多文档包含某个单词,每个文档会记录文档编号(DocID),单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现过等信息,这样与一个文档相关的信息被称做倒排索引项(Posting),包含这个单词的一系列倒排索引项形成了列表结构,这就是某个单词对应的倒排列表。右图是倒排列表的示意图,在文档集合中出现过的所有单词及其对应的倒排列表组成了倒排索引。
在实际的搜索引擎系统中,并不存储倒排索引项中的实际文档编号,而是代之以文档编号差值(D-Gap)。文档编号差值是倒排列表中相邻的两个倒排索引项文档编号的差值,一般在索引构建过程中,可以保证倒排列表中后面出现的文档编号大于之前出现的文档编号,所以文档编号差值总是大于0的整数。如图2所示的例子中,原始的 3个文档编号分别是187、196和199,通过编号差值计算,在实际存储的时候就转化成了:187、9、3。
之所以要对文档编号进行差值计算,主要原因是为了更好地对数据进行压缩,原始文档编号一般都是大数值,通过差值计算,就有效地将大数值转换为了小数值,而这有助于增加数据的压缩率。
倒排索引倒排索引
倒排索引[2] (英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
三、倒排索引
倒排索引[2] 有两种不同的反向索引形式:
一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
后者的形式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建。
现代搜索引擎的索引[3] 都是基于倒排索引。相比“签名文件”、“后缀树”等索引结构,“倒排索引”是实现单词到文档映射关系的最佳实现方式和最有效的索引结构.
四、倒排索引构建方法
倒排索引简单法
索引的构建[4] 相当于从正排表到倒排表的建立过程。当我们分析完网页时 ,得到的是以网页为主码的索引表。当索引建立完成后 ,应得到倒排表 ,具体流程如图所示:
流程描述如下:
1)将文档分析称单词term标记,
2)使用hash去重单词term
3)对单词生成倒排列表
倒排列表就是文档编号DocID,没有包含其他的信息(如词频,单词位置等),这就是简单的索引。
这个简单索引功能可以用于小数据,例如索引几千个文档。然而它有两点限制:
1)需要有足够的内存来存储倒排表,对于搜索引擎来说, 都是G级别数据,特别是当规模不断扩大时 ,我们根本不可能提供这么多的内存。
2)算法是顺序执行,不便于并行处理。
五、倒排索引合并法:
归并法[4] ,即每次将内存中数据写入磁盘时,包括词典在内的所有中间结果信息都被写入磁盘,这样内存所有内容都可以被清空,后续建立索引可以使用全部的定额内存。
六、归并索引 :
合并流程:
1)页面分析,生成临时倒排数据索引A,B,当临时倒排数据索引A,B占满内存后,将内存索引A,B写入临时文件生成临时倒排文件,
2) 对生成的多个临时倒排文件 ,执行多路归并 ,输出得到最终的倒排文件 ( inverted file)。
合并流程
索引创建过程中的页面分析 ,特别是中文分词为主要时间开销。算法的第二步相对很快。这样创建算法的优化集中在中文分词效率上。
七、倒排索引更新策略:
更新策略有四种 :完全重建、再合并策略、原地更新策略以及混合策略。①完全重建策略:当新增文档到达一定数量,将新增文档和原先的老文档整合,然后利用静态索引创建方法对所有文档重建索引,新索引建立完成后老索引会被遗弃。此法代价高,但是主流商业搜索引擎一般是采用此方式来维护索引的更新(这句话是书中原话)
②再合并策略:当新增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排表列表末尾追加倒排表列表项;一旦临时索引将指定内存消耗光,即进行一次索引合并,这里需要倒排文件里的倒排列表存放顺序已经按照索引单词字典顺序由低到高排序,这样直接顺序扫描合并即可。其缺点是:因为要生成新的倒排索引文件,所以对老索引中的很多单词,尽管其在倒排列表并未发生任何变化,也需要将其从老索引中取出来并写入新索引中,这样对磁盘消耗是没必要的。
③原地更新策略:试图改进再合并策略,在原地合并倒排表,这需要提前分配一定的空间给未来插入,如果提前分配的空间不够了需要迁移。实际显示,其索引更新的效率比再合并策略要低。
④混合策略:出发点是能够结合不同索引更新策略的长处,将不同索引更新策略混合,以形成更高效的方法。
12、关于stopword的简述
在中文网站里面其实也存在大量的stop word。比如,我们前面这句话,“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。原本可以添加一个关键词,排名就可以上升一名的,为什么不留着添加为关键词呢?停止词对SEO的意义不是越多越好,而是尽量的减少为宜。
既然问的是stop words, 我想主要是针对英文吧,也叫common words,(Stop Words. Most Search Engines do not consider extremely common words in order to save disk space or to speed up search results.) google中提出的stop words的概念是把一些对短语表述不构成直接影响的单词的的搜索结果直接过滤掉,包括a,an,the等冠词,in, at, of等介词, 一些人称代词,时态的助动词等,如果需要我这有一个停止词的大概列表可以发到你邮箱,这些词应为使用频率过高,所以搜索引擎把这些词的搜索结果会直接过滤掉,针对seo的话,这些词尽量少用较好,但如果不用对原来意思造成比较大的歪曲的话还是坚持使用吧,毕竟写的东西搜索只是抓取,最后看内容的还是人类。
13、代码
//首先创建maven项目,建包省略。直接pom.xml文件代码
//maven里的pom.xml配置代码
junit
junit
3.8.1
test
org.apache.lucene
lucene-core
5.3.1
org.apache.lucene
lucene-queryparser
5.3.1
org.apache.lucene
lucene-analyzers-common
5.3.1
org.apache.lucene
lucene-analyzers-smartcn
5.3.1
org.apache.lucene
lucene-highlighter
5.3.1
//**start*******1、向文档写索引以及根据索引读取*************
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* 类简介:
* ①简单的向文档里写索引;
* ②在根据索引读取文档;
* ③运用路径来找被索引的文档,找到返回结果
*/
public class Indexer {
//写索引的实例到指定目录下
private IndexWriter writer;
/**
* 构造方法:为了实例化IndexWriter
*/
public Indexer(String indexDir) throws Exception{
//得到索引所在目录的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
//实例化分析器
Analyzer analyzer = new StandardAnalyzer();
//实例化IndexWriterConfig
IndexWriterConfig con = new IndexWriterConfig(analyzer);
//实例化IndexWriter
writer = new IndexWriter(dir, con);
}
/**
* 关闭写索引
* @throws Exception
*/
public void close()throws Exception{
writer.close();
}
/**
* 索引指定目录的所有文件
* @throws Exception
*/
public int index(String dataDir) throws Exception{
//定义文件数组,循环得出要加索引的文件
File[] file = new File(dataDir).listFiles();
for (File files : file) {
//从这开始,对每个文件加索引
indexFile(files);
}
//返回索引了多少个文件,有几个文件返回几个
return writer.numDocs();
}
/**
* 索引指定文件
* @throws Exception
*/
private void indexFile(File files) throws Exception {
System.out.println("索引文件:"+files.getCanonicalPath());
//索引要一行一行的找,,在数据中为文档,所以要得到所有行,即文档
Document document = getDocument(files);
//开始写入,就把文档写进了索引文件里去了;
writer.addDocument(document);
}
/**
* 获得文档,在文档里在设置三个字段
*
* 获得文档,相当于数据库里的一行
* @throws Exception
* */
private Document getDocument(File files) throws Exception {
//实例化Document
Document doc = new Document();
doc.add(new TextField("contents",new FileReader(files)));
//Field.Store.YES:把文件名存索引文件里,为NO就说明不需要加到索引文件里去
doc.add(new TextField("FileName", files.getName(), Field.Store.YES));
//把完整路径存在索引文件里
doc.add(new TextField("fullPath", files.getCanonicalPath(),Field.Store.YES));
//返回document
return doc;
}
//开始测试写入索引
public static void main(String[] args){
//索引指定的文档路径
String indexDir = "E:\\luceneDemo";
//被索引数据的路径
String dataDir = "E:\\luceneDemo\\data";
//写索引
Indexer indexer = null;
int numIndex = 0;
//索引开始时间
long start = System.currentTimeMillis();
try {
//通过索引指定的路径,得到indexer
indexer = new Indexer(indexDir);
//将要索引的数据路径(int:因为这是要索引的数据,有多少就返回多少数量的索引文件)
numIndex = indexer.index(dataDir);
} catch (Exception e) {
e.printStackTrace();
}
//索引结束时间
long end = System.currentTimeMillis();
//显示结果
System.out.println("索引了 "+numIndex+" 个文件,花费了 "+(end-start)+" 毫秒");
}
}
//以下就是根据索引读取的代码:
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
*
* 通过索引字段来读取文档
* @author SZQ
*
*/
public class ReaderByIndexerTest {
public static void search(String indexDir,String q)throws Exception{
//得到读取索引文件的路径
Directory dir=FSDirectory.open(Paths.get(indexDir));
//通过dir得到的路径下的所有的文件
IndexReader reader=DirectoryReader.open(dir);
//建立索引查询器
IndexSearcher is=new IndexSearcher(reader);
//实例化分析器
Analyzer analyzer=new StandardAnalyzer();
//建立查询解析器
/**
* 第一个参数是要查询的字段;
* 第二个参数是分析器Analyzer
* */
QueryParser parser=new QueryParser("contents", analyzer);
//根据传进来的p查找
Query query=parser.parse(q);
//计算索引开始时间
long start=System.currentTimeMillis();
//开始查询
/**
* 第一个参数是通过传过来的参数来查找得到的query;
* 第二个参数是要出查询的行数
* */
TopDocs hits=is.search(query, 10);
//计算索引结束时间
long end=System.currentTimeMillis();
System.out.println("匹配 "+q+" ,总共花费"+(end-start)+"毫秒"+"查询到"+hits.totalHits+"个记录");
//遍历hits.scoreDocs,得到scoreDoc
/**
* ScoreDoc:得分文档,即得到文档
* scoreDocs:代表的是topDocs这个文档数组
* @throws Exception
* */
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=is.doc(scoreDoc.doc);
System.out.println(doc.get("fullPath"));
}
//关闭reader
reader.close();
}
//测试
public static void main(String[] args) {
String indexDir="E:\\luceneDemo";
String q="Zygmunt Saloni";
try {
search(indexDir,q);
//**end*******1、向文档写索引以及根据索引读取*************图片为写完索引的显示效果为:见以下代码,说明索引成功!

但是注意的是,在每次重新访问的时候,都要把文件夹下所产生的文件删除,否则会索引文件重复。
图片为根据索引的显示效果为:见以下代码,说明检索成功!

下面就开始为对索引文件的CRUD。
代码演示:
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
/**
* 对被索引的文章进行crud
* @author SZQ
*
*/
public class IndexDocument {
//写测试数据,这些数据是写到索引文档里去的。
private String ids[] = {"1","2","3"}; //标示文档
private String citys[] = {"BeiJing","HeBei","ShanXi"};
private String cityDes[] = {
"BeiJing is the captial of China!",
"HeBei is my hometown!",
"ShanXi is a beautiful city!"
};
private Directory dir;
//每次启动的时候都会执行这个方法,写索引的东西都写在setUp方法里
@Before
public void setUp() throws Exception {
//得到读取索引文件的路径
dir = FSDirectory.open(Paths.get("E:\\luceneDemo2"));
//获取IndexWriter实例
IndexWriter writer = getWriter();
for(int i=0;inew Document();
doc.add(new StringField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city",citys[i],Field.Store.YES));
doc.add(new TextField("desc", cityDes[i], Field.Store.NO));
// 添加文档
writer.addDocument(doc);
}
writer.close();
}
/**
* 获取IndexWriter实例
* @return
* @throws Exception
*/
private IndexWriter getWriter() throws Exception{
//实例化分析器
Analyzer analyzer = new StandardAnalyzer();
//实例化IndexWriterConfig
IndexWriterConfig con = new IndexWriterConfig(analyzer);
//实例化IndexWriter
IndexWriter writer = new IndexWriter(dir, con);
return writer;
}
/**
* 测试写了几个文档(对应图片一)
* @throws Exception
*/
@Test
public void testIndexWriter()throws Exception{
//获取IndexWriter实例
IndexWriter writer=getWriter();
System.out.println("写入了"+writer.numDocs()+"个文档");
//关闭writer
writer.close();
}
/**
* 测试读取文档(对应图片二)
* @throws Exception
*/
@Test
public void testIndexReader()throws Exception{
//根据路径得到索引读取
IndexReader reader=DirectoryReader.open(dir);
//公共是多少文件,也就是最大文档数
System.out.println("最大文档数:"+reader.maxDoc());
//读取的实际文档数
System.out.println("实际文档数:"+reader.numDocs());
//关闭reader
reader.close();
}
/**
* 测试删除 在合并前(对应图片三)
* @throws Exception
*/
@Test
public void testDeleteBeforeMerge()throws Exception{
//获取IndexWriter实例
IndexWriter writer=getWriter();
//统计删除前的文档数
System.out.println("删除前:"+writer.numDocs());
//Term:第一个参数是删除的条件,第二个是删除的条件值
writer.deleteDocuments(new Term("id","1"));
//提交writer(如果不提交,就不能删除)
writer.commit();
//显示删除在合并前的最大文档数量
System.out.println("writer.maxDoc():"+writer.maxDoc());
//显示删除在合并前的实际数量
System.out.println("writer.numDocs():"+writer.numDocs());
//关闭writer
writer.close();
}
/**
* 测试删除 在合并后(对应图片四)
* @throws Exception
*/
@Test
public void testDeleteAfterMerge()throws Exception{
//获取IndexWriter实例
IndexWriter writer=getWriter();
//删除前的文档数
System.out.println("删除前:"+writer.numDocs());
//Term:第一个参数是删除的条件,第二个是删除的条件值
writer.deleteDocuments(new Term("id","1"));
// 强制删除
writer.forceMergeDeletes();
//提交writer
writer.commit();
//显示删除在合并后的最大文档数量
System.out.println("writer.maxDoc():"+writer.maxDoc());
//显示删除在合并后的实际数量
System.out.println("writer.numDocs():"+writer.numDocs());
//关闭writer
writer.close();
}
/**
* 测试更新(对应图片五)
* @throws Exception
*/
@Test
public void testUpdate()throws Exception{
//获取IndexWriter实例
IndexWriter writer=getWriter();
//实例化文档
Document doc=new Document();
//向文档里添加值
doc.add(new StringField("id", "1", Field.Store.YES));
doc.add(new StringField("city","qingdao",Field.Store.YES));
doc.add(new TextField("desc", "dsss is a city.", Field.Store.NO));
//更新文档
/**
* 第一个参数是根据id为1的更新文档,,
* 第二个是更改的内容
*
* 过程:先把查到的文档删掉,再添加。这就是更新。但是原来的数据还在;
*/
writer.updateDocument(new Term("id","1"), doc);
//关闭writer
writer.close();
}
} 图片一:出现图一,就说明检索文件成功!
图片二:首先来解释一下是什么是最大文件数:指的是你一共索引了多少的文档,写了7个,就是7个,写了3个就是3个。实际文档数是真正3个被索引的文档。值得注意的是,检索文件之后,手动删除图一当中的所有文件,否则会查出重复的文档数。因为在读取文档数的时候,相当于又重新对文档写了索引。

在这可能大家对什么是 在合并前和在合并后起了疑问,那么就来看一下图片 对比一下,就知道了:
合并前:
图片三:

合并后:
图片四:

细心的你可能已发现,在删除合并之前,删除前为3,最大文档数为 3;而合并后的图片四中删除前仍为3,但是最大文档数为 2.这说明了这两幅图都已删除成功,但是图片三没有真正的把删除文档,但实际文档数是代表已经删除了一个文档。
合并前在luke中显示的效果:

相反,图片四不管是最大文档数还是实际文档数都是2,更能看出已经强制删除了一个文档,合并后在luke中显示的效果:
所以,个人觉得,合并后是比较准确,直观的看出确实是删除了文档。
好了,,这就是对被索引文档的一个CRUD。还有一个工具还没给大家介绍,那就是Luke。那么什么是Luke呢?
复制url:http://www.getopt.org/luke/,说白了就是lucene全文检索的第三方工具,效果如下:

luke使用步骤:
步骤一:解压luke-5.3.0-luke-release.zip;
步骤二:双击luke.bat,出现如上图的效果(左下角的
空白处和右下角的空白处没有东西);
步骤三:点击左上角的FIle,看见Open Lucene Index这
个 选项,点击之后,就会出现你的路径,选
择索引文档所在文件夹的全路径就可以了。
最后的效果就和上图一模一样了。
但是你的jDK必须为1.7或1.8以上,否则会用不了。
好了,开始代码展示对被索引文档加权
补充:
在进入学习之前。先给大家介绍一下,什么是加权?
加权就是有时在搜索的时候,会根据需要的不同,对不同的关键值或者不同的关键索引分配不同的权值,让权值高的内容更容易被用户搜索出来,而且排在前面。
为索引域添加权是再创建索引之前,把索引域的权值设置好,这样,在进行搜索时,lucene会对文档进行评分,这个评分机制是跟权值有关的,而且其它情况相同时,权值跟评分是成正相关的。
也就是说,给谁加权,就会给谁评分,评分越高,就越排在最前面。
那么问题又来了,评分是啥呢?评分就是信息过滤,让用户快速,准确的找到其想要的结果,丰富用户体验。下图为计算公式:
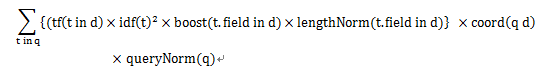
q为查询语句,t是q分词后的每一项,d为去匹配的文档。
打分流程:http://www.360doc.com/content/13/0426/20/891660_281142154.shtml
java代码如下:
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
/**
* 文档加权
*
* 1、加权操作:给要迅速查找的东西加上权,可提升查找速度!
*
*/
public class AddDocumentReg {
//写测试数据,这些数据是写到索引文档里去的。
private String ids[] = {"1","2","3","4"}; //标示文档
private String author[] = {"Jack","Mary","Jerry","Machech"};
private String title[] = {"java of china","Apple of china","Androw of apple the USA","People of Apple java"}; //
private String contents[] = {
"java of China!the world the why what",
"why a dertity compante is my hometown!",
"Jdekia ssde hhh is a beautiful city!",
"Jdekia ssde hhh is a beautiful java!"
};
private Directory dir;
/**
* 获取IndexWriter实例
* @return
* @throws Exception
*/
private IndexWriter getWriter()throws Exception{
//实例化分析器
Analyzer analyzer = new StandardAnalyzer();
//实例化IndexWriterConfig
IndexWriterConfig con = new IndexWriterConfig(analyzer);
//实例化IndexWriter
IndexWriter writer = new IndexWriter(dir, con);
return writer;
}
/**
* 生成索引(对应图一)
* @throws Exception
*/
@Test
public void index()throws Exception{
dir=FSDirectory.open(Paths.get("E:\\luceneDemo3"));
IndexWriter writer=getWriter();
for(int i=0;inew Document();
doc.add(new StringField("id", ids[i], Field.Store.YES));
doc.add(new StringField("author", author[i], Field.Store.YES));
// 加权操作
TextField field=new TextField("title", title[i], Field.Store.YES);
if("Mary".equals(author[i])){
//设权 默认为1
field.setBoost(1.5f);
}
doc.add(field);
doc.add(new StringField("contents",contents[i],Field.Store.NO));
// 添加文档
writer.addDocument(doc);
}
//关闭writer
writer.close();
}
/**
* 查询(对应图二)
* @throws Exception
*/
@Test
public void search()throws Exception{
//得到读取索引文件的路径
dir = FSDirectory.open(Paths.get("E:\\luceneDemo3"));
//通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
//建立索引查询器
IndexSearcher searcher = new IndexSearcher(reader);
//查找的范围
String searchField = "title";
//查找的字段
String q = "apple";
//运用term来查找
Term t = new Term(searchField,q);
//通过term得到query对象
Query query = new TermQuery(t);
//获得查询的hits
TopDocs hits = searcher.search(query, 10);
//显示结果
System.out.println("匹配 '"+q+"',总共查询到"+hits.totalHits+"个文档");
//循环得到文档,得到文档就可以得到数据
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=searcher.doc(scoreDoc.doc);
System.out.println(doc.get("author"));
}
//关闭reader
reader.close();
}
} 图一:见下图说明索引成功!

图二:

代码中匹配的是:apple,4个文档里3个都有,验证一下到底是不是呢?看下图:

大家看 author的这个数组,Mary、Jerry、Machech 对应的title 是不是有apple这个关键字。而且是不区分大小写的。什么它就是把索引为title的查出来了,为什么不差别的呢?这是因为在代码中,有 注释为 “//查找的范围” 的代码:String searchField = “title”;因为它规定了只在索引为title范围里找符合条件的元素。当然换成别的也是可以实现的。
接下来的代码是 学习Lucene对索引文档的特定项搜索
代码如下:
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* 对特定项搜索
*/
//先对文档进行索引
public class Indexer {
//写索引的实例到指定目录下
private IndexWriter writer;
/**
* 构造方法:为了实例化IndexWriter
*/
private Indexer(String indexDir) throws Exception{
//得到索引所在目录的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
//实例化分析器
Analyzer analyzer = new StandardAnalyzer();
//实例化IndexWriterConfig
IndexWriterConfig con = new IndexWriterConfig(analyzer);
//实例化IndexWriter
writer = new IndexWriter(dir, con);
}
/**
* 关闭写索引
* @throws Exception
*/
public void close()throws Exception{
writer.close();
}
/**
* 索引指定目录的所有文件
* @throws Exception
*/
public int index(String dataDir) throws Exception{
//定义文件数组,循环得出要加索引的文件
File[] file = new File(dataDir).listFiles();
for (File files : file) {
//从这开始,对每个文件加索引
indexFile(files);
}
//返回索引了多少个文件,有几个文件返回几个
return writer.numDocs();
}
/**
* 索引指定文件
* @throws Exception
*/
private void indexFile(File files) throws Exception {
System.out.println("索引文件:"+files.getCanonicalPath());
//索引要一行一行的找,,在数据中为文档,所以要得到所有行,即文档
Document document = getDocument(files);
//开始写入,就把文档写进了索引文件里去了;
writer.addDocument(document);
}
/**
* 获得文档,在文档里在设置两个字段
*
* 获得文档,相当于数据库里的一行
* @throws Exception
* */
private Document getDocument(File files) throws Exception {
Document doc = new Document();
doc.add(new TextField("contents",new FileReader(files)));
//Field.Store.YES:把文件名存索引文件里,上面没有就说明不需要加到索引文件里去
doc.add(new TextField("FileName", files.getName(), Field.Store.YES));
//把完整路径存在索引文件里
doc.add(new TextField("fullPath", files.getCanonicalPath(),Field.Store.YES));
//返回document
return doc;
}
//开始测试写入索引
public static void main(String[] args){
//索引指定的路径
String indexDir = "E:\\luceneDemo4";
//被索引数据路径
String dataDir = "E:\\luceneDemo4\\data";
//写索引
Indexer indexer = null;
int numIndex = 0;
//索引开始时间
long start = System.currentTimeMillis();
try {
indexer = new Indexer(indexDir);
//将要索引的数据路径(int:因为这是要索引的数据,有多少就返回多少数量的索引文件)
numIndex = indexer.index(dataDir);
} catch (Exception e) {
e.printStackTrace();
}
//索引结束时间
long end = System.currentTimeMillis();
//显示结果
System.out.println("索引了 "+numIndex+" 个文件,花费了 "+(end-start)+" 毫秒");
}
}效果如下:说明检索成功!
索引文件:E:\luceneDemo4\data\a.txt
索引文件:E:\luceneDemo4\data\b.txt
索引了 2 个文件,花费了 338 毫秒
接下来就是根据索引来对特定项的搜索,代码如下:
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* 对索引文档进行特定查询、解析表达式查询
* @author SZQ
*/
public class searchDocumentDingEl {
private Directory dir;
private IndexReader reader;
private IndexSearcher searcher;
@Before
public void setUp() throws Exception {
//得到索引所在目录的路径
dir = FSDirectory.open(Paths.get("E:\\luceneDemo4"));
//通过dir得到的路径下的所有的文件
reader = DirectoryReader.open(dir);
//建立索引查询器
searcher = new IndexSearcher(reader);
}
@After
public void tearDown() throws Exception {
reader.close();
}
/**
* 对特定项搜索:对索引文档有的分词进行查询
* @throws Exception
*/
@Test
public void testTermQuery()throws Exception{
//定义要查询的索引
String searchField = "contents";
//根据contents要查询的对象
String q = "percent";
//运用term来查找
Term t = new Term(searchField,q);
//通过term得到query对象
Query query = new TermQuery(t);
//获得查询的hits
TopDocs hits = searcher.search(query, 10);
//显示结果
System.out.println("匹配 '"+q+"',总共查询到"+hits.totalHits+"个文档");
//循环得到文档,得到文档就可以得到数据
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=searcher.doc(scoreDoc.doc);
System.out.println(doc.get("fullPath"));
}
}
/**
* 解析查询表达式
* @throws Exception
*/
@Test
public void testQueryParser()throws Exception{
String searchField="contents";
String q="Rob* AND separab*";
//实例化分析器
Analyzer analyzer = new StandardAnalyzer();
//建立查询解析器
/**
* 第一个参数是要查询的字段;
* 第二个参数是分析器Analyzer
* */
QueryParser parser=new QueryParser(searchField, analyzer);
//根据传进来的p查找
Query query=parser.parse(q);
//开始查询
/**
* 第一个参数是通过传过来的参数来查找得到的query;
* 第二个参数是要出查询的行数
* */
TopDocs hits=searcher.search(query, 100);
//遍历topDocs
/**
* ScoreDoc:
* scoreDocs:
* @throws Exception
* */
System.out.println("匹配 "+q+"查询到"+hits.totalHits+"个记录");
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=searcher.doc(scoreDoc.doc);
System.out.println(doc.get("fullPath"));
}
}
}出现大到的结果即成功。
接下来来看一下Lucene的特殊查询索引,
代码如下:
//****写索引 start********
package SpicalQuery;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private Integer ids[]={1,2,3};
private String citys[]={"aingdao","banjing","changhai"};
private String descs[]={
"Qingdao is b beautiful city.",
"Nanjing is c city of culture.",
"Shanghai is d bustling city."
};
private Directory dir;
/**
*实例化indexerWriter
* @return
* @throws Exception
*/
private IndexWriter getWriter()throws Exception{
Analyzer analyzer=new StandardAnalyzer();
IndexWriterConfig iwc=new IndexWriterConfig(analyzer);
IndexWriter writer=new IndexWriter(dir, iwc);
return writer;
}
/**
* 获取indexDir
* @param indexDir
* @throws Exception
*/
private void index(String indexDir)throws Exception{
dir=FSDirectory.open(Paths.get(indexDir));
IndexWriter writer=getWriter();
for(int i=0;inew Document();
doc.add(new IntField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city",citys[i],Field.Store.YES));
doc.add(new TextField("desc", descs[i], Field.Store.YES));
writer.addDocument(doc);
}
writer.close();
}
public static void main(String[] args) throws Exception {
new Indexer().index("E:\\luceneDemo5");
}
}
//****写索引 end********
//****特殊项查找 start********
import java.nio.file.Paths;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermRangeQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.BytesRef;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class SearchTest {
private Directory dir;
private IndexReader reader;
private IndexSearcher is;
@Before
public void setUp() throws Exception {
dir=FSDirectory.open(Paths.get("E:\\luceneDemo5"));
reader=DirectoryReader.open(dir);
is=new IndexSearcher(reader);
}
@After
public void tearDown() throws Exception {
reader.close();
}
/**
* ָ指定项范围查询 TermRangeQuery ;对应效果1
* @throws Exception
*/
@Test
public void testTermRangeQuery()throws Exception{
//核心句
TermRangeQuery query=new TermRangeQuery("desc", new BytesRef("b".getBytes()), new BytesRef("c".getBytes()), true, true);
TopDocs hits=is.search(query, 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=is.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
/**
* 指定数字范围查询 NumericRangeQuery ;对应效果2
* @throws Exception
*/
@Test
public void testNumericRangeQuery()throws Exception{
//核心句
//第三个参数:是否包含最小开始数;第四个参数:是否包含最大结束数
NumericRangeQuery query=NumericRangeQuery.newIntRange("id", 1, 2, true, true);
TopDocs hits=is.search(query, 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=is.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
/**
* 指定字符串开头搜索 PrefixQuery ;对应效果3
* @throws Exception
*/
@Test
public void testPrefixQuery()throws Exception{
//运用term来查找
PrefixQuery query=new PrefixQuery(new Term("city","c"));
TopDocs hits=is.search(query, 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=is.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
/**
* 组合查询 BooleanQuery 对应效果4
* @throws Exception
*/
@Test
public void testBooleanQuery()throws Exception{
//指定数字范围查询 NumericRangeQuery ;
NumericRangeQuery query1=NumericRangeQuery.newIntRange("id", 1, 2, true, true);
//指定字符串开头搜索 PrefixQuery ;
PrefixQuery query2=new PrefixQuery(new Term("city","a"));
//核心句
BooleanQuery.Builder booleanQuery=new BooleanQuery.Builder();
//把多条件查询的query都加到BooleanQuery中去
/**
* FILTER:是否统计的意思,一般不常用;
* MUST:相当于 and,同时满足条件;
* MUST_NOT:相当于not;
* SHOULD:相当于or,两者满足一个条件即可查出
*/
booleanQuery.add(query1,BooleanClause.Occur.MUST);
booleanQuery.add(query2,BooleanClause.Occur.MUST);
TopDocs hits=is.search(booleanQuery.build(), 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=is.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
}
****特殊项查找 end******** 显示效果如下:
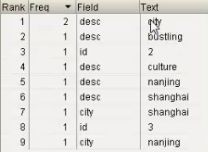
效果1:
1
aingdao
Qingdao is b beautiful city.
2
banjing
Nanjing is c city of culture.
3
changhai
Shanghai is d bustling city.
效果2:
1
aingdao
Qingdao is b beautiful city.
2
banjing
Nanjing is c city of culture.
效果3:
3
changhai
Shanghai is d bustling city.
效果4:
1
aingdao
Qingdao is b beautiful city.
以上都对文档为全英文的时候检索查询的,那么在文档为全中文的时候该怎么办呢?
看一下以下的代码:
//****写索引 start******
import java.nio.file.Paths;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private Integer ids[]={1,2,3};
private String citys[]={"青岛","南京","上海"};
private String descs[]={
"青岛是一个漂亮的城市。",
"南京是一个文化的城市。",
"上海是一个繁华的城市。"
};
private Directory dir;
/**
*实例化indexerWriter
* @return
* @throws Exception
*/
private IndexWriter getWriter()throws Exception{
//中文分词器
SmartChineseAnalyzer analyzer=new SmartChineseAnalyzer();
IndexWriterConfig iwc=new IndexWriterConfig(analyzer);
IndexWriter writer=new IndexWriter(dir, iwc);
return writer;
}
/**
* 获取indexDir
* @param indexDir
* @throws Exception
*/
private void index(String indexDir)throws Exception{
dir=FSDirectory.open(Paths.get(indexDir));
IndexWriter writer=getWriter();
for(int i=0;inew Document();
doc.add(new IntField("id", ids[i], Field.Store.YES));
doc.add(new StringField("city",citys[i],Field.Store.YES));
doc.add(new TextField("desc", descs[i], Field.Store.YES));
writer.addDocument(doc);
}
writer.close();
}
public static void main(String[] args) throws Exception {
new Indexer().index("E:\\luceneDemo6");
//对应图一
}
}
//****写索引 end********
//****对中文检索 start********
import java.io.StringReader;
import java.nio.file.Paths;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.search.highlight.SimpleSpanFragmenter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
*
* 通过索引字段来读取文档
* @author SZQ
*
*/
public class ReaderByIndexerTest {
public static void search(String indexDir, String par) throws Exception{
//得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
//通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
//建立索引查询器
IndexSearcher searcher = new IndexSearcher(reader);
//中文分词器
SmartChineseAnalyzer analyzer=new SmartChineseAnalyzer();
//建立查询解析器
/**
* 第一个参数是要查询的字段;
* 第二个参数是分析器Analyzer
* */
QueryParser parser = new QueryParser("desc", analyzer);
//根据传进来的par查找
Query query = parser.parse(par);
//计算索引开始时间
long start = System.currentTimeMillis();
//开始查询
/**
* 第一个参数是通过传过来的参数来查找得到的query;
* 第二个参数是要出查询的行数
* */
TopDocs topDocs = searcher.search(query, 10);
//索引结束时间
long end = System.currentTimeMillis();
System.out.println("匹配"+par+",总共花费了"+(end-start)+"毫秒,共查到"+topDocs.totalHits+"条记录。");
//高亮显示start
//算分
QueryScorer scorer=new QueryScorer(query);
//显示得分高的片段
Fragmenter fragmenter=new SimpleSpanFragmenter(scorer);
//设置标签内部关键字的颜色
//第一个参数:标签的前半部分;第二个参数:标签的后半部分。
SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("","");
//第一个参数是对查到的结果进行实例化;第二个是片段得分(显示得分高的片段,即摘要)
Highlighter highlighter=new Highlighter(simpleHTMLFormatter, scorer);
//设置片段
highlighter.setTextFragmenter(fragmenter);
//高亮显示end
//遍历topDocs
/**
* ScoreDoc:是代表一个结果的相关度得分与文档编号等信息的对象。
* scoreDocs:代表文件的数组
* @throws Exception
* */
for(ScoreDoc scoreDoc : topDocs.scoreDocs){
//获取文档
Document document = searcher.doc(scoreDoc.doc);
//输出全路径
System.out.println(document.get("city"));
System.out.println(document.get("desc"));
String desc = document.get("desc");
if(desc!=null){
//把全部得分高的摘要给显示出来
//第一个参数是对哪个参数进行设置;第二个是以流的方式读入
TokenStream tokenStream=analyzer.tokenStream("desc", new StringReader(desc));
//获取最高的片段
System.out.println(highlighter.getBestFragment(tokenStream, desc));
}
}
reader.close();
}
//开始测试
public static void main(String[] args) {
//索引指定的路径
String indexDir = "E:\\luceneDemo6";
//查询的字段
String par = "南京文明";
try {
search(indexDir,par);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//对应图二
}
//****对中文检索 end******** 图一:说明写索引成功!
打印台:Success Indexer
图二:说明查找成功!
匹配南京文明,总共花费了42毫秒,共查到1条记录。
南京
南京是一个文化的城市。
注意,一下的代码截图:

为什么会有标签呢?
看一下的代码:
//高亮显示start*****
//算分
QueryScorer scorer=new QueryScorer(query);
//显示得分高的片段
Fragmenter fragmenter=new SimpleSpanFragmenter(scorer);
//设置标签内部关键字的颜色
//第一个参数:标签的前半部分;第二个参数:标签的后半部分。
SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter(““,”“);
//第一个参数是对查到的结果进行实例化;第二个是片段得分(显示得分高的片段,即摘要)
Highlighter highlighter=new Highlighter(simpleHTMLFormatter, scorer);
//设置片段
highlighter.setTextFragmenter(fragmenter);
//*高亮显示end*****
String desc = document.get(“desc”);
if(desc!=null){
//把全部得分高的摘要给显示出来
//第一个参数是对哪个参数进行设置;第二个是以流的方式读入
TokenStream tokenStream=analyzer.tokenStream(“desc”, new StringReader(desc));
//获取最高的片段
System.out.println(highlighter.getBestFragment(tokenStream, desc));
}
}
以上的代码,就是设置高亮显示的效果,就像百度里的高亮显示一样,如下图:


关键字有颜色,搜索的要点片段显示出来。这就是高亮显示!
以上就是Lucene的全部内容,希望可以帮到大家!有兴趣的话,可以互加关注!欢迎各位朋友!