推荐系统-隐因子模型(LFM)
今天我们来聊一聊LFM(Latent Factor Model)的故事,这也算是我们在推荐系统里第一个用到的学习算法了吧,前面讲的两个协同过滤都是基于统计来的。
协同过滤的思路就是基于用户和物品的交互行为,要么计算用户间的相似度,推荐相似度高的用户喜欢的物品,因为这两个用户可能兴趣相投;要么就是计算物品间的相似度,推荐和历史记录相似度很高的物品,因为他们可能属于同一类别的商品。我们做决策的基础都是默认了商品是有类别的,可能有的用户都喜欢某一类商品,所以这些用户之间相似度高,可能有的商品是属于同一类别的,因此这些商品的相似度很高。那既然这样,有没有可能直接得到商品的类别呢?这样我们就可以直接根据类别去进行推荐了~
LFM就是基于这样的想法,假设商品存在若干个种类,那么每个用户对每个类会有一个兴趣度,同样的,每个类内又有若干种商品,每个商品在这个类内又会有一个对应的权重。这样,对于任何一个用户-商品对,我们都可以用下述公式来表达
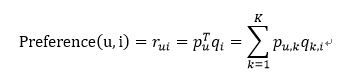
OK,那么下一步就是去计算矩阵P和Q,最常见的方法就是在训练集上不停迭代更新参数直至参数收敛。既然需要迭代,那我们得有一个损失函数或者目标函数作为我们迭代的依据,这里我们选用的是最常见的预测值和实际值差值的平方和,并且加上了正则项防止过拟合,具体如下

熟悉机器学习的同学应该很清楚,接下来就是基于梯度下降去优化这个损失函数,这里就不赘述了。但是我们还有一个问题,对于显式反馈的数据,我们直接用评分数据作为训练集,但是对于隐式反馈而言,只有正样本,我们可以把这些数据标注为1,但同时我们也需要负样本,所以往往需要我们从所有样本里选择样本构建负样本集。这里在构建负样本的时候有一个小小的trick,要尽量选择那些非常热门但是用户却没有发生交互的物品,因为这样构建的样本往往更具有代表性,也有利于我们的training。在movielens数据集中,我们以样本出现的次数作为权重,随机选择样本构建负样本集,实现如下
def Random_Negative_Sampling(self, items):
ret = {}
for i in items:
ret[i] = 1
count = 0
for i in range(0, len(items)*5):
item = self.items_pool[random.randint(0, len(self.items_pool)-1)]
if item in items:
continue
ret[item] = 0
count += 1
if count > 2*len(items):
break
return ret在实际实现LFM算法的过程中,自己遇到了一个大坑,提出来希望大家注意。
先问问你,如何去计算一个用户对一个物品的喜爱程度?是不是直接用上面那个公式,用用户对类的喜爱程度和该物品在此类中的权重乘积的累加呀。那么恭喜你,如果这样做,效果非常不好,一是太难收敛,二是预测效果总是不好。为啥呢?实际预测的矩阵里只有0和1两个值,而Preference的计算则是一个实数,在梯度下降的时候要用到这两者的差值,而这个值变动的范围太大,一方面导致你基本很难收敛,另一方面超参数的选择是个非常头疼的问题。所以,在计算喜好度的时候,一定要给结果
加个sigmoid!!!
加个sigmoid!!!
加个sigmoid!!!
这样把你的结果约束到0和1之间,防止在计算误差的时候出现太大的波动从而影响收敛。这里我在movielen的数据集上也进行了实验,《推荐系统实战》那本书里选择的隐类个数为100,本来是想复现他的结果,不过我发现算起来实在是太慢了,所以我这里选择隐类F=10,学习率alpha=0.03,正则项稀疏lambda=0.01,在所有的用户上迭代了30轮次,最后在测试集上的表现如下
召回率6.91% 精确率 23.2% 覆盖率 40.8% 流行度 5.20。
按照常理和书上所说,基于学习的这种方法的表现应该比基于统计的协同过滤表现要好点,但是这里的结果明显比之前的最好结果要差些,主要原因可能是这里的隐类选的太少了,书中的实验实际选择的隐类数目为100。但我发现隐类100的时候不仅每一轮计算的速度大大提升,并且收敛的速度也远远慢于隐类数目较少的时候,这也很容易理解,毕竟对应的需要优化的参数数目多了10倍,因此需要的训练样本也要更多,收敛自然更慢,有兴趣的或者有时间的同学可以去尝试一下。
然后在整个实现LFM的过程中,还有其他几个小地方大家可以注意一下
- 参数的初始化。所有参数初始化为0好像不是一个好选择,总是无法收敛。一般的做法都是选择在-1到1之间的随机数。
- 构建负样本和正样本的比例。书中说这是一个影响模型效果很重要的参数,实际上可以这么理解,相同轮次的迭代,负样本比例越高,其实越多的训练数据,自然模型的表达能力可能会更好。
- 超参数的选择。在实际使用的过程中,我发现超参数的选择对于LFM模型的表现真实至关重要,学习率过高直接导致没法收敛,但是太低了收敛的速度又太慢了,所以超参数的选择真的是一个非常头疼的事。
- LFM的计算速度是真的很慢。每一轮迭代,要在每个用户上迭代其所有的行为记录和我们构造的负样本,导致计算真的非常耗时。而隐类个数的增加不仅导致需要优化的参数增加,对于数据的需求同样提高,这样直接导致收敛速度变得非常非常慢。
===============================================================================================最后是对LFM算法的一些思考,它的本质其实就是矩阵分解,将之前的用户物品矩阵分解成了用户-隐类矩阵和隐类-物品矩阵,然后目标是让这两个矩阵的乘积与原矩阵的残差尽可能得小,同时引入了一些正则项防止过拟合。后来我发现其实LFM算法就是FunkSVD算法,是典型的基于矩阵分解的方法,后来又出现了基于它进行改进的方法。
BiasSVD。在FunkSVD的基础上又引入了平均得分、用户偏置项和物品偏置项,相比于FunkSVD又多了两个需要优化的参数,但优化方法啥的都是一样的。事实表明,由于考虑了这些偏置项,令BiasSVD在某些场景下变现会优异很多。
SVD++。在BiasSVD的基础上又引入了用户的隐式反馈,也就是用户之前如果对该物品产生过交互,则对它的评分要进行修正。我的妈呀,越来越复杂,算得也是越来越慢,之前在知乎上看到说虽然SVD++之前在比赛里大放异彩,但实际好像根本没人用……计算代价太大,没法实时推荐,并且可解释性也不强,真是扎心了。
OK,LFM就聊到这里,下一章我们讲Item2Vec,终于要到深度部分了啊,蛤蛤蛤~
===============================================================================================
刚刚发布了一下发现内容有点短啊,那我把LFM的完整代码发出来吧,希望对大家有用
class LFM():
def __init__(self, data, F, seed):
self.train, self.test = self.train_test_split(data, seed)
self.F = F
self.items_pool, self.all_items, self.all_users = self.Helper()
self.item_popularity=self.Item_popularity()
self.P, self.Q = self.Initial_LFM_Par()
def train_test_split(self, data, seed):
train_set = {}
test_set = {}
for user, movies in data.groupby('user_id'):
movies = movies.sample(
frac=1, random_state=seed).reset_index(drop=True)
train = movies[:int(0.8*len(movies))]
test = movies[int(0.8*len(movies)):]
train_set[user] = set(train['movies_id'].tolist())
test_set[user] = set(test['movies_id'].tolist())
print('Data preparation finished')
return train_set, test_set
def data_update(self, data, seed):
self.train, self.test = self.train_test_split(data, seed)
def Helper(self):
items_pool = []
all_items = set()
all_users = set()
for u, items in self.train.items():
all_users.add(u)
for i in items:
items_pool.append(i)
all_items.add(i)
return items_pool, all_items, all_users
def Item_popularity(self):
item_popularity = {}
for item in self.items_pool:
if item not in item_popularity.keys():
item_popularity[item] = 0
item_popularity[item] += 1
return item_popularity
def Random_Negative_Sampling(self, items):
ret = {}
for i in items:
ret[i] = 1
count = 0
for i in range(0, len(items)*5):
item = self.items_pool[random.randint(0, len(self.items_pool)-1)]
if item in items:
continue
ret[item] = 0
count += 1
if count > 2*len(items):
break
return ret
def Initial_LFM_Par(self):
P = {}
Q = {}
for user in self.all_users:
P[user] = {}
for k in range(self.F):
P[user][k] = random.random()
for k in range(self.F):
Q[k] = {}
for item in self.all_items:
Q[k][item] = random.random()
return P, Q
def Predict(self, user, item):
pre = sum(self.P[user][k]*self.Q[k][item] for k in range(self.F))
return 1.0/(1+np.exp(-pre))
def Generate_sample(self):
sample={}
for user, items in self.train.items():
sample[user] = self.Random_Negative_Sampling(items)
return sample
def Parameter_Update2(self, N_step, alpha, lam, N):
sample=self.Generate_sample()
for step in range(N_step):
print('Now step %i' % step)
for user in self.all_users:
for item, rui in sample[user].items():
eui = rui-self.Predict(user, item)
for k in range(self.F):
self.P[user][k] += (eui*self.Q[k]
[item]-lam*self.P[user][k])*alpha
self.Q[k][item] += (eui*self.P[user]
[k]-lam*self.Q[k][item])*alpha
if (step+1)%10==0:
recall, precision, coverage, popularity=self.eval_fun(N)
alpha *= 0.95
def Parameter_Update(self, N_step, alpha, lam, N):
for step in range(N_step):
print('Now step %i' % step)
for user, items in self.train.items():
sample = self.Random_Negative_Sampling(items)
for item, rui in sample.items():
eui = rui-self.Predict(user, item)
for k in range(self.F):
self.P[user][k] += (eui*self.Q[k]
[item]-lam*self.P[user][k])*alpha
self.Q[k][item] += (eui*self.P[user]
[k]-lam*self.Q[k][item])*alpha
if (step+1)%10==0:
recall, precision, coverage, popularity=self.eval_fun(N)
alpha *= 0.95
def Recommend(self, user):
rank = {}
already_items = self.train[user]
for item in self.all_items:
if item in already_items:
continue
rank[item]=self.Predict(user,item)
return rank
def Get_Recommendation(self, user,N):
rank = self.Recommend(user)
recommend_list = []
for i, score in sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]:
recommend_list.append(i)
return recommend_list
def eval_fun(self,N):
hit = 0
all_recall = 0
all_precision = 0
recommend_items = set()
ret = 0
n = 0
for user in self.all_users:
tu = self.test[user]
recommend_list = self.Get_Recommendation(user,N)
for item in recommend_list:
recommend_items.add(item)
ret += np.log(1+self.item_popularity[item])
n += 1
if item in tu:
hit += 1
all_recall += len(tu)
all_precision += N
print(hit)
recall = hit/(all_recall*1.0)
precision = hit/(all_precision*1.0)
coverage = len(recommend_items)/(len(self.all_items)*1.0)
popularity = ret/(n*1.0)
print(recall, precision, coverage, popularity)
return recall, precision, coverage, popularity