内存管理-之启动-基于linux3.10
Linux内存管理是linux操作系统的子系统之一,是一个非常重要的子系统,这是一个冗杂而又庞大的部分,和网络子系统的区别在于其和CPU架构和存储模型是息息相关的。内存管理到底是个什么意思?这里借用深入理解linux内核架构那本书对内存管理涵盖的领域概况:
l 内存中物理页的管理
l 分配大块内存的伙伴系统(buddy)
l 分配较小块内存的系统slab、slub、slob
l 分配非连续内存块vmalloc
l 进程地址空间
1.1物理内存的布局何时获得
在x86系统下,在系统还是实模式时就调用bios中断获取物理内存的布局了。在arch/x86/boot/main.c函数中的main.c函数会调用detect_memory()函数获取当前内存布局。调用BIOS的功能通常称为e820,这是因为使用该获取内存布局功能时ax寄存的十六进制值是0xe820。detect_memory()函数定义于arch/x86/boot/memory.c文件中。
static int detect_memory_e820(void)
{
int count = 0;
struct biosregs ireg, oreg;
struct e820entry *desc = boot_params.e820_map;
static struct e820entry buf; /* static so it is zeroed */
initregs(&ireg);
ireg.ax = 0xe820;
ireg.cx = sizeof buf;
ireg.edx = SMAP;
ireg.di = (size_t)&buf;
do {
intcall(0x15, &ireg, &oreg);
ireg.ebx = oreg.ebx; /* for next iteration... */
/* BIOSes which terminate the chain with CF = 1 as opposed
to %ebx = 0 don't always report the SMAP signature on
the final, failing, probe. */
if (oreg.eflags & X86_EFLAGS_CF)
break;
/* Some BIOSes stop returning SMAP in the middle of
the search loop. We don't know exactly how the BIOS
screwed up the map at that point, we might have a
partial map, the full map, or complete garbage, so
just return failure. */
if (oreg.eax != SMAP) {
count = 0;
break;
}
*desc++ = buf;
count++;
} while (ireg.ebx && count < ARRAY_SIZE(boot_params.e820_map));
return boot_params.e820_entries = count;
}该函数的do while语句是一个遍历语句,其作用是遍历所有可用的物理内存段,并将物理内存段的个数(count值)记录在boot_params.e820_entries,boot_params是系统启动的参数,注意这里是探测可用的物理内存。
为了从纷繁的内存管理代码细节中脱离出来,这里不会像网络子系统那部分那样逐行代码去分析,而侧重功能和管理方法的分析。图1.1是X86 32bit情况下的内存使用分布情况。
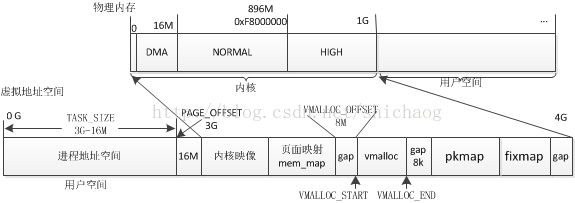
虚拟内存到物理内存到物理内存的变换是由MMU完成的。内核空间的地址内容
X86虚拟机下dmesg导出的内核虚拟地址拓扑如下:
[ 0.000000] virtual kernel memory layout:
[ 0.000000] fixmap : 0xfff14000 - 0xfffff000 ( 940 kB)
[ 0.000000] pkmap : 0xffc00000 - 0xffe00000 (2048 kB)
[ 0.000000] vmalloc : 0xf83fe000 - 0xffbfe000 ( 120 MB)
[ 0.000000] lowmem : 0xc0000000 - 0xf7bfe000 ( 891 MB)
[ 0.000000] .init : 0xc19b9000 - 0xc1a93000 ( 872 kB)
[ 0.000000] .data : 0xc1663132 - 0xc19b8200 (3412 kB)
[ 0.000000] .text : 0xc1000000 - 0xc1663132 (6540 kB)
由这上述信息可以看到,虚拟内存主要分为lowmen、vmalloc、pkmap(persistentkernel map)、fixmap这四个类型,对应会有它们各自的管理代码,后面会叙述。
在嵌入式情景下,有略微的差别。下面是一个arm嵌入式系统dmesg导出的内存拓扑:
[ 0.000000] Virtual kernel memory layout:
[ 0.000000] vector : 0xffff0000 - 0xffff1000 ( 4 kB)
[ 0.000000] fixmap : 0xfff00000 - 0xfffe0000 ( 896 kB)
[ 0.000000] vmalloc : 0x86800000 - 0xff000000 (1928 MB)
[ 0.000000] lowmem : 0x80000000 - 0x86600000 ( 102 MB)
[ 0.000000] modules : 0x7f000000 - 0x80000000 ( 16 MB)
[ 0.000000] .text : 0x80008000 - 0x805c9f04 (5896 kB)
[ 0.000000] .init : 0x805ca000 - 0x808cdeac (3088 kB)
[ 0.000000] .data : 0x808ce000 - 0x8091e920 ( 323 kB)
[ 0.000000] .bss : 0x8091e920 - 0x80965828 ( 284 kB)
上述内存拓扑的一个特点是虚拟内存的地址空间可以达到4G而不需要考虑实际物理内存的大小,虚拟内存是内存管理环节中的一环,在认识linux管理模型之前,了解CPU架构对内存的影响还是挺有好处的。
1.2 CPU架构

图1.2 CPU存储架构
图1.2可知,按CPU访问开销由低到高的存储类型依次是寄存器、L1cache、L2cache、L3cache以及主存。如果没有cache,只有register和主存,这就意味着CPU取指令或者数据时,CPU将会等待数据或者指令将需要很长时间,这降低的CPU的利用率。如果和指令相关的操作或者和数据相关操作都存储在寄存器里,那么CPU取指令和数据的开销几乎可以忽略不计。
Reg-A、Reg-B:是两个寄存器组,它们的功能和地位是一样的,在实现超线程技术时,两个线程使用不同的寄存器组,这就意味着寄存器内容在线程切换时不需要保护。CPU运算核心访问它们的周期约为一个时钟周期。
L1d和L1i,分别是数据和指令cache,数据和指令分开存放,运算核心访问其约需4个时钟周期。通常它的大小分别约32K。
L2cache:第二级缓存,为L1d和L1i共享,其容量通常是L1d、L1i总和的4倍。两个CPU有其各自的L2cache。访问约12cycle。
L3cache:为第三级缓存,其容量通常是单个L2的128倍,依据情况而不同,访问周期40cycle。
Cpu运算核心访问DDR的周期约为240cycle。
由cpu运算核心访问cache和DDR的时钟周期可知,cache在一定程度上缓解了慢速的主存和快速的CPU运算核心不匹配导致的效率变低的问题,但是也带来了内存管理的复杂性,这种复杂性由芯片设计人员和软件设计人员共同解决,芯片设计人员提供了TLB和MMU(针对分页和分段,实模式不会启用MMU)两个功能模块,软件设计人员需要对这两个功能模块以及cache做些配置和管理。
MMU(memory management unit)的主要作用是虚拟地址转换成实地址。在图1.1中,虚拟内存到物理内存的转换就是由MMU完成的。对内核而言,x86的虚拟地址到物理地址的转换关系是:
虚拟地址 = 物理地址 + PAGE_OFFSET
从上述的关系也可以得到物理地址,x86上还有段地址、线性地址,段地址在arm上没有类似的概念。
Cache部分的内容还挺多的,其原理可以参。考http://en.wikipedia.org/wiki/CPU_cache
第二章 物理内存管理模型
如何管理常见的4G或者更大的内存条,当前CPU倾向于不再提高CPU的主频,而朝着多核的方向发展,所以内存模型进一步被复杂化,且分为一致性内存(UMA)和非一致性内存(NUMA)两种情况。对于UMA情况,CPU访问任何一个存储空间的开销是等价的,而对于NUMA它们的开销则是不同的。

图2.1 UMA和NUMA内存示意
图2.1是UMA和NUMA的示意,左边三个CPU访问内存节点NODE0的开销是一样的,而右侧访问NODE0的开销CPU1是大于CPU2的。在后一种情况下,应该将CPU2需要的指令和数据放在NODE0中,将CPU1 需要的指令和数据放在NODE2中,这样提高系统的效率。处理器核以及内存的两种布局对应两种内存管理模型,linux将UMA这种模型作为NUMA这种模型的一个特例,当然混合型的也是NUMA的一个特例,对于混合型,只需看图2.1右侧的NUMA模型,两颗CPU访问NODE1的开销一样,而访问其它NODE节点的开销并不一样。

图2.2 内存管理模型
结合图2.2,分析一下linux内存管理模型,假设图中左上角那根内存条到各个CPU的开销是一样的且整个系统只有这一根内存条,则可以认为该系统的内存模型退化为图2.1中左侧的UMA模型,该内存条使用node表示,对应的其管理数据结构是pg_data_t,该node又分为若干类型的zone,zone的类型是有限的,根据架构不同而略有区别,对于IA-32架构,有ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM以及ZONE_MOVABLE;这对应于图的中上部。
ZONE_DMA和早期的ISA设备是有关系的;
ZONE_NORMAL指示的是可直接映射到内核段的地址空间;
ZONE_HIGH是超出内核段的物理内存;
ZONE_MOVABLE旨在防止物理内存碎片。
为了防止内存碎片,将每个zone又分为五种类型,放大镜将ZONE_DMA类型的zone进行了放大,其它类型的zone组织内存的方式和其一样,所以这里只对ZONE_DMA进行分析,每个zone采用了反碎片技术,这一技术有别于磁盘的碎片整理,后者依赖于文件系统,将零散的小块合并成连续的大块,而反碎片技术从源头上阻止碎片的产生;依据内存使用的方式,将zone分为unmovable,reclaimable, movale,reserve类型。分别对应于不可移动,可回收,可移动,保留备用(紧急情况下使用)。
ZONE_DMA有16M大小,ZONE_NORMAL上界是896M,如何管理这么多的且变化的内存,仅仅分成五种类型还是不够的,linux使用了页管理技术,每4KB作为一个进行管理,此外还有一种4MB的大页,以提高TLB命中的效率。先不考虑大页,仅仅16M的存储空间就对应4096页,对于896M,将有229376个页,如何高效的管理这些页?linux采用了伙伴系统方法,这一方法已经包含在图2.2放大镜图像里了。Buddy system的核心思想是:
根据使用有些情况需要一个页4KB就可以了,也有需要8KB,依次类推可能需要1M等等,既然如此何不将4KB页合并成8KB,8KB的页合并成16KB,16KB合并成32KB,这样管理也方便。
图2.2中的0、1…11的意识是指2的0次方、1次方…11次方,2的0次方等于1,表示该链表所有员的大小是一个页4KB,2的1次方等于2,表示该链表的所有成员大小是8KB,依次类推,这个组织也可以参看图2.3,这样需要多大的内存就到哪个内存链表上去取(还要根据zone类型和反碎片类型)。
单单只有buddy还有一个问题,就是在需要2字节的内存时,去申请一个页大小的内存4KB,实在有点浪费,所以linux引入slab管理方法,针对嵌入式和服务器又提出了slob和slub管理模型,不过到此可以知道其实内存管理的核心的数据结构是node和zone。
一个具有NUMA的X86-64系统的实例如下:
$ cat /proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 1 0 1 0 2 1 1 0 1 0 0
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 0 3
Node 0, zone DMA, type Reserve 0 0 0 0 0 0 0 0 0 1 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 276 395 221 1 0 0 0 0 0 0 0
Node 0, zone DMA32, type Reclaimable 27246 21166 8671 70 0 0 0 0 0 0 0
Node 0, zone DMA32, type Movable 3 8 11 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Reserve 0 0 0 11 1 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 10635 67 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Reclaimable 28157 2 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Movable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Reserve 0 0 0 9 4 2 1 0 0 1 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Reclaimable Movable Reserve Isolate
Node 0, zone DMA 1 0 6 1 0
Node 0, zone DMA32 89 1103 334 2 0
Node 0, zone Normal 225 5583 846 2 0
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 1, zone Normal, type Unmovable 2266 3095 185 0 0 0 0 0 0 0 0
Node 1, zone Normal, type Reclaimable 442807 302949 10893 0 0 0 0 0 0 0 0
Node 1, zone Normal, type Movable 0 1 2 0 0 0 0 0 0 0 0
Node 1, zone Normal, type Reserve 0 0 0 0 1 1 1 1 1 0 0
Node 1, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Reclaimable Movable Reserve Isolate
Node 1, zone Normal 123 7791 276 2 0
2.1 Node
Linux使用pg_data_t管理内存模型,

图2.3 内存管理数据拓扑
在图2.1中,根据CPU访问内存的代价不一样,将每一个代价节点抽象成一个node,对于NUMA退化为一个node,需要注意的node节点数并不一定对应于内存条的个数。每一个node节点通常分为若干的域(zone)。
enum zone_type {
ZONE_DMA,
ZONE_DMA32,
ZONE_NORMAL,
ZONE_HIGHMEM,
ZONE_MOVABLE,
__MAX_NR_ZONES
};
因为并不是所有内存都支持DMA操作,所以这里专门开辟了一个称为ZONE_DMA类型的域以支持DMA操作,这块域大小依赖于体系结构,在i386上其小于16M,这在图1.1中物理内存有所显示。
ZONE_DMA32是针对x86架构64为处理器而准备的,因为其可以使用的DMA范围由16M拓展到了4G。
对于i386 ZONE_NORMAL的上限就是896M,是这部分内存是直接映射的。
对于i386 ZONE_HIGHMEM在ZONE_NORMAL之后,这部分的内存页是动态映射的,主要是因为页表项有限,其基本思想是需要高端内存时,申请页表进行映射,用完释放再回收页表。
700 typedef struct pglist_data {
/*内存管理类型,ZONE_DMA、ZONE_NORMAL、ZONE_HIGH
701 struct zone node_zones[MAX_NR_ZONES];
/*每次内存申请会落到zonelist上,zonelist是zone(区)的列表,对于分配内存,第一个区是“全局”的,其它的zone是后备zone,后备zone按优先级递减排序,这里的优先级是指访问的代价,代价越大越靠后。对于UMA,node_zonelists只有一个成员,而对于NUMA,MAX_ZONELISTS的值是2,[0]是有后备zone的zonelist,而[1]没有后备zone,用于GFP_THISNODE*/
702 struct zonelist node_zonelists[MAX_ZONELISTS];
/*701行实际的node_zones成员数*/
703 int nr_zones;
/*非稀疏内存管理模型时,指向struct page中的第一个页面,其存放在mem_map数组中*/
704 #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
705 struct page *node_mem_map;
/*Page Cgroup,可看做mem_map的扩展,该结构体用于确定cgroup,LXC用到cgroup和命名空间*/
706 #ifdef CONFIG_MEMCG
707 struct page_cgroup *node_page_cgroup;
708 #endif
709 #endif
/*指向内存引导程序*/
710 #ifndef CONFIG_NO_BOOTMEM
711 struct bootmem_data *bdata;
712 #endif
713 #ifdef CONFIG_MEMORY_HOTPLUG
714 /*
715 * Must be held any time you expect node_start_pfn, node_present_pages
716 * or node_spanned_pages stay constant. Holding this will also
717 * guarantee that any pfn_valid() stays that way.
718 *
719 * Nests above zone->lock and zone->size_seqlock.
720 */
721 spinlock_t node_size_lock;
722 #endif
/*起始页帧号,对于UMA,该值是0,对于NUMA,该值随节点不同而不同,node_start_pfn全局唯一,由页帧号全局唯一性决定*/
723 unsigned long node_start_pfn;
724 unsigned long node_present_pages; /* total number of physical pages ,针对该node而言的总数*/
725 unsigned long node_spanned_pages; /* total size of physical page
726 range, including holes */
//具有全局性,对于UMA,该值是1,对于NUMA从0开始计数
727 int node_id;
728 nodemask_t reclaim_nodes; /* Nodes allowed to reclaim from */
/*swap dameon*/
729 wait_queue_head_t kswapd_wait;
730 wait_queue_head_t pfmemalloc_wait;
731 struct task_struct *kswapd; /* Protected by lock_memory_hotplug() */
/*定义需要释放的区域长度*/
732 int kswapd_max_order;
733 enum zone_type classzone_idx;
747 } pg_data_t;
2.2 Zone结构
Zone的类型如下,对于x86, ZONE_HIGH是896M以上的空间,不能直接映射。
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
__MAX_NR_ZONES
};
313 struct zone {
/*WMARK_MIN,WMARK_LOW,WMARK_HIGH,用于标记各阈值,影响kswap dameon的行为。
*WMARK_HIGH:内存不紧张。
*WMARK_LOW:内存有点紧张,需要将内存页换到外部存储设备(硬盘、SSD)
* WMARK_MIN :内存的最低阈值,这是回收页压力增大
由*_wmark_pages(zone)宏存取该字段
*/
317 unsigned long watermark[NR_WMARK];
318
319 /*
320 * When free pages are below this point, additional steps are taken
321 * when reading the number of free pages to avoid per-cpu counter
322 * drift allowing watermarks to be breached
323 */
324 unsigned long percpu_drift_mark;
325
326 /*每个内存区保留的内存页数。通过sysctl_lowmem_reserve_ratio sysctl 可以改变。*/
334 unsigned long lowmem_reserve[MAX_NR_ZONES];
335
336 /*
337 * 这是每个zone都会保留的页,本身和dirty没什么关系。
339 */
340 unsigned long dirty_balance_reserve;
341 /*每个CPU的冷热页帧列表,在高速缓存中的页称为“热”,不在高速缓存中的页称为“冷”*/
350 struct per_cpu_pageset __percpu *pageset;
351 /*
352 * 释放内存时使用该锁,防止并发
353 */
354 spinlock_t lock;
/*标志是否所有也都不可回收*/
355 int all_unreclaimable;
/*buddy系统核心数据结构,相见后面*/
368 struct free_area free_area[MAX_ORDER];
/*对称多处理器情况下,可能对该结构的不同部分访问,ZONE_PADDING是按缓存行大小填充对其,这样并发访问该结构体时,可以通过访问两个缓存行以提高速度*/
389 ZONE_PADDING(_pad1_)
390
391 /*这些是页回收扫描器使用的字段*/
392 spinlock_t lru_lock;
393 struct lruvec lruvec;
394
395 unsigned long pages_scanned; /* since last reclaim */
396 unsigned long flags; /* zone flags, see below */
397
398 /* Zone 统计,percpu_drift_mark会和这里的统计的空闲也对比,以避免per-CPU计数器漂移*/
399 atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
400
401 /*
402 * 该zone的LRU链表上的活跃匿名页和非活跃匿名页比例
404 */
405 unsigned int inactive_ratio;
406
407
408 ZONE_PADDING(_pad2_)
409 /* Rarely used or read-mostly fields */
410
411 /*
412 * wait_table -- the array holding the hash table
413 * wait_table_hash_nr_entries -- the size of the hash table array
414 * wait_table_bits -- wait_table_size == (1 << wait_table_bits)
434 */
435 wait_queue_head_t * wait_table;
436 unsigned long wait_table_hash_nr_entries;
437 unsigned long wait_table_bits;
438
439 /*
440 * 该node节点所属的node节点
441 */
442 struct pglist_data *zone_pgdat;
443 /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT ,将物理地址转换为起始页帧号*/
444 unsigned long zone_start_pfn;
445
446 /*
447 * spanned_pages is the total pages spanned by the zone, including
448 * holes, which is calculated as:
449 * spanned_pages = zone_end_pfn - zone_start_pfn;
450 *
451 * present_pages is physical pages existing within the zone, which
452 * is calculated as:
453 * present_pages = spanned_pages - absent_pages(pages in holes);
454 *
455 * managed_pages is present pages managed by the buddy system, which
456 * is calculated as (reserved_pages includes pages allocated by the
457 * bootmem allocator):
458 * managed_pages = present_pages - reserved_pages;
459 *
460 * So present_pages may be used by memory hotplug or memory power
461 * management logic to figure out unmanaged pages by checking
462 * (present_pages - managed_pages). And managed_pages should be used
463 * by page allocator and vm scanner to calculate all kinds of watermarks
464 * and thresholds.
465 *
466 * Locking rules:
467 *
468 * zone_start_pfn and spanned_pages are protected by span_seqlock.
469 * It is a seqlock because it has to be read outside of zone->lock,
470 * and it is done in the main allocator path. But, it is written
471 * quite infrequently.
472 *
473 * The span_seq lock is declared along with zone->lock because it is
474 * frequently read in proximity to zone->lock. It's good to
475 * give them a chance of being in the same cacheline.
476 *
477 * Write access to present_pages and managed_pages at runtime should
478 * be protected by lock_memory_hotplug()/unlock_memory_hotplug().
479 * Any reader who can't tolerant drift of present_pages and
480 * managed_pages should hold memory hotplug lock to get a stable value.
481 */
482 unsigned long spanned_pages;
483 unsigned long present_pages;
484 unsigned long managed_pages;
485
486 /*
487 * rarely used fields:
488 */
489 const char *name;
490 } ____cacheline_internodealigned_in_smp;
2.3 page结构
每一个物理页都有一个struct page与之关联,以跟踪页使用情况,
41 struct page {
42 /* First double word block */
43 unsigned long flags;
45 struct address_space *mapping;
52 /* Second double word */
53 struct {
54 union {
55 pgoff_t index; /* 在映射页的偏移*/
56 void *freelist; /* slub/slob 第一个空闲对象 */
57 bool pfmemalloc; /*如果该标识由页分配器设置,则ALLOC_NO_WATERMARKS也被设置并且空闲内存量不满足low水印,这意味着内存有点紧张,调用者必须确保该页用于释放其它页之用。
66 };
67
68 union {
74 /*
75 * Keep _count separate from slub cmpxchg_double data.
76 * As the rest of the double word is protected by
77 * slab_lock but _count is not.
78 */
79 unsigned counters;
82 struct {
83
84 union {
86 // 页表中指向该页的页表入口项(PTE)数,也被用作复合页的尾部页引用计数
101 atomic_t _mapcount;
102
103 struct { /* SLUB */
104 unsigned inuse:16; //在使用的slub对象
105 unsigned objects:15;//slub对象数
106 unsigned frozen:1;
107 };
108 int units; /* SLOB */
109 };
110 atomic_t _count; /*使用计数器,为0则说明没有被内核引用,将可能被释放*/
111 };
112 };
113 };
114
115 /* Third double word block */
116 union {
117 struct list_head lru; /* 换出页列表,由zone->lru_lock 锁保护 */
120 struct { /* slub per cpu partial pages */
121 struct page *next; /* Next partial slab */
126 short int pages;
127 short int pobjects;
129 };
130
131 struct list_head list; /* slobs list of pages */
132 struct slab *slab_page; /* slab fields */
133 };
134
135 /* Remainder is not double word aligned */
136 union {
137 unsigned long private; /*映射私有,用途自定,通常如果设置PagePrivate 标志,则用于buffer_heads,如果设置PageSwapCache,则用于swp_entry_t,如果设置PG_buddy,则用于伙伴系统*/
147 struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
148 struct page *first_page; /* Compound tail pages */
149 };
flags相关的定义在include/linux/page-flags.h文件中,flag用于指示该页是否被锁住、是否是脏页,是否是活动的等,该文件中还定义了一些存取该变量的宏和函数,该标志在某些情况下是可能发生异步更新的。
*mapping如果其最低比特是0,则其指向inode(信息节点,文件系统相关)地址空间或者是NULL。如果映射成匿名内存,最低比特被置位并且其指向anon_vma对象。
第三章内存初始化
在使用内存时,需要知道内存的一些信息,比如物理内存到底有多大?内存是不是分节点的(访问的代价不一样)?启用分页情况下的页表设置情况?内存相关的初始化工作在start_kernel函数完成,下列列出了内存相关的函数。

图3.0.1内存初始化相关函数调用
Build_all_zonelists的作用是处理系统node间zone的备用关系,即如果有node0,node1,node2,如果node0中的某个类型的zone申请内存,发现内存不足,去该节点的其它类型zone也没有,这是向node1还是node2申请,这就牵涉到node1 的开销和node2的开销大小以及去哪个备用zone申请,该函数即完成此工作。
Mm_init停用boot内存分配器,启用伙伴内存管理。
进入setup_arch函数,不论是arm还是x86,映入眼帘的是_text,_etext,_edata,_end,__bss_stop这些变量。这些变量定义在arch/x86/kernel/vmlinux.lds.S文件,类似的将x86=换成arm也能看到arm的连接脚本里对这些变量的定义,这些变量的值在链接时才确定,具体来看,有一个System.map文件,通常和vmlinx在同一个文件夹,在System.map文件里可以找到上述变量的定义。该文件有如下几行,随编译结果不同而有区别:
c1000000 T _text
c1000000 T startup_32
c10000e0 t bad_subarch
c10000e0 W lguest_entry
c10000e0 W xen_entry
c10000e4 T start_cpu0
c10000f8 T _stextc1000000即为3G+16M,这从一个方面验证了内核的代码段确实是从3G+16M开始的,这里的地址是虚拟地址。对于内核在物理内存中的分布情况,可以看/proc/iomem文件,该文件的一部分内容摘录如下:
00000000-00000fff : reserved
00001000-0009efff : System RAM
0009f000-0009ffff : reserved
000a0000-000bffff : PCI Bus 0000:00
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
000ca000-000cbfff : reserved
000ca000-000cafff : Adapter ROM
00100000-7fedffff : System RAM
01000000-01663131 : Kernel code
01663132-019b81ff : Kernel data
01a9b000-01b81fff : Kernel bss从上面可以看到内核代码从1M地方开始存放,前4k作为一个单独的页,其后的640KBIOS和显卡会使用这段区域,从640K到1M是ROM区域,所以linux内核选择从1M开始处连续存放。Setup_arch主要完成以下工作:

图3.0.2 和内存相关的内存初始化
页表初始化会在setup_arch函数完成,kernel_physical_mapping_init用于虚拟地址到物理地址的映射,和页表息息相关,不过在分析页表初始化过程之前先来点linux分页基础,至于分段arm上并不存在这一概念,所以这里直接略过了。
3.1 Linux分页
分页单元将线性地址转换成物理地址,该分页单元将检查访问的物理页是否有效,无效会产生缺页异常通知操作系统。X86上当CR0的PG位被置位时,则启用分页功能,否则,线性地址就是物理地址。现在的Linux采用了四级分页模型,四级页目录分别是:
页全局目录(PageGlobal Directory)
页上级目录(PageUpper Directory)
页中间目录(PageMiddle Directory)
页表(Page Table)
X86-64采用了四级页表,启用PAE特性的x86-32也此采用了四级页表,对于未启用PAE特性的32位系统,看一个三级页表映射到物理地址的过程:
32比特按页目录项10bit,页表10bit,页内偏移12bit,总比特数是10+10+12=32,符合32位系统划分,一个页的大小是4KB,要在这4KB大小里任意寻址,则需要12bit的地址,这正是页内偏移为12bit的原因。线性地址到物理地址的转换分为两步,首先根据线性地址高10比特找到页目录项,然后根据页目录项和线性地址的中间10比特找到页表,最后的12bit用于在页表中寻址,这一过程如下:

图3.1.1 80x86处理器分页
假设一个线性地址范围是0x2000_0000到0x2003_ffff,该地址对应的空间是用户空间,内核从3G开始,这一段包括64(0x2003_ffff-0x2000_0000+1 = 0x4_0000; 0x4_0000/1024=256KB;256KB/4KB=64)个页,
页目录项是线性地址最高10比特,对应的就是0x080,和CR3(不同进程CR3里的值不同)里的基地址值相加得到页表项,同理得到的页目录项作为页表的基地址,取线性地址接下来的10比特和页表项相加得到页的基地址,根据偏移量找到对应的比特,这就是这个查找过程。四级过程类似。
内存容量的物理限制源于芯片的地址总线和数据总线的位宽,从奔腾pro开始,芯片的数据总线从32位被扩展到36比特,这样实际可以访问的物理内存由先前的4GB扩展到64GB。而这一特性正是PAE特性。另外一个PSE(Physical Address Extension)从奔三引入。对于64比特系统,IA64采用了三级分页(不包括页内偏移),而x86_64使用了四级分页技术。
对于32位系统,通过将页上级目录和页中间目录设置成0,实际上加0等于什么也没有加。但是为了兼容32位和64位系统页上级目录和页中间目录还是一直存在的。
线性地址被划分成如下部分,定义在
PAGE_SHIFT:12比特,用于找到页表起始处。
PMD_SHIFT:页内偏移和页表的总比特数,用于找到页中间目录项,当未启用PAE时,其值为22(12位页内偏移以及10位页表项),当PAE启动时其值为21(12位页内偏移以及9位页表项)。
PUD_SHIFT:用于查找页上级目录,x86上,其值等于PMD_SHIFT。
PGDIR_SHIFT:页全局目录的起始地址处,未启用PAE时PGDIR_SHIFT的值是22,启用PAE时其值时30(12比特页内偏移,9比特页表长度,9比特页中间目录长度)。
PTRS_PER_PTE、PTRS_PER_PMD、PTRS_PER_PUD、PTRS_PER_PGD用于计算各入口项的总数。当PAE未启用时,它们值为1024、1、1以及1024,而启用PAE特性时,值为512,512,1和4。
3.2 Setup_arch
接着图3.0.2,在系统启动时PAE特性并未启用,所以页表退化为两级页表,临时页全局目录存放在swapper_pg_dir里,swapper_pg_dir实际存放在bss段,在链接时才会确定其地址,但是该变量的值可以看编译生成的System.map文件。
c19ff000 B __bss_start
c19ff000 R __smp_locks_end
c19ff000 b initial_pg_pmd
c1a00000 b initial_pg_fixmap
c1a01000 B empty_zero_page
c1a02000 B swapper_pg_dir未启用PAE时,PAGE_SHIFT:12;PMD_SHIFT:22;PGDIR_SHIFT:22;
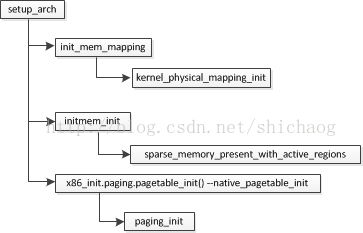
图3.2.1 和内存相关的内存初始化
Init_mem_mapping映射低端内存区,首先映射ISA区域而不管ISA区是否存在内存空洞,然后映射剩下的内存区,max_low_pfn记录的就是低端内存区的最后一个页帧号,根据其大小,按照4MB对其的方式,循环映射完低端内存。而early_ioremap_page_table_range_init负责固定内存映射,图1.1中的fixmap部分,load_cr3操作启用分页机制,而flush操作是保持cache的一致性。
3.2.1 低端内存映射初始化
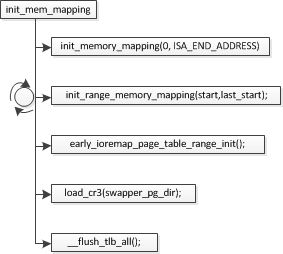
图3.2.2init_mem_mapping流程
由于ISA以及其它区域建立映射过程类似,这里剖析ISA区域的映射过程:
init_memory_mapping(0,ISA_END_ADDRESS); // #define ISA_END_ADDRESS 0x100000
建立物理内存的直接映射。
//mr[0].start = 0; mr[0].end = 256 << 12; mr[0].page_size_mask =0, 对应于该函数的三个参数。
unsigned long __init
kernel_physical_mapping_init(unsigned long start,
unsigned long end,
unsigned long page_size_mask)
{
int use_pse = page_size_mask == (1<> PAGE_SHIFT; //起始页帧号0
end_pfn = end >> PAGE_SHIFT; //结束的页帧号256
mapping_iter = 1;
repeat:
pages_2m = pages_4k = 0;
pfn = start_pfn; //起始页帧号保存
//页全局目录索引,PAGE_OFFSET是0Xc000_0000,对应pgd_idx是0xc00即768,其意义是内核在全局目录项映射的第一个项索引是第768项。
pgd_idx = pgd_index((pfn< 3.2.2高端内区存固定映射初始化
高端内存域的初始化过程和低端内存初始化类似,但是只分配了页表,对应的PTE项并没有被初始化,初始化工作留到set_fixmap()函数建立相关页表和物理内存的关联。固定映射区分为几种索引类型,索引类型由枚举变量enum fixed_addresses定义,该初始化工作就是初始化这段区域。

图3.3.3
一个索引暂用一个4KB的页框,固定映射区的结束地址是FIXADDR_TOP,即0xfffff000(4G-4K),见图1.1。
static void __init
page_table_range_init(unsigned long start, unsigned long end, pgd_t *pgd_base)
{
int pgd_idx, pmd_idx;
unsigned long vaddr;
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte = NULL;
unsigned long count = page_table_range_init_count(start, end);
void *adr = NULL;
if (count)
adr = alloc_low_pages(count);
vaddr = start;
pgd_idx = pgd_index(vaddr);
pmd_idx = pmd_index(vaddr);
pgd = pgd_base + pgd_idx;
//遍历固定映射区,建立页表项
for ( ; (pgd_idx < PTRS_PER_PGD) && (vaddr != end); pgd++, pgd_idx++) {
pmd = one_md_table_init(pgd);
pmd = pmd + pmd_index(vaddr);
for (; (pmd_idx < PTRS_PER_PMD) && (vaddr != end);
pmd++, pmd_idx++) {
//建立PTE项,并检查vaddr是否对应内核临时映射区,若是则重新申请一个页表来保存PTE项。
pte = page_table_kmap_check(one_page_table_init(pmd),
pmd, vaddr, pte, &adr);
vaddr += PMD_SIZE;
}
pmd_idx = 0;
}
}3.2.3 persistent 内存初始化
图1.1中只剩下的是persistent memory初始化了。这一工作由图3.2.1中的paging_init完成。该函数还完成了解除虚拟内核0地址页的映射关系,这就是NULL指针所在的区域,用于异常捕捉。
void __init paging_init(void)
{
pagetable_init();
__flush_tlb_all();
kmap_init();
/*
* NOTE: at this point the bootmem allocator is fully available.
*/
olpc_dt_build_devicetree();
sparse_memory_present_with_active_regions(MAX_NUMNODES);
sparse_init();
zone_sizes_init();
} Persistent memory页表在pagetable_init函数分配,映射在kmap_init完成。
static void __init permanent_kmaps_init(pgd_t *pgd_base)
{
unsigned long vaddr;
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
vaddr = PKMAP_BASE;
//为persistent 内存分配页表
page_table_range_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
pgd = swapper_pg_dir + pgd_index(vaddr);
pud = pud_offset(pgd, vaddr);
pmd = pmd_offset(pud, vaddr);
pte = pte_offset_kernel(pmd, vaddr);
pkmap_page_table = pte; //persistent页表项保存
}
static void __init kmap_init(void)
{
unsigned long kmap_vstart;
/*
* Cache the first kmap pte:
*/
kmap_vstart = __fix_to_virt(FIX_KMAP_BEGIN);//persistent memory的物理地址到虚拟地址转换
kmap_pte = kmap_get_fixmap_pte(kmap_vstart); //获得固定映射区的临时映射页表项的起始项
kmap_prot = PAGE_KERNEL;
}3.3 per-CPU area 初始化
在图3.0.1中,setup_per_cpu_areas用于初始化per-CPU区域,将.data.percpu中的数据拷贝到每个cpu的数据段,在SMP情况下,per-CPU可以提高并发性,是免锁算法的一种,有利于提高系统性能,一个经典的应用是:
网卡接收到数据包存在若干个队列中,队列个数和CPU的个数是一样的,这样多个CPU可以并发访问各自的接收队列而不需要锁。
3.4 节点(node)和域(zone)初始化
在图3.2.1中,提到了native_pagetable_init函数,该函数将剩下页表的映射工作完成。
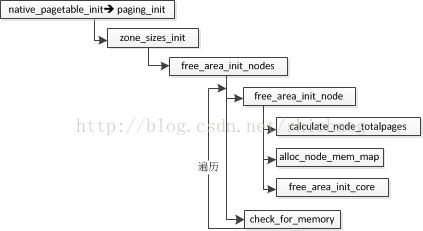
图3.3 节点初始化
对于node、zone和page的关系,从图2.2可以看出,这里涉及带代码分析如何完成这种内存管理拓扑的。zone_sizes_init函数还是很好理解的。
573 void __init zone_sizes_init(void)
574 {
575 unsigned long max_zone_pfns[MAX_NR_ZONES];
576
577 memset(max_zone_pfns, 0, sizeof(max_zone_pfns));
578
579 #ifdef CONFIG_ZONE_DMA
580 max_zone_pfns[ZONE_DMA] = MAX_DMA_PFN; // MAX_DMA_PFN=16M
581 #endif
582 #ifdef CONFIG_ZONE_DMA32//ia32未定义
583 max_zone_pfns[ZONE_DMA32] = MAX_DMA32_PFN;
584 #endif
585 max_zone_pfns[ZONE_NORMAL] = max_low_pfn; //max_low_pfn低端页帧的上限
586 #ifdef CONFIG_HIGHMEM
587 max_zone_pfns[ZONE_HIGHMEM] = max_pfn; //最大页帧号,用于高端内存
588 #endif
589
590 free_area_init_nodes(max_zone_pfns);
591 }free_area_init_nodes的参数是zone数组,其作用是初始化每一个node节点,
在mm/page_alloc.c文件定义了两个局部全局变量:
static unsigned long __meminitdata arch_zone_lowest_possible_pfn[MAX_NR_ZONES];
static unsigned long __meminitdata arch_zone_highest_possible_pfn[MAX_NR_ZONES];这两个变量用于标记每一个zone的起止边界页帧号。
5043 void __init free_area_init_nodes(unsigned long *max_zone_pfn)
5044 {
5045 unsigned long start_pfn, end_pfn;
5046 int i, nid;
5047
5048 /* 5048~5068确定每一个zone类型的起止页帧号 */
5049 memset(arch_zone_lowest_possible_pfn, 0,
5050 sizeof(arch_zone_lowest_possible_pfn));
5051 memset(arch_zone_highest_possible_pfn, 0,
5052 sizeof(arch_zone_highest_possible_pfn));
5053 arch_zone_lowest_possible_pfn[0] = find_min_pfn_with_active_regions();
5054 arch_zone_highest_possible_pfn[0] = max_zone_pfn[0];
5055 for (i = 1; i < MAX_NR_ZONES; i++) {
5056 if (i == ZONE_MOVABLE)
5057 continue;
5058 arch_zone_lowest_possible_pfn[i] =
5059 arch_zone_highest_possible_pfn[i-1];
5060 arch_zone_highest_possible_pfn[i] =
5061 max(max_zone_pfn[i], arch_zone_lowest_possible_pfn[i]);
5062 }
5063 arch_zone_lowest_possible_pfn[ZONE_MOVABLE] = 0;
5064 arch_zone_highest_possible_pfn[ZONE_MOVABLE] = 0;
5065
5066 /* Find the PFNs that ZONE_MOVABLE begins at in each node */
5067 memset(zone_movable_pfn, 0, sizeof(zone_movable_pfn));
5068 find_zone_movable_pfns_for_nodes();
5100 /*初始化每一个node */
//遍历每一个node
5103 for_each_online_node(nid) {
/**定义于include/linux/mmzone.h,对于单一节点,NODE_DATA定义如下:
#define NODE_DATA(nid) (&contig_page_data), 5104行的node节点
*/
5104 pg_data_t *pgdat = NODE_DATA(nid);
5105 free_area_init_node(nid, NULL,
5106 find_min_pfn_for_node(nid), NULL);
5107
5108 /* 如果node上存在页,则将其设置该node有内存状态为N_MEMORY,表示该node上有可用的内存。 */
5109 if (pgdat->node_present_pages)
5110 node_set_state(nid, N_MEMORY);
5111 check_for_memory(pgdat, nid);
5112 }
5113 }5015行的free_area_init_node第一个参数是node(节点)ID,第二个参数在zone的大小,第三个参数的是该zone的其实页帧号,最后一个参数是该zone的空洞大小,在3.10版本。Node的核心初始化函数是free_area_init_core;
4592 static void __paginginit free_area_init_core(struct pglist_data *pgdat,
4593 unsigned long *zones_size, unsigned long *zholes_size)
4594 {
4595 enum zone_type j;
4596 int nid = pgdat->node_id; //节点ID号
4597 unsigned long zone_start_pfn = pgdat->node_start_pfn; //该node的起始页帧号
4598 int ret;
4599
4600 pgdat_resize_init(pgdat); //热插拔情况内存量可能会变化,重新计算
4606 init_waitqueue_head(&pgdat->kswapd_wait); //换页守护进程队列头初始化。
4607 init_waitqueue_head(&pgdat->pfmemalloc_wait);//尽最大努力分配内存队列头初始化。
4608 pgdat_page_cgroup_init(pgdat); //node节点页cgroup初始化
4609 //迭代每一个zone
4610 for (j = 0; j < MAX_NR_ZONES; j++) {
4611 struct zone *zone = pgdat->node_zones + j;
4612 unsigned long size, realsize, freesize, memmap_pages;
4613 //j类型的zone的页总数,可能包含空洞
4614 size = zone_spanned_pages_in_node(nid, j, zones_size);
4615 realsize = freesize = size - zone_absent_pages_in_node(nid, j, //realsize是真实长度,减去了hole
4616 zholes_size);
4617
4618 /*调整页,将其按4KB边界对其,影响水印值。
4623 memmap_pages = calc_memmap_size(size, realsize);
4635 /*DMA预留内存保留,不会计入到zone里 */
4636 if (j == 0 && freesize > dma_reserve) {
4637 freesize -= dma_reserve;
4638 printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
4639 zone_names[0], dma_reserve);
4640 }
// nr_kernel_pages记录了DMA和NORMAL类型的页数,对不是高端内存情况需要加上。如果内核页足够多,需要进行调整,内核页的物理地址范围小于896M。
4642 if (!is_highmem_idx(j))
4643 nr_kernel_pages += freesize;
4644 /* Charge for highmem memmap if there are enough kernel pages */
4645 else if (nr_kernel_pages > memmap_pages * 2)
4646 nr_kernel_pages -= memmap_pages;
4647 nr_all_pages += freesize;
4648 //4649到4667初始化zone的相关成员
4649 zone->spanned_pages = size;
4650 zone->present_pages = realsize;
4656 zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
4663 zone->name = zone_names[j];
4664 spin_lock_init(&zone->lock);
4665 spin_lock_init(&zone->lru_lock);
4666 zone_seqlock_init(zone);
4667 zone->zone_pgdat = pgdat;
4668
4669 zone_pcp_init(zone); //zone的per-CPU成员初始化
4670 lruvec_init(&zone->lruvec);
4671 if (!size)
4672 continue;
4673
//伙伴系统的各阶初始化再次完成,从0阶到11阶
4676 ret = init_currently_empty_zone(zone, zone_start_pfn,
4677 size, MEMMAP_EARLY);
4678 BUG_ON(ret);
4679 memmap_init(size, nid, j, zone_start_pfn); //处理内存域中的page实例,将其标记为可移动的。
4680 zone_start_pfn += size;
4681 }
4682 }3.5 启用内核内存分配器
依然还是图3.0.1,这次是mm_init函数。
static void __init mm_init(void)
{
/*
* page_cgroup requires contiguous pages,
* bigger than MAX_ORDER unless SPARSEMEM.
*/
page_cgroup_init_flatmem();
mem_init();
kmem_cache_init();
percpu_init_late();
pgtable_cache_init();
vmalloc_init();
}
740 void __init mem_init(void)
741 {
742 int codesize, reservedpages, datasize, initsize;
743 int tmp;
761 /* this will put all low memory onto the freelists */
762 totalram_pages += free_all_bootmem(); //释放boot内存分配器
763
764 reservedpages = 0;
765 for (tmp = 0; tmp < max_low_pfn; tmp++)
769 if (page_is_ram(tmp) && PageReserved(pfn_to_page(tmp)))
770 reservedpages++;
771
772 after_bootmem = 1;
773
774 codesize = (unsigned long) &_etext - (unsigned long) &_text; //内核代码段
775 datasize = (unsigned long) &_edata - (unsigned long) &_etext; //
776 initsize = (unsigned long) &__init_end - (unsigned long) &__init_begin;下列dmesg出来的信息,就在该函数打印的。
[ 0.000000] Memory: 2044624K/2096632K available (6539K kernel code, 640K rwda
ta, 2764K rodata, 872K init, 924K bss, 52008K reserved, 1183624K highmem)
[ 0.000000] virtual kernel memory layout:
[ 0.000000] fixmap : 0xfff14000 - 0xfffff000 ( 940 kB)
[ 0.000000] pkmap : 0xffc00000 - 0xffe00000 (2048 kB)
[ 0.000000] vmalloc : 0xf83fe000 - 0xffbfe000 ( 120 MB)
[ 0.000000] lowmem : 0xc0000000 - 0xf7bfe000 ( 891 MB)
[ 0.000000] .init : 0xc19b9000 - 0xc1a93000 ( 872 kB)
[ 0.000000] .data : 0xc1663132 - 0xc19b8200 (3412 kB)
[ 0.000000] .text : 0xc1000000 - 0xc1663132 (6540 kB)kmem_cache_init初始化cache,vmalloc内存池初始化。
至此内存初始化流程结束。