QCOM平台使用WALT(Window Assisted Load Tracking)作为CPU load tracking的方法;相对地,ARM使用的是PELT(Per-Entity Load Tracking)。
WALT的核心算法思想是:将一小段时间内的CPU loading情况计算出对应的结果,作为一个window;然后再统计多个类似的window。通过计算,得出task demand,最后将结果运用于CPU 频率调节,负载均衡(task迁移)。
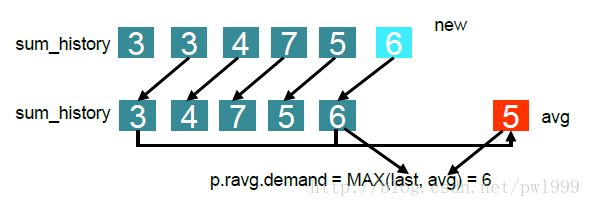
主要代码在walt.c中。代码基于kernel-4.19版本。
-
WALT核心结构体
struct rq { ... #ifdef CONFIG_SCHED_WALT struct sched_cluster *cluster; struct cpumask freq_domain_cpumask; struct walt_sched_stats walt_stats; u64 window_start; s64 cum_window_start; unsigned long walt_flags; u64 cur_irqload; u64 avg_irqload; u64 irqload_ts; struct task_struct *ed_task; struct cpu_cycle cc; u64 old_busy_time, old_busy_time_group; u64 old_estimated_time; u64 curr_runnable_sum; u64 prev_runnable_sum; u64 nt_curr_runnable_sum; u64 nt_prev_runnable_sum; u64 cum_window_demand_scaled; struct group_cpu_time grp_time; struct load_subtractions load_subs[NUM_TRACKED_WINDOWS]; DECLARE_BITMAP_ARRAY(top_tasks_bitmap, NUM_TRACKED_WINDOWS, NUM_LOAD_INDICES); u8 *top_tasks[NUM_TRACKED_WINDOWS]; u8 curr_table; int prev_top; int curr_top; bool notif_pending; u64 last_cc_update; u64 cycles; #endif /* CONFIG_SCHED_WALT */ ... } struct task_struct { ... #ifdef CONFIG_SCHED_WALT struct ravg ravg; /* * 'init_load_pct' represents the initial task load assigned to children * of this task */ u32 init_load_pct; u64 last_wake_ts; u64 last_enqueued_ts; struct related_thread_group *grp; struct list_head grp_list; u64 cpu_cycles; bool misfit; u8 unfilter; #endif ... } #ifdef CONFIG_SCHED_WALT /* ravg represents frequency scaled cpu-demand of tasks */ struct ravg { /* * 'mark_start' marks the beginning of an event (task waking up, task * starting to execute, task being preempted) within a window * * 'sum' represents how runnable a task has been within current * window. It incorporates both running time and wait time and is * frequency scaled. * * 'sum_history' keeps track of history of 'sum' seen over previous * RAVG_HIST_SIZE windows. Windows where task was entirely sleeping are * ignored. * * 'demand' represents maximum sum seen over previous * sysctl_sched_ravg_hist_size windows. 'demand' could drive frequency * demand for tasks. * * 'curr_window_cpu' represents task's contribution to cpu busy time on * various CPUs in the current window * * 'prev_window_cpu' represents task's contribution to cpu busy time on * various CPUs in the previous window * * 'curr_window' represents the sum of all entries in curr_window_cpu * * 'prev_window' represents the sum of all entries in prev_window_cpu * * 'pred_demand' represents task's current predicted cpu busy time * * 'busy_buckets' groups historical busy time into different buckets * used for prediction * * 'demand_scaled' represents task's demand scaled to 1024 */ u64 mark_start; u32 sum, demand; u32 coloc_demand; u32 sum_history[RAVG_HIST_SIZE_MAX]; u32 *curr_window_cpu, *prev_window_cpu; u32 curr_window, prev_window; u16 active_windows; u32 pred_demand; u8 busy_buckets[NUM_BUSY_BUCKETS]; u16 demand_scaled; u16 pred_demand_scaled; }; #endif
-
负载记录
WALT中,使用demand记录task负载
static inline unsigned long task_util(struct task_struct *p)
{
#ifdef CONFIG_SCHED_WALT
return p->ravg.demand_scaled; //task负载
#endif
return READ_ONCE(p->se.avg.util_avg);
}
使用cumulative_runnable_avg_scaled记录cpu负载
static inline unsigned long cpu_util(int cpu) { struct cfs_rq *cfs_rq; unsigned int util; #ifdef CONFIG_SCHED_WALT u64 walt_cpu_util = cpu_rq(cpu)->walt_stats.cumulative_runnable_avg_scaled; //cpu负载 return min_t(unsigned long, walt_cpu_util, capacity_orig_of(cpu)); #endif cfs_rq = &cpu_rq(cpu)->cfs; util = READ_ONCE(cfs_rq->avg.util_avg); if (sched_feat(UTIL_EST)) util = max(util, READ_ONCE(cfs_rq->avg.util_est.enqueued)); return min_t(unsigned long, util, capacity_orig_of(cpu)); } static inline unsigned long cpu_util_cum(int cpu, int delta) { u64 util = cpu_rq(cpu)->cfs.avg.util_avg; unsigned long capacity = capacity_orig_of(cpu); #ifdef CONFIG_SCHED_WALT util = cpu_rq(cpu)->cum_window_demand_scaled; //处于当前运行的task util?目前还没搞清楚 #endif delta += util; if (delta < 0) return 0; return (delta >= capacity) ? capacity : delta; }
-
WALT机制触发的时刻

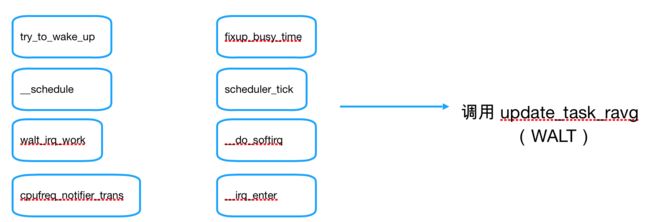
-
WALT主要机制
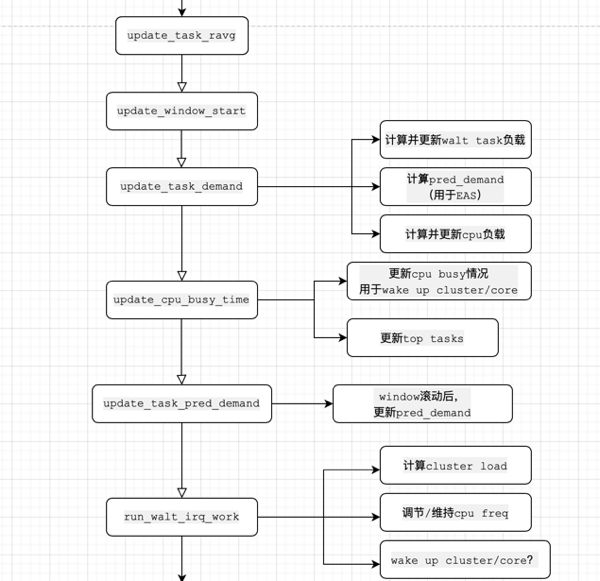
1. task load,cpu load统计
/* Reflect task activity on its demand and cpu's busy time statistics */ void update_task_ravg(struct task_struct *p, struct rq *rq, int event, u64 wallclock, u64 irqtime) { u64 old_window_start; if (!rq->window_start || sched_disable_window_stats || p->ravg.mark_start == wallclock) //3个直接return的条件:walt算法没有开始;临时关闭了walt;wallclock没更新,不用做重复工作 return; lockdep_assert_held(&rq->lock); old_window_start = update_window_start(rq, wallclock, event); //这里是算法刚刚开始,所以只是获取window start if (!p->ravg.mark_start) { //第一次进入没有标记walt算法的开始:mark_start。那么就直接goto done; update_task_cpu_cycles(p, cpu_of(rq), wallclock); //同时,更新cpu cycle count(后续在scale_exec_time中计算cpu freq) goto done; } update_task_rq_cpu_cycles(p, rq, event, wallclock, irqtime); //同上,更新cpu cycle count(后续在scale_exec_time中计算cpu freq),比上面多一个idle task的判断处理 update_task_demand(p, rq, event, wallclock); //(1.)walt,更新task demand update_cpu_busy_time(p, rq, event, wallclock, irqtime); //(2.)walt,更新cpu busy time update_task_pred_demand(rq, p, event); //(3.)walt,更新预测的task demand if (exiting_task(p)) //exiting task的情况下,不记录trace log goto done;
//trace logs trace_sched_update_task_ravg(p, rq, event, wallclock, irqtime, rq->cc.cycles, rq->cc.time, &rq->grp_time); trace_sched_update_task_ravg_mini(p, rq, event, wallclock, irqtime, rq->cc.cycles, rq->cc.time, &rq->grp_time); done: p->ravg.mark_start = wallclock; //更新mark_start,记录下一次walt算法开始的时间 run_walt_irq_work(old_window_start, rq); //(4.)walt,针对irq情况的处理 }
1. 统计cpu task的demand AND/OR 更新对应cpu的demand history。
注释主要讲了3种(a、b、c)可能情况下的ravg.sum负载统计方法。都是wallclock-mark_start归一化时间,对于irqtime为1的情况可以看code稍有不同,但是原理是类似的。
/* * Account cpu demand of task and/or update task's cpu demand history * * ms = p->ravg.mark_start; * wc = wallclock * ws = rq->window_start * * Three possibilities: * * a) Task event is contained within one window. * window_start < mark_start < wallclock * * ws ms wc * | | | * V V V * |---------------| * * In this case, p->ravg.sum is updated *iff* event is appropriate * (ex: event == PUT_PREV_TASK) * * b) Task event spans two windows. * mark_start < window_start < wallclock * * ms ws wc * | | | * V V V * -----|------------------- * * In this case, p->ravg.sum is updated with (ws - ms) *iff* event * is appropriate, then a new window sample is recorded followed * by p->ravg.sum being set to (wc - ws) *iff* event is appropriate. * * c) Task event spans more than two windows. * * ms ws_tmp ws wc * | | | | * V V V V * ---|-------|-------|-------|-------|------ * | | * |<------ nr_full_windows ------>| * * In this case, p->ravg.sum is updated with (ws_tmp - ms) first *iff* * event is appropriate, window sample of p->ravg.sum is recorded, * 'nr_full_window' samples of window_size is also recorded *iff* * event is appropriate and finally p->ravg.sum is set to (wc - ws) * *iff* event is appropriate. * * IMPORTANT : Leave p->ravg.mark_start unchanged, as update_cpu_busy_time() * depends on it! */ static u64 update_task_demand(struct task_struct *p, struct rq *rq, int event, u64 wallclock) { u64 mark_start = p->ravg.mark_start; u64 delta, window_start = rq->window_start; int new_window, nr_full_windows; u32 window_size = sched_ravg_window; u64 runtime; new_window = mark_start < window_start; //当new_window=1时,情况为b、c if (!account_busy_for_task_demand(rq, p, event)) { //判断该task是否会工作导致busy if (new_window) /* * If the time accounted isn't being accounted as * busy time, and a new window started, only the * previous window need be closed out with the * pre-existing demand. Multiple windows may have * elapsed, but since empty windows are dropped, * it is not necessary to account those. //如果不导致busy,并且有new window了,那么说明繁忙的工作已经完成了,很多有数据的window已经流逝了,并且空闲的window被drop了,所以,只需要调用update。 */ update_history(rq, p, p->ravg.sum, 1, event); //(1.1)update上次的计算结果,长度:p->ravg.sum return 0; } if (!new_window) { /* * The simple case - busy time contained within the existing * window. */ return add_to_task_demand(rq, p, wallclock - mark_start); //(1.2)情况a:最简单的情况,直接更新wallclock - mark_start } /* * Busy time spans at least two windows. Temporarily rewind * window_start to first window boundary after mark_start. */ delta = window_start - mark_start; //busy time跨越至少2个window时,先临时将window_start移动到mark_start紧接着后面的window边界处,记作ws_tmp nr_full_windows = div64_u64(delta, window_size); window_start -= (u64)nr_full_windows * (u64)window_size; /* Process (window_start - mark_start) first */ runtime = add_to_task_demand(rq, p, window_start - mark_start); //先计算ws_tmp - mark_start /* Push new sample(s) into task's demand history */ update_history(rq, p, p->ravg.sum, 1, event); //更新history,长度:p->ravg.sum if (nr_full_windows) { //如上面,其中有遗留的完整window,也需要更新,长度:nr_full_windows * scaled_window; scaled_window由window_size,cpu freq等参数计算转化而来 u64 scaled_window = scale_exec_time(window_size, rq); update_history(rq, p, scaled_window, nr_full_windows, event); runtime += nr_full_windows * scaled_window; } /* * Roll window_start back to current to process any remainder * in current window. */ window_start += (u64)nr_full_windows * (u64)window_size; //将window_start重新从ws_tmp处移回原先的地方 /* Process (wallclock - window_start) next */ mark_start = window_start; runtime += add_to_task_demand(rq, p, wallclock - mark_start); //在计算wallclock - mark_start(其实就是window_start) return runtime; //runtime记录的是task累计的时间 }
1.1 更新history, 这里就会对history中的window值求平均,再根据policy来选择最近的值 or 是最大值,还是平均值,还是最大与最近值中较大的值(默认)
/* * Called when new window is starting for a task, to record cpu usage over * recently concluded window(s). Normally 'samples' should be 1. It can be > 1 * when, say, a real-time task runs without preemption for several windows at a * stretch. */ static void update_history(struct rq *rq, struct task_struct *p, u32 runtime, int samples, int event) { u32 *hist = &p->ravg.sum_history[0]; int ridx, widx; u32 max = 0, avg, demand, pred_demand; u64 sum = 0; u16 demand_scaled, pred_demand_scaled; /* Ignore windows where task had no activity */ if (!runtime || is_idle_task(p) || exiting_task(p) || !samples) //如果没有活动的task,例如:idle,exiting等,就不用计算 goto done; /* Push new 'runtime' value onto stack */ widx = sched_ravg_hist_size - 1; ridx = widx - samples; for (; ridx >= 0; --widx, --ridx) { //这个循环,主要将hist数组中较久的数据去除,留下较新的数据。留下的数据累计到sum中 hist[widx] = hist[ridx]; sum += hist[widx]; if (hist[widx] > max) max = hist[widx]; } for (widx = 0; widx < samples && widx < sched_ravg_hist_size; widx++) { //这个循环,主要将新的数据填充点hist数组中,并累计到sum中 hist[widx] = runtime; sum += hist[widx]; if (hist[widx] > max) max = hist[widx]; } p->ravg.sum = 0; if (sysctl_sched_window_stats_policy == WINDOW_STATS_RECENT) { //根据policy选择demand的计算方式,默认policy为WINDOW_STATS_MAX_RECENT_AVG=2 demand = runtime; } else if (sysctl_sched_window_stats_policy == WINDOW_STATS_MAX) { demand = max; } else { avg = div64_u64(sum, sched_ravg_hist_size); //计算avg均值 if (sysctl_sched_window_stats_policy == WINDOW_STATS_AVG) demand = avg; else demand = max(avg, runtime); //默认的policy } pred_demand = predict_and_update_buckets(rq, p, runtime); //(1.1.1)根据当前的数据,计算预测的demand demand_scaled = scale_demand(demand); //归一化demand pred_demand_scaled = scale_demand(pred_demand); //归一化预测的demand /* * A throttled deadline sched class task gets dequeued without * changing p->on_rq. Since the dequeue decrements walt stats * avoid decrementing it here again. * * When window is rolled over, the cumulative window demand * is reset to the cumulative runnable average (contribution from * the tasks on the runqueue). If the current task is dequeued * already, it's demand is not included in the cumulative runnable * average. So add the task demand separately to cumulative window * demand. */
/* 上面这段话的目的是校正参数,分两种情况。第一种,task在rq queue里面,上次task
的demand为x,本次计算为y,则cpu负载:cumulative_runnable_avg_scaled += (y-x)。
第二种情况task不在rq queue里面,并且当前task是本次计算demand的task,则直接计算
window load,cum_window_demand_scaled += y;
总结上面一句话:新task,它的demand直接累加到累计的demand变量中;而原task的demand发生变化,那么就要把该task的增减量delta,更新到累计的demand变量中。
****这个cum_window_demand_scaled数据和cumulative_runnable_avg_scaled是体现cpu untilization的一种体现***
*/
if (!task_has_dl_policy(p) || !p->dl.dl_throttled) { if (task_on_rq_queued(p) && p->sched_class->fixup_walt_sched_stats) p->sched_class->fixup_walt_sched_stats(rq, p, demand_scaled, pred_demand_scaled); else if (rq->curr == p) walt_fixup_cum_window_demand(rq, demand_scaled); } p->ravg.demand = demand; //更新ravg结构体中相关数据参数 p->ravg.demand_scaled = demand_scaled; p->ravg.coloc_demand = div64_u64(sum, sched_ravg_hist_size); //这里有点没明白,为什么又作一次计算,更新colocation demand。这个demand,肯定是更实时。 p->ravg.pred_demand = pred_demand; p->ravg.pred_demand_scaled = pred_demand_scaled; if (demand_scaled > sched_task_filter_util) //demand_scaled > 35(0.68ms, default for 20ms window size scaled to 1024) p->unfilter = sysctl_sched_task_unfilter_nr_windows; //如果demand超过了,那么就放开task迁移到更大的cpu的其一限制(限制条件不只这一条,这只是其中之一),并维持10次cnt else if (p->unfilter) p->unfilter = p->unfilter - 1; //没达到,就会cnt减1。为0后,task就会不满足up migrate的条件 done: trace_sched_update_history(rq, p, runtime, samples, event); //trace log }
1.1.1 预测demand,并更新buckets
static inline u32 predict_and_update_buckets(struct rq *rq, struct task_struct *p, u32 runtime) { int bidx; u32 pred_demand; if (!sched_predl) return 0; bidx = busy_to_bucket(runtime); //将runtime桶化成busy的等级:1~9,数字越大,越busy pred_demand = get_pred_busy(rq, p, bidx, runtime); //计算预测demand,看下面的详细解析 bucket_increase(p->ravg.busy_buckets, bidx); //更新bucket,详细解析看下面 return pred_demand; }
计算预测demand(预测的demand主要用于EAS)
/* * get_pred_busy - calculate predicted demand for a task on runqueue * * @rq: runqueue of task p * @p: task whose prediction is being updated * @start: starting bucket. returned prediction should not be lower than * this bucket. * @runtime: runtime of the task. returned prediction should not be lower * than this runtime. * Note: @start can be derived from @runtime. It's passed in only to * avoid duplicated calculation in some cases. * * A new predicted busy time is returned for task @p based on @runtime * passed in. The function searches through buckets that represent busy * time equal to or bigger than @runtime and attempts to find the bucket to * to use for prediction. Once found, it searches through historical busy * time and returns the latest that falls into the bucket. If no such busy * time exists, it returns the medium of that bucket. */ static u32 get_pred_busy(struct rq *rq, struct task_struct *p, int start, u32 runtime) { int i; u8 *buckets = p->ravg.busy_buckets; u32 *hist = p->ravg.sum_history; u32 dmin, dmax; u64 cur_freq_runtime = 0; int first = NUM_BUSY_BUCKETS, final; u32 ret = runtime; /* skip prediction for new tasks due to lack of history */ if (unlikely(is_new_task(p))) //new task没有history,所以不用作预测 goto out; /* find minimal bucket index to pick */ for (i = start; i < NUM_BUSY_BUCKETS; i++) { //找到第一个非0值bucket的index if (buckets[i]) { first = i; break; } } /* if no higher buckets are filled, predict runtime */ if (first >= NUM_BUSY_BUCKETS) //这个条件应该永远不会满足,因为index最大为9 goto out; /* compute the bucket for prediction */ final = first; /* determine demand range for the predicted bucket */ if (final < 2) { //如果index是最小的0、1,那么就直接设为1。因为不可能出现比最小还小 /* lowest two buckets are combined */ dmin = 0; final = 1; } else { dmin = mult_frac(final, max_task_load(), NUM_BUSY_BUCKETS); //反向计算,还原final index对应runtime } dmax = mult_frac(final + 1, max_task_load(), NUM_BUSY_BUCKETS); //反向计算,还原final+1 index对应的runtime /* * search through runtime history and return first runtime that falls * into the range of predicted bucket. */ for (i = 0; i < sched_ravg_hist_size; i++) { //在history中寻找,最新的一个能满足runtime区间的记录 if (hist[i] >= dmin && hist[i] < dmax) { ret = hist[i]; break; } } /* no historical runtime within bucket found, use average of the bin */ if (ret < dmin) //没有找到,那么使用区间的中值 ret = (dmin + dmax) / 2; /* * when updating in middle of a window, runtime could be higher * than all recorded history. Always predict at least runtime. */ ret = max(runtime, ret); //保持预测的值不小于原先的runtime out: trace_sched_update_pred_demand(rq, p, runtime, mult_frac((unsigned int)cur_freq_runtime, 100, sched_ravg_window), ret); return ret; }
bucket_increase用于更新bucket,如果index匹配,那么就会增加8/16(small step/big step),但不会超过最大255。
如果index不匹配,那么就会自动进行衰减2,直到减为0。
#define INC_STEP 8 #define DEC_STEP 2 #define CONSISTENT_THRES 16 #define INC_STEP_BIG 16 /* * bucket_increase - update the count of all buckets * * @buckets: array of buckets tracking busy time of a task * @idx: the index of bucket to be incremented * * Each time a complete window finishes, count of bucket that runtime * falls in (@idx) is incremented. Counts of all other buckets are * decayed. The rate of increase and decay could be different based * on current count in the bucket. */ static inline void bucket_increase(u8 *buckets, int idx) { int i, step; for (i = 0; i < NUM_BUSY_BUCKETS; i++) { if (idx != i) { if (buckets[i] > DEC_STEP) buckets[i] -= DEC_STEP; else buckets[i] = 0; } else { step = buckets[i] >= CONSISTENT_THRES ? INC_STEP_BIG : INC_STEP; if (buckets[i] > U8_MAX - step) buckets[i] = U8_MAX; else buckets[i] += step; } } }
——————————
1.2 add_to_task_demand比较简单,就是将task运行占用的时间归一化,然后累计到ravg.sum,但是ravg.sum不能超过sched_ravg_window(20ms)。
static u64 add_to_task_demand(struct rq *rq, struct task_struct *p, u64 delta) { delta = scale_exec_time(delta, rq); //这里就会用到之前的cpu cycle count p->ravg.sum += delta; if (unlikely(p->ravg.sum > sched_ravg_window)) p->ravg.sum = sched_ravg_window; return delta; }
=================
2. 在cpu活动时,更新cpu busy time(rq->curr/prev_runnable_sum)
/* * Account cpu activity in its busy time counters (rq->curr/prev_runnable_sum) */ static void update_cpu_busy_time(struct task_struct *p, struct rq *rq, int event, u64 wallclock, u64 irqtime) { int new_window, full_window = 0; int p_is_curr_task = (p == rq->curr); u64 mark_start = p->ravg.mark_start; u64 window_start = rq->window_start; u32 window_size = sched_ravg_window; u64 delta; u64 *curr_runnable_sum = &rq->curr_runnable_sum; u64 *prev_runnable_sum = &rq->prev_runnable_sum; u64 *nt_curr_runnable_sum = &rq->nt_curr_runnable_sum; u64 *nt_prev_runnable_sum = &rq->nt_prev_runnable_sum; bool new_task; struct related_thread_group *grp; int cpu = rq->cpu; u32 old_curr_window = p->ravg.curr_window; new_window = mark_start < window_start; if (new_window) { full_window = (window_start - mark_start) >= window_size; //full window代表距离上次更新较久了(>20ms) if (p->ravg.active_windows < USHRT_MAX) p->ravg.active_windows++; } new_task = is_new_task(p); //更具ravg.active_windows判断是否是<5,则便是原先空的window,现在有新task填充。仅发生在刚开始初始化阶段 /* * Handle per-task window rollover. We don't care about the idle * task or exiting tasks. */ if (!is_idle_task(p) && !exiting_task(p)) { //idle、exiting task的rollover,无需考虑 if (new_window) rollover_task_window(p, full_window); //task rollover实际就是转存下window,把curr存到pre。并且转存per cpu的prev_window_cpu[] } if (p_is_curr_task && new_window) { rollover_cpu_window(rq, full_window); //转存rq、rq->grp_time相关的curr_runnable_sum、nt_curr_runnable_sum
rollover_top_tasks(rq, full_window); //转存top_tass_table和curr_top task } if (!account_busy_for_cpu_time(rq, p, irqtime, event)) //非busy(可能正在migrate,idle等)则直接update top tasks goto done; grp = p->grp; if (grp) { //如果task有releated_thread_group,那么使用grp_time的curr_runnable_sum和nt_curr_runnable_sum struct group_cpu_time *cpu_time = &rq->grp_time; curr_runnable_sum = &cpu_time->curr_runnable_sum; prev_runnable_sum = &cpu_time->prev_runnable_sum; nt_curr_runnable_sum = &cpu_time->nt_curr_runnable_sum; nt_prev_runnable_sum = &cpu_time->nt_prev_runnable_sum; } if (!new_window) { /* * account_busy_for_cpu_time() = 1 so busy time needs * to be accounted to the current window. No rollover * since we didn't start a new window. An example of this is * when a task starts execution and then sleeps within the * same window. ***task执行,然后接着就sleep;动作发生在通一个window中,这个情况下不需要rollover*** */ if (!irqtime || !is_idle_task(p) || cpu_is_waiting_on_io(rq)) delta = wallclock - mark_start; //非中断、idle task、cpu等待io的情况下,delta的值 else delta = irqtime; //中断、idle task、cpu等待io的情况下,delta的值 delta = scale_exec_time(delta, rq); *curr_runnable_sum += delta; //归一化后,统计到curr_runnable_sum if (new_task) *nt_curr_runnable_sum += delta; //如果是new task,也累加到nt_curr_rannable_sum中 if (!is_idle_task(p) && !exiting_task(p)) { p->ravg.curr_window += delta; //更新curr_window和对应cpu的数组curr_window_cpu[cpu] p->ravg.curr_window_cpu[cpu] += delta; } goto done; } if (!p_is_curr_task) { /* * account_busy_for_cpu_time() = 1 so busy time needs * to be accounted to the current window. A new window * has also started, but p is not the current task, so the * window is not rolled over - just split up and account * as necessary into curr and prev. The window is only * rolled over when a new window is processed for the current * task. * * Irqtime can't be accounted by a task that isn't the * currently running task. ***p不是current task的情况,irqtime不能被统计到p*** */ if (!full_window) { /* * A full window hasn't elapsed, account partial * contribution to previous completed window. ***没有出现过了full window的时候,仅更新到prev_window*** */ delta = scale_exec_time(window_start - mark_start, rq); //更新的大小:window_start - mark_start if (!exiting_task(p)) { p->ravg.prev_window += delta; p->ravg.prev_window_cpu[cpu] += delta; } } else { /* * Since at least one full window has elapsed, * the contribution to the previous window is the * full window (window_size). */ delta = scale_exec_time(window_size, rq); //出现了full window的情况下,更新的大小:window_size,20ms if (!exiting_task(p)) { p->ravg.prev_window = delta; p->ravg.prev_window_cpu[cpu] = delta; } } *prev_runnable_sum += delta; //再更新prev_runnable_sum和nt_prev_runnable_sum if (new_task) *nt_prev_runnable_sum += delta; /* Account piece of busy time in the current window. */ delta = scale_exec_time(wallclock - window_start, rq); //再统计curr window到curr_runnable_sum和nt_curr_runnable_sum *curr_runnable_sum += delta; if (new_task) *nt_curr_runnable_sum += delta; if (!exiting_task(p)) { //并更新curr_window和对应cpu的数组curr_window_cpu[cpu] p->ravg.curr_window = delta; p->ravg.curr_window_cpu[cpu] = delta; } goto done; } if (!irqtime || !is_idle_task(p) || cpu_is_waiting_on_io(rq)) { /* * account_busy_for_cpu_time() = 1 so busy time needs * to be accounted to the current window. A new window * has started and p is the current task so rollover is * needed. If any of these three above conditions are true * then this busy time can't be accounted as irqtime. * * Busy time for the idle task or exiting tasks need not * be accounted. * * An example of this would be a task that starts execution * and then sleeps once a new window has begun. ***一个task开始执行,然后在1个new window开始时,sleep了(也是类似统计curr_rannable_sum等)*** */ if (!full_window) { /* * A full window hasn't elapsed, account partial * contribution to previous completed window. */ delta = scale_exec_time(window_start - mark_start, rq); if (!is_idle_task(p) && !exiting_task(p)) { p->ravg.prev_window += delta; p->ravg.prev_window_cpu[cpu] += delta; } } else { /* * Since at least one full window has elapsed, * the contribution to the previous window is the * full window (window_size). */ delta = scale_exec_time(window_size, rq); if (!is_idle_task(p) && !exiting_task(p)) { p->ravg.prev_window = delta; p->ravg.prev_window_cpu[cpu] = delta; } } /* * Rollover is done here by overwriting the values in * prev_runnable_sum and curr_runnable_sum. */ *prev_runnable_sum += delta; if (new_task) *nt_prev_runnable_sum += delta; /* Account piece of busy time in the current window. */ delta = scale_exec_time(wallclock - window_start, rq); *curr_runnable_sum += delta; if (new_task) *nt_curr_runnable_sum += delta; if (!is_idle_task(p) && !exiting_task(p)) { p->ravg.curr_window = delta; p->ravg.curr_window_cpu[cpu] = delta; } goto done; } if (irqtime) { //scheduler_tick函数触发的时候,irqtime=0 /* * account_busy_for_cpu_time() = 1 so busy time needs * to be accounted to the current window. A new window * has started and p is the current task so rollover is * needed. The current task must be the idle task because * irqtime is not accounted for any other task. * * Irqtime will be accounted each time we process IRQ activity * after a period of idleness, so we know the IRQ busy time * started at wallclock - irqtime. ***irq发生的情况下,统计busy time(也是类似统计curr_rannable_sum等)*** */ BUG_ON(!is_idle_task(p)); mark_start = wallclock - irqtime; /* * Roll window over. If IRQ busy time was just in the current * window then that is all that need be accounted. */ if (mark_start > window_start) { *curr_runnable_sum = scale_exec_time(irqtime, rq); return; } /* * The IRQ busy time spanned multiple windows. Process the * busy time preceding the current window start first. */ delta = window_start - mark_start; if (delta > window_size) delta = window_size; delta = scale_exec_time(delta, rq); *prev_runnable_sum += delta; /* Process the remaining IRQ busy time in the current window. */ delta = wallclock - window_start; rq->curr_runnable_sum = scale_exec_time(delta, rq); return; } done: if (!is_idle_task(p) && !exiting_task(p)) update_top_tasks(p, rq, old_curr_window, new_window, full_window); (2.1)更新cpu top task }
2.1 更新top task,维护curr_table/prev_table
static void update_top_tasks(struct task_struct *p, struct rq *rq,
u32 old_curr_window, int new_window, bool full_window)
{
u8 curr = rq->curr_table;
u8 prev = 1 - curr;
u8 *curr_table = rq->top_tasks[curr];
u8 *prev_table = rq->top_tasks[prev];
int old_index, new_index, update_index;
u32 curr_window = p->ravg.curr_window;
u32 prev_window = p->ravg.prev_window;
bool zero_index_update;
if (old_curr_window == curr_window && !new_window)
return;
old_index = load_to_index(old_curr_window); //把load转化为index
new_index = load_to_index(curr_window);
if (!new_window) { //在没有new window的情况下,更新当前top表rq->curr_table[]中新旧index的计数,
zero_index_update = !old_curr_window && curr_window; //根据curr_table[新旧index]的计数,更新rq->top_tasks_bitmap[curr] bitmap中对应index的值
if (old_index != new_index || zero_index_update) {
if (old_curr_window)
curr_table[old_index] -= 1;
if (curr_window)
curr_table[new_index] += 1;
if (new_index > rq->curr_top)
rq->curr_top = new_index;
}
if (!curr_table[old_index])
__clear_bit(NUM_LOAD_INDICES - old_index - 1,
rq->top_tasks_bitmap[curr]);
if (curr_table[new_index] == 1)
__set_bit(NUM_LOAD_INDICES - new_index - 1,
rq->top_tasks_bitmap[curr]);
return;
}
/*
* The window has rolled over for this task. By the time we get
* here, curr/prev swaps would has already occurred. So we need
* to use prev_window for the new index. ***有new window的情况下,分2部分计算,一部分时prev_window;另一部分时curr_window***
*/
update_index = load_to_index(prev_window);
if (full_window) {
/*
* Two cases here. Either 'p' ran for the entire window or
* it didn't run at all. In either case there is no entry
* in the prev table. If 'p' ran the entire window, we just
* need to create a new entry in the prev table. In this case
* update_index will be correspond to sched_ravg_window
* so we can unconditionally update the top index.
*/
if (prev_window) {
prev_table[update_index] += 1;
rq->prev_top = update_index;
}
if (prev_table[update_index] == 1)
__set_bit(NUM_LOAD_INDICES - update_index - 1,
rq->top_tasks_bitmap[prev]);
} else {
zero_index_update = !old_curr_window && prev_window;
if (old_index != update_index || zero_index_update) {
if (old_curr_window)
prev_table[old_index] -= 1;
prev_table[update_index] += 1;
if (update_index > rq->prev_top)
rq->prev_top = update_index;
if (!prev_table[old_index])
__clear_bit(NUM_LOAD_INDICES - old_index - 1,
rq->top_tasks_bitmap[prev]);
if (prev_table[update_index] == 1)
__set_bit(NUM_LOAD_INDICES - update_index - 1,
rq->top_tasks_bitmap[prev]);
}
}
if (curr_window) {
curr_table[new_index] += 1;
if (new_index > rq->curr_top)
rq->curr_top = new_index;
if (curr_table[new_index] == 1)
__set_bit(NUM_LOAD_INDICES - new_index - 1,
rq->top_tasks_bitmap[curr]);
}
}
=================
3. 在window滚动期间,当task busy time超过了预测的demand,那么就要更新预测的demand。
/* * predictive demand of a task is calculated at the window roll-over. * if the task current window busy time exceeds the predicted * demand, update it here to reflect the task needs. */ void update_task_pred_demand(struct rq *rq, struct task_struct *p, int event) { u32 new, old; u16 new_scaled; if (!sched_predl) return; if (is_idle_task(p) || exiting_task(p)) return; if (event != PUT_PREV_TASK && event != TASK_UPDATE && (!SCHED_FREQ_ACCOUNT_WAIT_TIME || (event != TASK_MIGRATE && event != PICK_NEXT_TASK))) return; /* * TASK_UPDATE can be called on sleeping task, when its moved between * related groups */ if (event == TASK_UPDATE) { if (!p->on_rq && !SCHED_FREQ_ACCOUNT_WAIT_TIME) return; } new = calc_pred_demand(rq, p); //计算新的demand,计算方法与1.1.1的get_pred_busy的一样 old = p->ravg.pred_demand; if (old >= new) //不需要更新就return return; new_scaled = scale_demand(new); if (task_on_rq_queued(p) && (!task_has_dl_policy(p) || //更新cum_window_demand_scaled,与1.1中一样 !p->dl.dl_throttled) && p->sched_class->fixup_walt_sched_stats) p->sched_class->fixup_walt_sched_stats(rq, p, p->ravg.demand_scaled, new_scaled); p->ravg.pred_demand = new; //更新预测的pred_demand和pred_demand_sclaed p->ravg.pred_demand_scaled = new_scaled; }
=================
4. 并且根据判断是否需要调节cpu freq。如果是task迁移,还需要判断是否wake up cluster/core。
static inline void run_walt_irq_work(u64 old_window_start, struct rq *rq) { u64 result; if (old_window_start == rq->window_start) //过滤,防止循环调用 return; result = atomic64_cmpxchg(&walt_irq_work_lastq_ws, old_window_start, rq->window_start); if (result == old_window_start) irq_work_queue(&walt_cpufreq_irq_work); //调用walt_irq_work }
static void walt_init_once(void) { ... init_irq_work(&walt_cpufreq_irq_work, walt_irq_work); ... }
/* * Runs in hard-irq context. This should ideally run just after the latest * window roll-over. */ void walt_irq_work(struct irq_work *irq_work) { struct sched_cluster *cluster; struct rq *rq; int cpu; u64 wc; bool is_migration = false, is_asym_migration = false; u64 total_grp_load = 0, min_cluster_grp_load = 0; int level = 0; /* Am I the window rollover work or the migration work? */ if (irq_work == &walt_migration_irq_work) is_migration = true; for_each_cpu(cpu, cpu_possible_mask) { if (level == 0) raw_spin_lock(&cpu_rq(cpu)->lock); else raw_spin_lock_nested(&cpu_rq(cpu)->lock, level); level++; } wc = sched_ktime_clock(); walt_load_reported_window = atomic64_read(&walt_irq_work_lastq_ws); for_each_sched_cluster(cluster) { //遍历每个cluster、每个cpu u64 aggr_grp_load = 0; raw_spin_lock(&cluster->load_lock); for_each_cpu(cpu, &cluster->cpus) { rq = cpu_rq(cpu); if (rq->curr) { update_task_ravg(rq->curr, rq, //调用update_task_tavg,更新 TASK_UPDATE, wc, 0); account_load_subtractions(rq); //统计curr/prev_runnable_sum、nt_curr/prev_runnable_sum减去load_subtracion;衰减可能时为了防止参数一直往上涨 aggr_grp_load += rq->grp_time.prev_runnable_sum; //统计cluster的load } if (is_migration && rq->notif_pending && cpumask_test_cpu(cpu, &asym_cap_sibling_cpus)) { is_asym_migration = true; rq->notif_pending = false; } } cluster->aggr_grp_load = aggr_grp_load; total_grp_load += aggr_grp_load; //统计总load if (is_min_capacity_cluster(cluster)) min_cluster_grp_load = aggr_grp_load; raw_spin_unlock(&cluster->load_lock); } if (total_grp_load) { if (cpumask_weight(&asym_cap_sibling_cpus)) { u64 big_grp_load = total_grp_load - min_cluster_grp_load; for_each_cpu(cpu, &asym_cap_sibling_cpus) cpu_cluster(cpu)->aggr_grp_load = big_grp_load; } rtgb_active = is_rtgb_active(); } else { rtgb_active = false; } if (!is_migration && sysctl_sched_user_hint && time_after(jiffies, sched_user_hint_reset_time)) sysctl_sched_user_hint = 0; for_each_sched_cluster(cluster) { cpumask_t cluster_online_cpus; unsigned int num_cpus, i = 1; cpumask_and(&cluster_online_cpus, &cluster->cpus, cpu_online_mask); num_cpus = cpumask_weight(&cluster_online_cpus); for_each_cpu(cpu, &cluster_online_cpus) { int flag = SCHED_CPUFREQ_WALT; rq = cpu_rq(cpu); if (is_migration) { if (rq->notif_pending) { flag |= SCHED_CPUFREQ_INTERCLUSTER_MIG; rq->notif_pending = false; } } if (is_asym_migration && cpumask_test_cpu(cpu, &asym_cap_sibling_cpus)) flag |= SCHED_CPUFREQ_INTERCLUSTER_MIG; if (i == num_cpus) cpufreq_update_util(cpu_rq(cpu), flag); //调节cpu freq else cpufreq_update_util(cpu_rq(cpu), flag | //flag:维持cpu freq SCHED_CPUFREQ_CONTINUE); i++; } } for_each_cpu(cpu, cpu_possible_mask) raw_spin_unlock(&cpu_rq(cpu)->lock); if (!is_migration) core_ctl_check(this_rq()->window_start); //task迁移的话,要确认是否需要wake up cluster/core }
2. IRQ load统计
在irq触发时,会调用到函数:irqtime_account_irq
/* * Called before incrementing preempt_count on {soft,}irq_enter * and before decrementing preempt_count on {soft,}irq_exit. */ void irqtime_account_irq(struct task_struct *curr) { ... #ifdef CONFIG_SCHED_WALT u64 wallclock; bool account = true; #endif ... #ifdef CONFIG_SCHED_WALT wallclock = sched_clock_cpu(cpu); #endif delta = sched_clock_cpu(cpu) - irqtime->irq_start_time; irqtime->irq_start_time += delta; /* * We do not account for softirq time from ksoftirqd here. * We want to continue accounting softirq time to ksoftirqd thread * in that case, so as not to confuse scheduler with a special task * that do not consume any time, but still wants to run. ***我们不想统计从ksoftirqd跑到这里的softirq时间。但仍然会基线统计跑到ksoftirqd线程的softirq时间*** */ if (hardirq_count()) irqtime_account_delta(irqtime, delta, CPUTIME_IRQ); else if (in_serving_softirq() && curr != this_cpu_ksoftirqd()) irqtime_account_delta(irqtime, delta, CPUTIME_SOFTIRQ); #ifdef CONFIG_SCHED_WALT else account = false; if (account) sched_account_irqtime(cpu, curr, delta, wallclock); //统计irqtime else if (curr != this_cpu_ksoftirqd()) sched_account_irqstart(cpu, curr, wallclock); #endif }
其中delta是irq运行的时间,因为delta原先数值是irq开始时间到执行函数irqtime_account_irq的时间差值,现在执行到sched_account_irqtime函数,由于中间经过了很多代码指令的执行,再次校正delta数值:delta += sched_clock - wallclock(上次系统时间)
void sched_account_irqtime(int cpu, struct task_struct *curr, u64 delta, u64 wallclock) { struct rq *rq = cpu_rq(cpu); unsigned long flags, nr_windows; u64 cur_jiffies_ts; raw_spin_lock_irqsave(&rq->lock, flags); /* * cputime (wallclock) uses sched_clock so use the same here for * consistency. */ delta += sched_clock() - wallclock; //更新跑到这里的irqtime cur_jiffies_ts = get_jiffies_64(); if (is_idle_task(curr)) //如果变为idle了,更新task load/cpu load等。 update_task_ravg(curr, rq, IRQ_UPDATE, sched_ktime_clock(), delta); nr_windows = cur_jiffies_ts - rq->irqload_ts; //计算当前irq的时间距离上次irq的间隔jiffies if (nr_windows) { if (nr_windows < 10) { //如果间隔时间小于10个window,就要衰减为原先的3/4:avg_irq_load = 原先avg_irqload * 0.75 /* Decay CPU's irqload by 3/4 for each window. */ rq->avg_irqload *= (3 * nr_windows); rq->avg_irqload = div64_u64(rq->avg_irqload, 4 * nr_windows); } else { rq->avg_irqload = 0; //间隔>=10个window,avg_irq_load = 0(总结:如果一个rq上的cpu irq中断时间间隔比较长,那么它的avg_irqload就可以忽略不计) } rq->avg_irqload += rq->cur_irqload; //统计好cur_irqload,清0,为了下面更新此值 rq->cur_irqload = 0; } rq->cur_irqload += delta; //更新cur_irqload rq->irqload_ts = cur_jiffies_ts; //更新irqload时间戳 raw_spin_unlock_irqrestore(&rq->lock, flags); }
irqload是否high的判断:
__read_mostly unsigned int sysctl_sched_cpu_high_irqload = (10 * NSEC_PER_MSEC); static inline int sched_cpu_high_irqload(int cpu) { return sched_irqload(cpu) >= sysctl_sched_cpu_high_irqload; //10ms }
#define SCHED_HIGH_IRQ_TIMEOUT 3 static inline u64 sched_irqload(int cpu) { struct rq *rq = cpu_rq(cpu); s64 delta; delta = get_jiffies_64() - rq->irqload_ts; /* * Current context can be preempted by irq and rq->irqload_ts can be * updated by irq context so that delta can be negative. * But this is okay and we can safely return as this means there * was recent irq occurrence. */ if (delta < SCHED_HIGH_IRQ_TIMEOUT) //如果当前时间距离上次irq间隔>=3(应该是3个tick),则认为irq load为0 return rq->avg_irqload; else return 0; }
high irqload影响EAS:
调用路径:find_energy_efficient_cpu() --> find_best_target() --> sched_cpu_high_irqload()
路径是为了在sched domain里面找到最佳的cpu,之后将task迁移过去;如果 cpu irqload为 high,那么则说明此cpu不合适,继续遍历其他cpu。这个也是负载均衡的一部分。
-
WALT结果用途
1. 负载均衡(task migration)
以can_migrate_task()函数为例:
通过task_util()获取该task的demand,即task级负载
cpu_util_cum()获取cpu rq的累计demand,即cpu级负载
如果 dst_cpu累计demand + task_demand > src_cpu累计demand + task_demand,那么说明不满足迁移条件。
/* * can_migrate_task - may task p from runqueue rq be migrated to this_cpu? */ static int can_migrate_task(struct task_struct *p, struct lb_env *env) { ... demand = task_util(p); //获取task负载 util_cum_dst = cpu_util_cum(env->dst_cpu, 0) + demand; //cpu_util_cum获取cpu负载 util_cum_src = cpu_util_cum(env->src_cpu, 0) - demand; if (util_cum_dst > util_cum_src) return 0; ... }
还有文章前面讲到的irqload、预测的demand都会影响负载均衡。
2. CPU freq调节
一共有如下3条路径的函数来通过WALT修改cpu freq,
- walt_irq_work():walt中断工作
- scheduler_tick():周期调度中early detection情况(调度器发现已存在task处于runnable状态超过了SCHED_EARLY_DETECTION_DURATION,那么调度器就会通知governor接下来,需要提高cpu freq,具体解释如下)
A further enhancement during boost is the scheduler' early detection feature. While boost is in effect the scheduler checks for the precence of tasks that have been runnable for over some period of time within the tick. For such tasks the scheduler informs the governor of imminent need for high frequency. If there exists a task on the runqueue at the tick that has been runnable for greater than SCHED_EARLY_DETECTION_DURATION amount of time, it notifies the governor with a fabricated load of the full window at the highest frequency. The fabricated load is maintained until the task is no longer runnable or until the next tick.
- try_to_wake_up():进程唤醒
walt_irq_work() scheduler_tick() --> flag = SCHED_CPUFREQ_WALT --> cpufreq_update_util(cpu_rq(cpu),flag) try_to_wake_up() 调节频率有两种governoer,分别为原先的[CPU FREQ governors] 以及新的[schedtuil governors] 1、CPU FREQ governor static void gov_set_update_util(struct policy_dbs_info *policy_dbs, unsigned int delay_us) { ... cpufreq_add_update_util_hook(cpu, &cdbs->update_util, dbs_update_util_handler); ... } 2、[schedutil] cpu freq governors static int sugov_start(struct cpufreq_policy *policy) { ... cpufreq_add_update_util_hook(cpu, &sg_cpu->update_util, policy_is_shared(policy) ? sugov_update_shared : sugov_update_single); ... }
当前以schedutil为例:
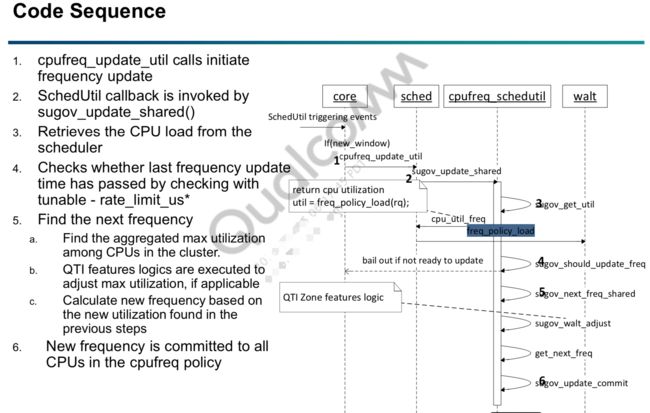
其中,在walt.c的 freq_policy_load中,会返回WALT计算的load(util),用于sugov_next_freq_shared中计算新的cpu freq。
static inline u64 freq_policy_load(struct rq *rq) { unsigned int reporting_policy = sysctl_sched_freq_reporting_policy; struct sched_cluster *cluster = rq->cluster; u64 aggr_grp_load = cluster->aggr_grp_load; u64 load, tt_load = 0; struct task_struct *cpu_ksoftirqd = per_cpu(ksoftirqd, cpu_of(rq)); if (rq->ed_task != NULL) { //early detection task的情况,load = 一个window的长度(20ms) load = sched_ravg_window; goto done; } if (sched_freq_aggr_en) //freq聚合影响不同的load计算,在sched_boost设置为full_throttle_boost和restrained_boost时enable,退出时disable load = rq->prev_runnable_sum + aggr_grp_load; else load = rq->prev_runnable_sum + rq->grp_time.prev_runnable_sum; if (cpu_ksoftirqd && cpu_ksoftirqd->state == TASK_RUNNING) load = max_t(u64, load, task_load(cpu_ksoftirqd)); //如果正在执行软中断的load tt_load = top_task_load(rq); //获取top task的load switch (reporting_policy) { //根据不同的report policy,选择load上报 case FREQ_REPORT_MAX_CPU_LOAD_TOP_TASK: load = max_t(u64, load, tt_load); //取其中最大的load break; case FREQ_REPORT_TOP_TASK: load = tt_load; break; case FREQ_REPORT_CPU_LOAD: break; default: break; } if (should_apply_suh_freq_boost(cluster)) { //是否需要apply freq boost if (is_suh_max()) load = sched_ravg_window; else load = div64_u64(load * sysctl_sched_user_hint, (u64)100); } done: trace_sched_load_to_gov(rq, aggr_grp_load, tt_load, sched_freq_aggr_en, load, reporting_policy, walt_rotation_enabled, sysctl_sched_user_hint); return load; }
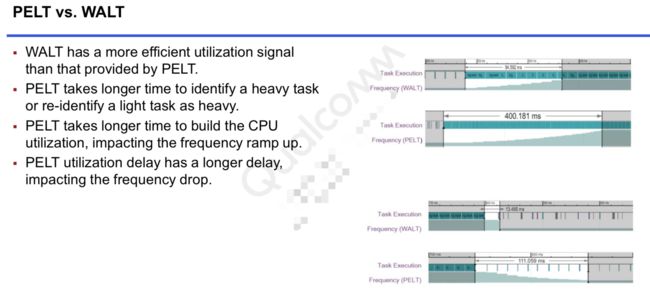
WALT vs PELT
总结一下WALT的优点:
1、识别heavy task的速度更快。
2、针对cpu util的计算快,从而可以更快控制cpu freq上升和下降。
cumulative_runnable_avg_scaled