8个常用的正则表达式
本文是博主从tutsplus 看到 的一篇文章,对于新手入门来说,还是非常棒的博文,就整理一下。八张图带你入门正则表达式。
原博连接:https://code.tutsplus.com/tutorials/8-regular-expressions-you-should-know–net-6149
正则表达式基础语法实例详解:http://blog.csdn.net/shuai_wy/article/details/54340834
常用正则表达式: http://c.biancheng.net/cpp/html/1433.html
前四条都比较简单(若有问题,可以先去看一下基础语法),重点说一下后面的四个正则表达式,后面的正则中有我写的优化实例,都是我多次运行验证过的,大家可以参考。
note:一下的例子呐,都是以单个匹配为实例的,如果大家想要匹配出一段文本中的字段,注意请去除^(以什么开始) 和 $(以什么结束)
1、匹配用户名
/^[a-z0-9_-]{3,16}$/
2、匹配密码
/^[a-z0-9_-]{6,18}$/
3、匹配十六进制
/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
4、匹配Slug
我也不知道,这是个啥,比较简单,匹配了小写字母、数字、和连接符
/^[a-z0-9-]+$/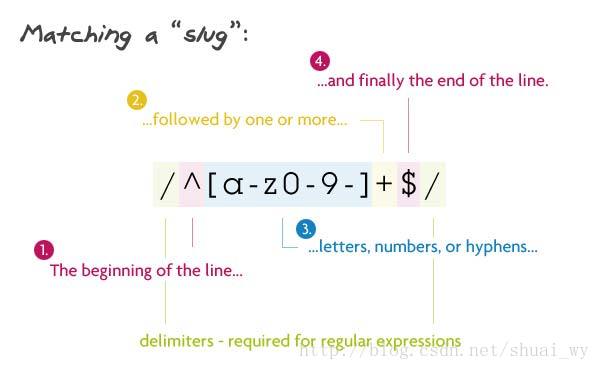
5、匹配Email地址
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
6、匹配URL
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
实例:
$str = "http://www.fang.com/ask/search.html?Title=regex&author=wys";
$reg = "/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w\.-]*)(\?\w*=.*)?/";
//优化以后的正则,功能更加强大。
if (preg_match_all($reg,$str,$arr,2)) {
echo ""
;
var_dump($arr);
echo "运行结果:
array(1) {
[0]=>
array(6) {
[0]=>
string(59) "http://www.baidu.com/ask/search.html?Title=regex&author=wys"
[1]=>
string(7) "http://" //https?匹配协议
[2]=>
string(9) "www.baidu" // ([\da-z\.-]+) 匹配网址
[3]=>
string(3) "com" //匹配顶级域名 ([a-z\.]{2,6})
[4]=>
string(16) "/ask/search.html" //匹配路径 ([\/\w\.-]*)
[5]=>
string(23) "?Title=regex&author=wys" // 匹配参数 (\?\w*=.*)?
}7、匹配IP地址
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
8、HTML标签
/^<([a-z]+)([^<]+)*(?:>(.*)<\/\\1>|\s+\/>)$/
注意:
正则表达式,我直接使用了原博中提供的表达式。
如果你要匹配 一个html标签,比如: