用python3实现简单的语音识别转化成文字
自己对python感兴趣,利用业余时间弄了个自动回复微信消息的小机器人,纯属自己瞎玩,给大家介绍一下,有想自己弄着玩的可以做个参考,项目地址:https://github.com/shiyusong39/WeChatSimpleRobot
以python3为基础语言,用到了 itchat +谷歌的语音识别+思知机器人API+pydub类库。简单说下:
1.itchat
他的开发者介绍说这是实现了一个伪web的微信,但不是微信官方推荐的,所以频繁使用可能会被微信限制web端登陆,不影响手机和客户端的登陆。基本web半微信实现的功能,itchat好像都能实现,直接上官网:https://itchat.readthedocs.io/zh/latest/
下面是我写的python(请大家忽略命名和格式,一时之间从java那边转换不过来,还不习惯~)先下包:
我用的PyCharm,而且已经安装了pip,所以我直接就:pip install itchat 执行命令就哦了,然后再代码中引入就可以了:
import itchat
from itchat.content import *
import time#微信热启动
itchat.auto_login(hotReload=True)
itchat.run()
##个人聊天
#文本信息
@itchat.msg_register([itchat.content.TEXT,itchat.content.RECORDING],isFriendChat=True)
def private_text_chat(private_msg):
# filehelper 是文件传输助手,我是为了测试用的
if private_msg['ToUserName'] == 'filehelper' :
#获取好友昵称
nick_name = '自己'
from_user_name = 'filehelper'
else:
nick_name = private_msg['User']['NickName']
from_user_name = private_msg['FromUserName']
msg = private_msg['Text']
print(nick_name +":"+msg)
#请求机器人
replymsg = SiZhiRobot.sizhi_msg(msg)
#返回消息
itchat.send(msg = replymsg, toUserName = from_user_name)
回复群消息和群发的方法我就不在这里展示了,都比较简单,大家看看官方api就能明白。2.思知机器人
十分的感谢开源的大佬们!!,一开始我使用的是图灵机器人,但是那个需要真人认证,比较麻烦,而且试用版只能创建五个机器人,每个机器人每天有100次还是多少次的使用次数记不太清了。然后我同事帮我找打了思知机器人,目前来说,响应速度快,调用简单回复消息结构也简单,只是有的时候回答的不是很准确,但是自己玩也可以了(毕竟我刚弄完这个机器人那阵,我同事能跟它玩一下午-_-!),申请没那么多要求,附上官网:https://www.ownthink.com/,上代码:
import json
import requests
#思知机器人API
def get_sizhi_response(msg):
apiUrl = 'https://api.ownthink.com/bot'
apiKey = 'xxxxxxxxxx'#这里填写你自己申请的机器人apiKey
data = {
"spoken": msg,
"appid": apiKey,
"userid": 'fireworks'#随便起的
}
# 必须是json
headers = {'content-type': 'application/json'}
try:
req = requests.post(apiUrl, headers = headers, data = json.dumps(data))
return req.json()
except:
return
#处理思知机器人返回的json消息
def sizhi_msg(msg):
#设置一个默认回复。
return_msg = '我是个笨笨的机器人,我CPU好像挂了~_~![自动回复]'
replyjson = get_sizhi_response(msg)
if replyjson['message'] == 'success':
return_msg = replyjson['data']['info']['text'].replace('小思','伦家~').replace('思知机器人','伦家~');
print("思知机器人自动回复:"+return_msg)
# a or b --》 如果a不为空就返回a,否则返回b
return return_msg3.微信语音消息的保存及格式的转变
在微信返回的消息中,语音消息的类型是43,而且保存到本地是mp3的格式(我不清楚是否可以指定保存格式,按照itchat的文档介绍保存到本地是mp3格式);MP3的音频文件不能直接用谷歌的语音识别去识别,可以看下这篇文章(https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/79832700这里面介绍了有关音频的一些理论知识,什么频率赫兹啥的),包括谷歌语音识别接口的使用;所以,在识别语音之前,我们要先对保存到本地的语音消息转化格式,这里用到了pydub的ffmpeg和ffprobe(https://ffmpeg.zeranoe.com/builds/下载完解压,ffmpeg.exe和ffprobe.exe复制到你想放的地方,然后再代码中引用一下就可以了,windows平台可以,不止linux是否可以)先下类库:
pip install pydub
pip install os
再看代码:
from pydub import AudioSegment
import os
from os import path
# os.getcwd() 是获取当前路径,这里可以写绝对路径
AudioSegment.ffmpeg = os.getcwd()+'\\ffmpeg.exe'
AudioSegment.ffprobe = os.getcwd()+'\\ffprobe.exe'
def dealMp3(filePath,fileName):
sound = AudioSegment.from_mp3(filePath)
#获取原始pcm数据
data=sound._data
sound_wav = AudioSegment(
#指定原始pcm文件
# raw audio data (bytes)
data = data,
#指定采样深度,可选值1,2,3,4
# 2 byte (16 bit) samples
sample_width = 2,
#指定采样频率
# 44.1 kHz frame rate
# 16kHz frame rate
frame_rate = 16000,
#指定声道数量
# stereo or mono
channels = 1
)
#导出wav文件到当前目录下
sound_wav.export(fileName,format='wav')
# 判断生成wav格式的文件成功没
isDeal = os.path.exists(os.getcwd()+'\\'+fileName)
#如果wav文件生成了就删除mp3文件 - -这个可以不参考
if isDeal:
#删除mp3文件
os.remove(filePath)
return isDeal4.语音转文字
将微信语音文件转化完格式后,就可以进行语音识别了,在这先提前说下,谷歌的识别十分慢,具体原因咱也不知道,国内像百度、讯飞、微信也有语音识别的开放平台API,如果觉得慢,也可以考虑使用国内的,不管使用哪种语音识别,这个mp3转wav都会用到,不能直接对mp3类型的文件进行识别。下载类库:
pip install SpeechRecognition
代码:
import speech_recognition as sr#语音转文字
def voice2Text(file_name):
voice_file = path.join(path.dirname(path.realpath(__file__)), file_name)
# use the audio file as the audio source
r = sr.Recognizer()
with sr.AudioFile(voice_file) as source:
audio = r.record(source)
try:
content = r.recognize_google(audio, language='zh-CN')
# print("Google Speech Recognition:" + content)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Google Speech Recognition error; {0}".format(e))
return content or '无法翻译'这个就是转文字的代码,这只是其中一种方法,其他更多的demo可以去看https://github.com/Uberi/speech_recognition/blob/master/examples/audio_transcribe.py,这里面需要注意的是,首先要设定一下content = r.recognize_google(audio, language='zh-CN')的language,因为他默认是英语~,zh-CN将我们的音频转化成简体中文;在一个就是audio这个参数,谷歌api说他的翻译只接受SpeechRecognition类型的,所以
with sr.AudioFile(voice_file) as source:
audio = r.record(source)
这个是读取到我们的wav音频文件然后调用record方法将内容处理后输出到audio这个参数中。OK了,基本上没啥问题了,可以测试了,我的基本流程就是登录微信,然后自己发语音给文件传输助手,然后python处理语音转化成文字,再去请求机器人,回复给我消息。
测试结果:
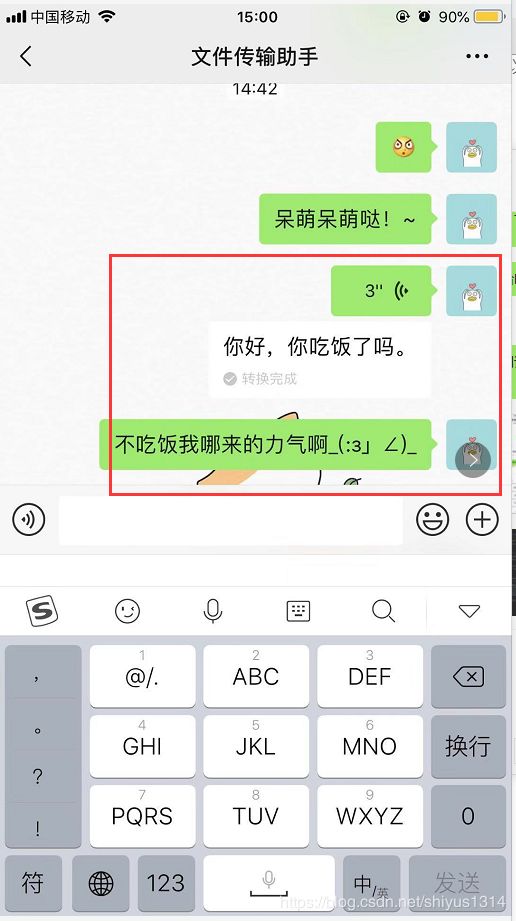

成功了!这个其实没有什么特别高的技术含量,就是整合各种第三方类库和api,做这个纯属娱乐和兴趣使然,当然了,也在里面学到不少知识,可以搞好多有趣的东西,比如:在群聊中怎么判断是不是自己发的消息?怎么定时群发好友或者群?怎么给他/她每天定时发一些腻歪的话?怎么防止朋友撤回消息。。。等等
如果有不准确的地方,还希望大家多多指教批评!
2020.04.29补充:
有朋友反馈说不能使用了,我测试了一下,是谷歌的语音翻译API被墙了,我挂上VPN之后可以使用的,我把这个demo简化了一下,代码已经更新到github上了,如果没有,大家可以使用国内的百度语音翻译、腾讯语音翻译以及科大讯飞语音翻译,只不过这些有免费次数超过之后要收费,如果有问题大家多多交流~谢谢大家的支持!