为什么用线程池?
-
例子,10年前单核CPU电脑,假的多线程,像马戏团小丑玩多个球,CPU需要来回切换。现在是多核电脑,多个线程各自跑在各自独立的CPU上,不用切换效率高。
-
线程池的优势:线程池做的工作只是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
-
特点:线程复用;控制最大并发数;管理线程;
-
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
-
提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
-
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
-
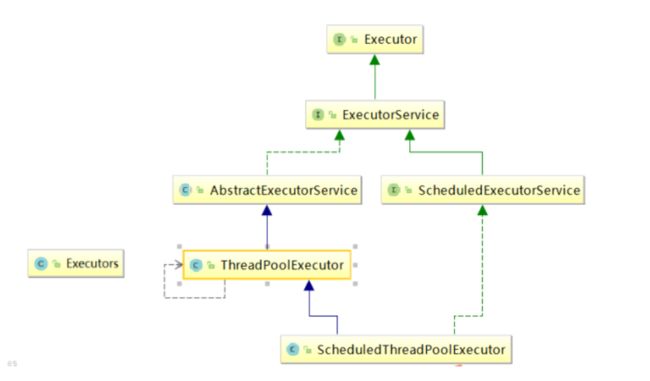
架构说明:Java中的线程池是通过 Executor 框架实现的,该框架中用到了Executor、Executors、ExecutorService、ThreadPoolExecutor 这几个类;
一. Executors.newFixedThreadPool(Int i)
执行长期任务性能好,创建一个线程池,一池有 N 个固定的线程,有固定线程数的线程
二. Executors.newSingleThreadPool()
一个任务一个任务的执行
三. Executors.newCachedThreadPool()
执行很多短期异步任务,线程池根据需要创建新线程,但在先前构建的线程可用时将重用它们,可扩容性强,遇强则强。
package juc; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * @author : 雪飞oubai * @date : 2020/3/28 15:53 */ public class MyThreadPoolDemo { public static void main(String[] args) { // 一池 5 个受理线程,类似一个银行有 5 个受理窗口 ExecutorService threadPool1 = Executors.newFixedThreadPool(5); // 一池 1 个受理线程,类似一个银行有 1 个受理窗口 ExecutorService threadPool2 = Executors.newSingleThreadExecutor(); // 一池 N 个受理线程,类似一个银行有 N 个受理窗口 ExecutorService threadPool3 = Executors.newCachedThreadPool(); try { // 模拟有 10 个顾客过来银行办理业务,目前池子里面有 5 个工作人员提供服务 for (int i = 0; i < 10; i++) { threadPool1.execute(() -> { System.out.println(Thread.currentThread().getName() + "\t 办理业务"); }); } } catch (Exception e) { e.printStackTrace(); } finally { threadPool1.shutdown(); } } }
ThreadPoolExecutor 底层原理:
/** * Creates a thread pool that reuses a fixed number of threads * operating off a shared unbounded queue. At any point, at most * {@code nThreads} threads will be active processing tasks. * If additional tasks are submitted when all threads are active, * they will wait in the queue until a thread is available. * If any thread terminates due to a failure during execution * prior to shutdown, a new one will take its place if needed to * execute subsequent tasks. The threads in the pool will exist * until it is explicitly {@link ExecutorService#shutdown shutdown}. * * @param nThreads the number of threads in the pool * @return the newly created thread pool * @throws IllegalArgumentException if {@code nThreads <= 0} */ public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()); } /** * Creates an Executor that uses a single worker thread operating * off an unbounded queue. (Note however that if this single * thread terminates due to a failure during execution prior to * shutdown, a new one will take its place if needed to execute * subsequent tasks.) Tasks are guaranteed to execute * sequentially, and no more than one task will be active at any * given time. Unlike the otherwise equivalent * {@code newFixedThreadPool(1)} the returned executor is * guaranteed not to be reconfigurable to use additional threads. * * @return the newly created single-threaded Executor */ public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue ())); } /** * Creates a thread pool that creates new threads as needed, but * will reuse previously constructed threads when they are * available. These pools will typically improve the performance * of programs that execute many short-lived asynchronous tasks. * Calls to {@code execute} will reuse previously constructed * threads if available. If no existing thread is available, a new * thread will be created and added to the pool. Threads that have * not been used for sixty seconds are terminated and removed from * the cache. Thus, a pool that remains idle for long enough will * not consume any resources. Note that pools with similar * properties but different details (for example, timeout parameters) * may be created using {@link ThreadPoolExecutor} constructors. * * @return the newly created thread pool */ public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue ()); }
线程池的几个重要参数:
-
corePoolSize:线程池中的常驻核心线程数;
-
maximumPoolSize:线程池中能够容纳同时执行的最大线程数,此值必须大于等于1;
-
keepAliveTime:多余的空闲线程的存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到剩下corePoolSize个线程为止;
-
unit:keepAliveTime的单位;
-
workQueue:任务队列,被提交但尚未被执行的任务;
-
threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认即可;
-
handler:拒绝策略,表示当队列满了,并且工作线程大于等于线程池(maximumPoolSize)时,如何来拒绝请求执行的runnable策略;
/** * Creates a new {@code ThreadPoolExecutor} with the given initial * parameters. * * @param corePoolSize the number of threads to keep in the pool, even * if they are idle, unless {@code allowCoreThreadTimeOut} is set * @param maximumPoolSize the maximum number of threads to allow in the * pool * @param keepAliveTime when the number of threads is greater than * the core, this is the maximum time that excess idle threads * will wait for new tasks before terminating. * @param unit the time unit for the {@code keepAliveTime} argument * @param workQueue the queue to use for holding tasks before they are * executed. This queue will hold only the {@code Runnable} * tasks submitted by the {@code execute} method. * @param threadFactory the factory to use when the executor * creates a new thread * @param handler the handler to use when execution is blocked * because the thread bounds and queue capacities are reached * @throws IllegalArgumentException if one of the following holds:
* {@code corePoolSize < 0}
* {@code keepAliveTime < 0}
* {@code maximumPoolSize <= 0}
* {@code maximumPoolSize < corePoolSize} * @throws NullPointerException if {@code workQueue} * or {@code threadFactory} or {@code handler} is null */ public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueueworkQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
线程池底层工作原理:

-
在创建了线程池后,开始等待请求;
-
当调用 execute() 方法添加一个请求任务时,线程池会做出如下判断:
-
如果正在运行的线程数量小于 corePoolSize,那么马上会创建线程运行这个任务;
-
如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
-
如果这个时候队列满了且正在运行的线程数量还小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
-
如果队列满了且正在运行的线程数量大于或等于 maximumPoolSize, 那么线程池会启动饱和拒绝策略来执行;
-
-
当一个线程完成任务时,他会从队列中取下一个任务来执行;
-
当一个线程无事可做查过一定时间(keepAliveTime)时,线程会判断:
-
如果当前运行的线程数大于 corePoolSize,那么这个线程就会被停掉;
-
所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小;
-
线程池用哪一个?生产中如何设置合理参数?
-
在工作中单一的 / 固定数的 / 可变的三种创建线程池的方法那个用的多?超级大坑
答案:一个都不用,我们工作中只用自定的;
Executors 中 JDK 已经给你提供了,为何不用?

2. 在工作中如何使用线程池,是否自定义过线程池?
package juc; import java.util.concurrent.*; /** * @author : 雪飞oubai * @date : 2020/3/31 15:48 */ public class MyThreadPoolDemo2 { public static void main(String[] args) { ExecutorService threadPool = new ThreadPoolExecutor(2, 5, 2L, TimeUnit.SECONDS, new ArrayBlockingQueue(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); try { for (int i = 0; i < 5; i++) { threadPool.execute(() -> { System.out.println(Thread.currentThread().getName() + "\t 办理业务"); }); } } catch (Exception e) { e.printStackTrace(); } finally { threadPool.shutdown(); } } }
线程池的拒绝策略:
是什么:等待队列已经排满了,再也塞不下新任务了,同时线程池中的 max 线程也到了数量,无法继续为新任务服务;这个时候我们就需要拒绝策略机制合理的处理这个问题;
JDK内置的拒绝策略:
-
AbortPolicy(默认):直接抛出 RejectedExecutionException 异常阻止系统正常运行;
-
CallerRunsPolicy:“调用者运行”一种调节机制,个策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量;
-
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入到队列中,尝试再次提交当前任务;
-
DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常,如果允许任务丢失,这是最好的一种策略;
如何设置 maximumPoolSize 的值?
-
一般是 cpu 核数 +1 或 2;