Spring Cloud Sleuth 服务链路跟踪入门
这几天事比较多,而且,有许多同事离职,导致我最近每天过的浑浑噩噩的,也不知道干点啥,加之,最近工作不太忙,所以可以有时间来整理一下我的博客了...我是一个不是特别会写博客的人,因为觉得才疏学浅,而且文采不是很好,所以,今天有这样的机会可以锻炼一下这方面的能力。
有些文字主要也是借鉴其他优秀的博客书写者。
进入正题:
一、简介
一个中型的项目会包含许多个微服务,微服务与微服务之间互相调用,调用过程可能比较复杂,如果其中一个微服务出现问题,我们很难快速的发现是哪个服务出现的问题。因此,Spring Cloud Sleuth服务链路跟踪功能就可以帮助我们快速的发现错误根源以及监控分析每条请求链路上的性能等。

二、介绍一些简单的术语(摘抄)
Span:工作的基本单位 例如,发送RPC是一个新的跨度,以及向RPC发送响应。Span由跨度的唯一64位ID标识,跨度是其中一部分的跟踪的另一个64位ID。跨度还具有其他数据,例如描述,时间戳记事件,键值注释(标签),导致它们的跨度的ID以及进程ID(通常是IP地址)。
跨距开始和停止,他们跟踪他们的时间信息。创建跨度后,必须在将来的某个时刻停止。
跟踪:一组spans形成树状结构。例如,如果您正在运行分布式大数据存储,则可能会由put请求形成跟踪。
注释: 用于及时记录事件的存在。用于定义请求的开始和停止的一些核心注释是:
-
cs - 客户端发送 - 客户端已经发出请求。此注释描绘了跨度的开始。
-
sr - 服务器接收 - 服务器端得到请求,并将开始处理它。如果从此时间戳中减去cs时间戳,则会收到网络延迟。
-
ss - 服务器发送 - 在完成请求处理后(响应发送回客户端时)注释。如果从此时间戳中减去sr时间戳,则会收到服务器端处理请求所需的时间。
-
cr - 客户端接收 - 表示跨度的结束。客户端已成功接收到服务器端的响应。如果从此时间戳中减去cs时间戳,则会收到客户端从服务器接收响应所需的整个时间。
更详细见官网:https://springcloud.cc/spring-cloud-dalston.html#_spring_cloud_sleuth
我们通过一个简单的例子来说明一下:
【a】eureka-server: 服务注册中心,端口1111
【b】efficiency-springcloudzipkinserver-service: zipkin服务端,端口2222
【c】efficiency-protal: 服务消费者1,端口2000,主要用于ribbon调用
【d】efficiency-basicdata-service: 服务消费者2,端口2010,主要用于ribbon调用
下面我们搭建zipkin-server服务端,新建efficiency-springcloudzipkinserver-service工程,注意引入zipkin的依赖
三、在启动类上面@EnableZipkinServer
@EnableZipkinServer注解的作用:开启zipkin服务链路追踪功能

配置文件application.yml

到这里zipkin-server服务就已经搭建好了。
四、新建springcloud zipkin client服务
新建efficicacy-basicdata-service服务,引入zipkin相关jar包,pom.xml内容:

application.yml文件增加AlwaysSampler:作用相当于在配置文件中配置 spring.sleuth.sampler.percentage=1,设置sleuth收集信息的比率为1,默认10%
spring.zipkin.base-url = zipkin 服务地址
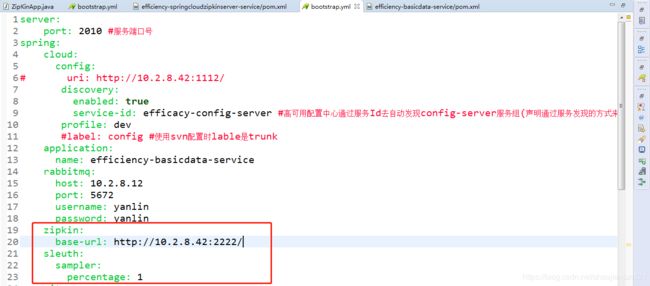
至此,zipkin client端已经搭建完成。
依次启动 eureka-server、zipkin-server、zipkin-client服务,启动完成后,通过url调用zipkin-client端,http服务端收集链路追中数据,放在缓存中。

希望跟大家一起学习!!!!