唤醒词识别
我的书:

购买链接:
京东购买链接
淘宝购买链接
当当购买链接
本文就唤醒词的理解和Amazon,sensory以及Apple,google,公开的唤醒词方法做个梳理
sensory
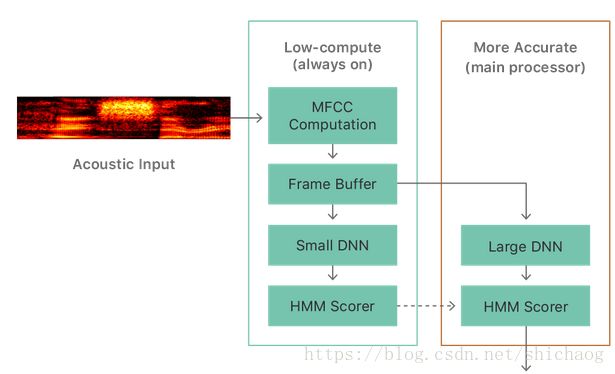
比较封闭的一家公司,sensory在树莓派上一个公开的数据是:
(采样率16KHz,16bit,ARMv7with neon)

在2018年5月其又推出不需要硬件加速的唤醒技术。
Apple
其在2017年10月发了篇文章讲述其在Applewatch和iPhone上的实现,2018年苹果也出了音响,是远场的,唤醒以及音效都挺好,文章讲述的是hey,Siri的识别技术,那时的技术基于DNN方法,将时域语音转到特征域,然后对特征进行模型的前向计算以获得概率分布,最终确定唤醒的概率。
采样率也是采用16KHz,对语音进行分段做STFT,段长约10ms。大约200ms时长的语音被送入声学模型中,DNN计算后语音特征被映射到预先分类好的声学特征类中,大约有20个类别。DNN模型主要包括的就是矩阵乘法(对于无浮点或者功耗考虑是可以进行量化的)和非线性运算(也有的模型还需要采用normalization),最后一层的非线性常常采用softmax进行分类(mcu级别的也可以对其进行简化)。
Hey Siri的识别模型如下:
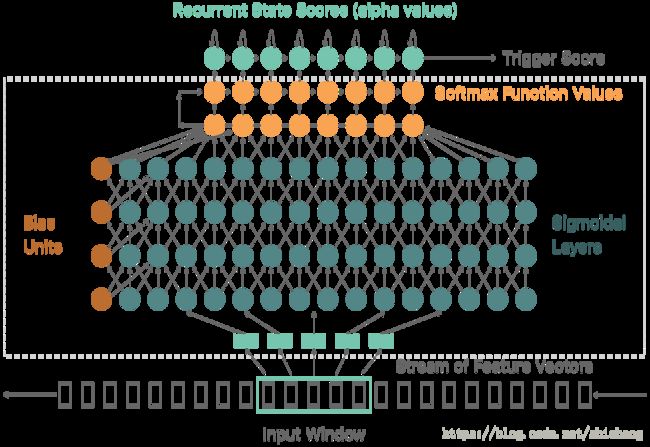
其hiddenlayer的层数通常采用五层,神经元的size取相同的,根据不同的硬件配置选择32,128或者192.该模型最后映射的是声学模型计算的发音概率,这里的发音不是音素级别的,也不是指单词级别的,而是介于音素和单词之间的多个音素的结合体(是音节或者比音节更大一些),在汉语中基本上一个汉子就是一个音节,音节有声母和韵母组成,汉语无音调音节有400多个,带语调的有1300多个。为了便于识别,Apple选的词siri(['si:ri])的前后元音都在里面。
![]()
个人觉得 这个选择非常务实,非常为用户考虑。
而且选择了两个谐振较为明显的前后元音。那么基于音节粒度的识别会存在一个问题,200ms没法把完整的”HeySiri”的特征全部囊括进去,但是这里softmax的输出却是指明有没有唤醒,这通过增加RNN层(黄色的两层)来实现的,这样就保留的序列的时间关联性。RNN层的实现如下:
$$F_{i,t}=max{s_i+F_{i,t-1},m_{i-1}+F_{i-1, t-1}}+q_{i,t}$$
其中:
F_{i,t}是声学模型累计得分值,q_{i,t}是声学模型输出(音节的对数得分),s_i是处在状态i的代价,m_i是从状态i转移的代价。s_i和m_i是根据训练集中数据分段时长确定的(和HMM的状态转移类似)。
公式的实现如上图。手机上的完整实现如下:
唤醒词“okgoogle”,据说是根据《SMALL-FOOTPRINTKEYWORD SPOTTING USING DEEP NEURALNETWORKS》这篇文章,不过google出了好几篇文章,并且为了推广他们的tensorflow,自带了kws的例子,其基于词级别的识别。识别架构如下:
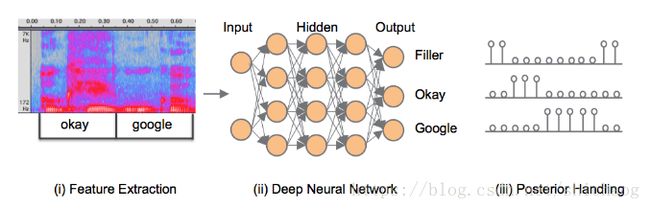
为了减少功耗,这里多了一个VAD模块,将13维的PLP特征及其一阶和二阶delta值输入训练过的有30个分量(正交基)的对角协方差GMM模型,该模型的输出就是是否是语音,然后之后会外接一个滑动处理的状态机。
当VAD模块检测到是语音的时候,对25ms的语音数据计算40维的log-fbank,滑动窗长选择了10ms。
其对后验概率的处理以及平滑策略有些差异。
其它常用网络模型
由于CNN能够处理更细节的时频信息;所以在很多场景中都会遇到使用CNN的场景,但是CNN有个比较大的缺点就是计算量大,所以会使用depth-wise之类的变种以降低运算量,在实际使用中也有将多个模型混合在一起使用,比如CNN+RNN,DNN+RNN,RNN有LSTM和GRU结构。除了上面的模型还有基于CTC的kws识别网络。相关的paper都有。我绝对对于入门者而言,不应该问“到底那种网络结构好”这类的问题。
NN方法的个人理解
在上述网络结构图中,出现的最多的就是圆圈,这些圆圈基本就是矩阵乘加以及非线性运算。这些圈的背后意义我的理解是:正交基。
太阳光照射的物理反射和自身颜色一样的光而吸收(不会完全吸收)其它颜色的光,如果要问一个辣椒(假设只有红色,黄色和绿色)是什么颜色的,那么就可以用x,y,z三个正交基来分别表示红色,黄色和绿色,我们可以采集辣椒反射的太阳光谱,分别求反射光谱属于x,y,z三个坐标轴上的值,可以知道对于红色辣椒,其得到的x分量肯定大于y,z方向上的分量。对于其它颜色的辣椒类似。则一个辣椒的颜色就可以使用具有三个正交基解决。这是可以把网络的输入看成是光谱的特征,圈圈表示的网络就是在提取其在三个正交基x,y,z上的分量,最后的非线性输入就是惩罚和奖励各个正交基上的分量。
对于七色的物理颜色识别问题,则可以使用具有七个正交基来解决。对于使用音节做为识别单位的ASR系统可以使用1300(中文约有1300个带声调的音节)个正交基来识别。所以所有的问题都可以划分为找到正确的正交基数量,并且让其正交。
回到网络模型中的圈圈,这些圈圈之间可以是正交的,层于层之间的圈圈也可以正交的,所以可以知道对于一个每层具有64个圈圈(神经元),共三层的这种层级的结构可达的正交基的数量是:
64*64×64(1层和2层)这么多个正交基,在网络模型训练时会采用非线性隔开层与层之间的强联系,所以正交基的数量约有64*64*2这么多,这么一个小小的模型就有这么多正交基已经非常不错了。
现在的正交基获取方式是使用Adam,SGD随机梯度方法+训练数据的方法,由于数据并不能涵盖显现实生活中的所有场景(所有正交基),也有方法弥补SGD方法的不足,如dropout,normalization等,但是这使得得到的正交基大大折扣。
针对语音场景弥补正交基不足现在采用的方法主要是前端语音增强,外加追求覆盖使用场景的语料,以及模型改进,语音增强主要就是抑制噪声,混响以及自身音源的影响,追求覆盖使用场景的语料一方面是录一方面是针对使用场景的人为加噪声。如何在模型上改进也是值得尝试的,如早期使用DNN方法,后来使用CNN+DNN就是人为减小了获取正交基的难度,模型的改进牵涉到特征的选取,时频特征现在是基本都会采用的特征,那么时域到频域的窗长该如何选择,窗长滑动该如何选取,加噪声的影响,使用MFCC还是log-fbank。
当然还要考虑的一个非常重要的影响就是实现的硬件平台的资源情况,谁都知道对于kws场景两层CNN要比不用CNN好,但是增加的参数量和运算量可是可能翻了翻,尽管使用了如8比特量化,利用硬件的SIMD特性,有些场景还是无法使用的。