学习笔记|Doc2Vec
更新内容(2018-12-1):
一些论文的复现代码已开源在GIthub上:
地址:https://github.com/shillyshallysxy/Learning_NLP
前言
前段时间在看Doc2Vec,但一段时间的浏览后发现大多博客是对原论文的思路进行讲解,对于其具体如何的实现以及更细节一些的东西,博主还是懵懵懂懂,想着大概是大家都心领神会了。为了给和博主有一样情况的朋友一些帮助,翻阅了一些材料,将Doc2Vec中的PV-DM的一种实现方法写了下来,以便大家直观的看到这个模型是怎么工作的(一种工作方式)以便大家理解论文中的思路。
Doc2Vec论文的链接:https://cs.stanford.edu/~quocle/paragraph_vector.pdf
想要阅读原论文的读者,可以点击上面的链接。
看到这里的读者,博主姑且默认已经知道Word2Vec的工作方式了,按照博主的理解,Word2Vec的工作简单阐述就是将单词转换为词向量,并且这些词向量可以一定程度的表达单词之间的语义关系,各种方法各有优劣,具体在这里不再赘述。
如果还不知道Word2Vec是什么,关于Word2Vec的知识,这位博主的博客给了我很多的帮助,链接:https://blog.csdn.net/itplus/article/details/37969519,相信研读完能有很大的帮助。
或者参考该论文:https://arxiv.org/abs/1310.4546
Doc2Vec
论文思路是在word2vec的基础上,加入段落主题这个属性的考量
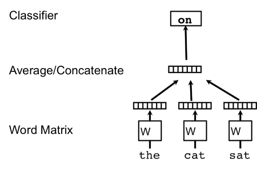
盗用原论文中的图片,即:


举一个例子,当在段落1中 描述的是 “大家出门郊游野餐”,段落2描述的是 ”我在开会“这类主题 时,在给出上下文 “我坐在__” 让模型预测下一个单词。
对于Word2Vec来说,就不会考量段落1或是段落2的语境和主题,模型也许会认为 “坐在椅子上” 在训练集中出现的最多,所以大概是坐在 “椅子上” 最有可能?他也不知道。 但对于Doc2Vec来说,同时跟随上下文输入的还有一个代表了本段落的主题的Vector,比如当一起输入的是代表着段落1的Vector时,那很有可能预测是 “草上" 或 ”地上“ 这类单词,当然也有可能是坐在 ”椅子上“, 当一起输入的是段落2的Vector时,更有可能预测是坐在 ”椅子上“ ,开会的时候 ”坐在草上“ 或是 ”坐在地上“ 就显得不太合理(笑)。
那要如何实现他呢?
按照段落区分主题,这里给出了一个比较简单的方法:
声明几个变量 embedding_size(词向量的长度, 可以根据自己的需求自行设置,越大单词就被映射到越高维的空间,表达能力越强),vocabulary_size(总单词种类的数量),每个单词都有自己的词向量 shape = [1, embedding_size]
如上图,Word2Vec中的average方法,输入上下文词向量,得到输入向量 shape = [1, embedding_size](average方法,所以求平均),经过权重矩阵 shape = [embedding_size, vocabulary_size] 和偏置矩阵 shape = [1, vocabulary_size] 通过Nec-loss得到预测输出每个单词的概率的向量 shape = [1, vocabulary_size] 。
至于Doc2Vec,这里只需要对Word2Vec进行一些小更改就行了,按照不同的段落,新增一个矩阵,段落向量矩阵 shape = [doc_size, doc_embedding_size],doc_embedding_size(段落向量的长度, 可以根据自己的需求自行设置),doc_size(文中段落的数量)。
每个段落拥有自己的段落向量 shape = [1, doc_embedding_size],对于每次训练,这里选择联结(concatenate)的方式,将Word2Vec中的输入词向量与输入词向量所属的段落向量联结,最终输入向量变为 shape = [1, embedding_size+doc_embedding_size],同样,小小的更改权重矩阵,经过权重矩阵 shape = [embedding_size+doc_embedding_size, vocabulary_size] 和偏置矩阵 shape = [1, vocabulary_size] 通过Nec-loss得到预测输出每个单词的概率的向量 shape = [1, vocabulary_size]。
训练过程就是不断更新 段落向量矩阵(shape = [doc_size, doc_embedding_size]) 和 词向量矩阵([Vocabulary_size, embedding_size]) 的过程了。训练出来的 embedding 就可以用于后续的 比如情感预测,垃圾短信过滤之类的任务中了!
这样就完成了一个简单的Doc2Vec !
希望对在学习中的大家有所帮助。
最后附上实现的部分代码:
声明一些变量和方法:
sess = tf.Session()
# Declare model parameters
batch_size = 500
vocabulary_size = 7500
generations = 100000
model_learning_rate = 0.001
embedding_size = 200
doc_embedding_size = 100
concatenated_size = embedding_size + doc_embedding_size
num_sampled = int(batch_size/2) # Number of negative examples to sample.
window_size = 3
def normalize_text(texts, stops):
texts = [x.lower() for x in texts]
texts = [''.join(c for c in x if c not in string.punctuation) for x in texts]
texts = [''.join(c for c in x if c not in '0123456789') for x in texts]
texts = [' '.join([word for word in x.split() if word not in (stops)]) for x in texts]
texts = [' '.join(x.split()) for x in texts]
return(texts)
# Build dictionary of words
def build_dictionary(sentences, vocabulary_size):
split_sentences = [s.split() for s in sentences]
words = [x for sublist in split_sentences for x in sublist]
count = [['RARE', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size-1))
word_dict = {}
for word, word_count in count:
word_dict[word] = len(word_dict)
return(word_dict)
# Turn text data into lists of integers from dictionary
def text_to_numbers(sentences, word_dict):
# Initialize the returned data
data = []
for sentence in sentences:
sentence_data = []
for word in sentence.split():
if word in word_dict:
word_ix = word_dict[word]
else:
word_ix = 0
sentence_data.append(word_ix)
data.append(sentence_data)
return(data)
# Generate data randomly (N words behind, target, N words ahead)
def generate_batch_data(sentences, batch_size, window_size, method='skip_gram'):
# Fill up data batch
batch_data = []
label_data = []
while len(batch_data) < batch_size:
rand_sentence_ix = int(np.random.choice(len(sentences), size=1))
rand_sentence = sentences[rand_sentence_ix]
window_sequences = [rand_sentence[max((ix-window_size),0):(ix+window_size+1)] for ix, x in enumerate(rand_sentence)]
label_indices = [ix if ix主体:
# load data
texts, target = text_helpers.load_movie_data()
# Normalize text
texts = text_helpers.normalize_text(texts, stops)
# Texts must contain at least 3 words
target = [target[ix] for ix, x in enumerate(texts) if len(x.split()) > window_size]
texts = [x for x in texts if len(x.split()) > window_size]
# Build our data set and dictionaries
word_dictionary = text_helpers.build_dictionary(texts, vocabulary_size)
word_dictionary_rev = dict(zip(word_dictionary.values(), word_dictionary.keys()))
text_data = text_helpers.text_to_numbers(texts, word_dictionary)
# Define Embeddings:
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
doc_embeddings = tf.Variable(tf.random_uniform([len(texts), doc_embedding_size], -1.0, 1.0))
# NCE loss parameters
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, concatenated_size],
stddev=1.0 / np.sqrt(concatenated_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
# Create placeholders
x_inputs = tf.placeholder(tf.int32, shape=[None, window_size + 1]) # plus 1 for doc index
y_target = tf.placeholder(tf.int32, shape=[None, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Lookup the word embedding
# Add together element embeddings in window:
embed = tf.zeros([batch_size, embedding_size])
for element in range(window_size):
embed += tf.nn.embedding_lookup(embeddings, x_inputs[:, element])
doc_indices = tf.slice(x_inputs, [0,window_size],[batch_size,1])
doc_embed = tf.nn.embedding_lookup(doc_embeddings,doc_indices)
# concatenate embeddings
final_embed = tf.concat(axis=1, values=[embed, tf.squeeze(doc_embed)])
# Get loss from prediction
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=y_target,
inputs=final_embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
# Create optimizer
optimizer = tf.train.GradientDescentOptimizer(learning_rate=model_learning_rate)
train_step = optimizer.minimize(loss)
# Cosine similarity between words
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
# Create model saving operation
saver = tf.train.Saver({"embeddings": embeddings, "doc_embeddings": doc_embeddings})
#Add variable initializer.
init = tf.global_variables_initializer()
sess.run(init)
for i in range(generations):
batch_inputs, batch_labels = text_helpers.generate_batch_data(text_data, batch_size,
window_size, method='doc2vec')
feed_dict = {x_inputs : batch_inputs, y_target : batch_labels}
# Run the train step
sess.run(train_step, feed_dict=feed_dict)