hive+hbase+zookeeper+spark2.3.0环境搭建
集群配置说明
安装图
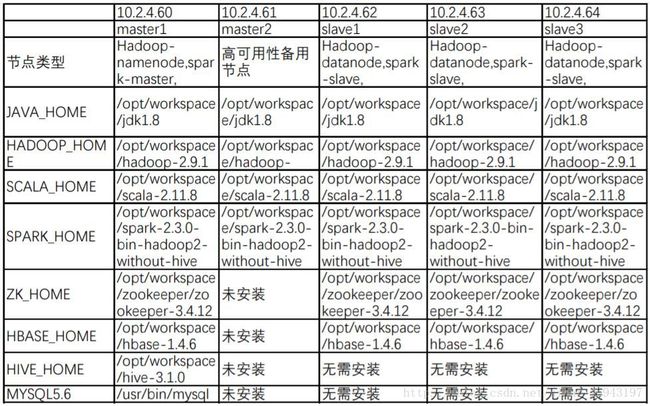
配置说明
JDK :Hadoop和Spark 依赖的配置,官方建议JDK版本在1.7以上!!!
Scala:Spark依赖的配置,建议版本不低于spark的版本。
Hadoop: 是一个分布式系统基础架构。
Spark: 分布式存储的大数据进行处理的工具。
zookeeper:分布式应用程序协调服务,HBase集群需要。
HBase: 一个结构化数据的分布式存储系统。
Hive: 基于Hadoop的一个数据仓库工具,目前的默认元数据库是mysql。
1.spark2.3.0环境安装和启动
根据spark Application的Driver Program是否在集群中运行,spark应用的运行方式又可以分为Cluster模式和Client模式。
1.编译spark2.3.0源码
spark里面是包含spark-sql的,spark-sql是使用修改过的hive和spark相结合的组件,因为spark-sql里面的hive和我们用的hive2.3版本冲突,所以这里用源代码重新编译,去掉里面的spark-sql里面的hive,编译过后的spark是不能使用spark-sql功能的。
编译spark需要maven3.3.9,scala2.11.8,jdk1.8
下载链接spark2.3.0源码
下载后解压缩保存到/opt/workspace/目录下,下载maven并配置好环境变量,将下载源配置到国内;
2.对conf目录下的文件做配置
1.配置spark-env.sh
cp spark-env.sh.template spark-env.sh
添加如下配置
export SCALA_HOME=/opt/workspace/scala-2.11.8
export JAVA_HOME=/opt/workspace/jdk1.8
export HADOOP_HOME=/opt/workspace/hadoop-2.9.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/workspace/spark-2.3.0-bin-hadoop2-without-hive
export SPARK_CONF_DIR=$SPARK_HOME/conf
export SPARK_EXECUTOR_MEMORY=5120M
export SPARK_DIST_CLASSPATH=$(/opt/workspace/hadoop-2.9.1/bin/hadoop classpath)2.配置slaves
cp spark-defaults.conf.template spark-defaults.conf
修改其中内容
slave1
slave2
slave33.修改spark-default.conf文件
根据模板复制
cp spark-defaults.conf.template spark-defaults.conf
添加如下内容
spark.master yarn-cluster
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 4g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value-Dnumbers="one two three"4.在hdfs上创建目录
因为上面的配置中让spark将eventLog存到HDFS的directory目录下,所以需要执行hadoop命令,在HDFS上创建directory目录,创建目录命令是:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /directory
$HADOOP_HOME/bin/hadoop fs -chmod 777 /directory5.启动spark
进入sbin目录
[root@master1 sbin]# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/workspace/spark-2.3.0-bin-hadoop2-without-hive/logs/spark-root-org.apache.spark.deploy.master.Master-1-master1.out
slave3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/workspace/spark-2.3.0-bin-hadoop2-without-hive/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave3.out
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/workspace/spark-2.3.0-bin-hadoop2-without-hive/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/workspace/spark-2.3.0-bin-hadoop2-without-hive/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out
[root@master1 sbin]# jps
9296 QuorumPeerMain
9939 HMaster
28005 ResourceManager
12522 Master
27834 SecondaryNameNode
27626 NameNode
12620 Jps2.MySQL安装配置
本集群搭建环境为CentOS7,yum源中默认没有MySQL,需要先下载yum源
1.下载mysql的repo源
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
2.安装rpm包
rpm -ivh mysql-community-release-el7-5.noarch.rpm安装这个包后,会获得两个mysql的yum repo源:
/etc/yum.repos.d/mysql-community.repo
/etc/yum.repos.d/mysql-community-source.repo3.安装MySQL-server
$ sudo yum install mysql-server[root@master1 mysql]# service mysqld start
[root@master1 mysql]# mysql -u root
mysql> set password for 'root'@'localhost' =password('123456');
Query OK, 0 rows affected (0.00 sec)[root@master1 mysql]# mysql -uroot -p123456
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
+--------------------+
3 rows in set (0.00 sec)mysql的几个重要目录
#(a)数据库目录
/var/lib/mysql/
#(b)配置文件
/usr/share /mysql(mysql.server命令及配置文件)
#(c)相关命令
/usr/bin(mysqladmin mysqldump等命令)
#(d)启动脚本
/etc/rc.d/init.d/(启动脚本文件mysql的目录)3.Zookeeper的环境配置
1.下载源码
地址http://mirror.bit.edu.cn/apache/zookeeper/
mkdir /opt/workspace/zookeeper下载稳定版本,解压缩到/opt/workspace/zookeeper目录
2.环境配置
#Zookeeper Config
export ZK_HOME=/opt/workspace/zookeeper/zookeeper-3.4.12
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${HIVE_HOME}/bin:${SPARK_HOME}/bin:${HBASE_HOME}/bin:$SQOOP_HOME/bin:${ZK_HOME}/bin:$PATHsource /etc/profile3.修改配置文件
1.在集群的服务器上都创建这些目录
切换到/opt/workspace/zookeeper/目录,执行以下命令
mkdir zookeeper/data
mkdir zookeeper/datalog并在/opt/workspace/zookeeper/data目录下创建myid文件
touch myid为了方便,将master1、slave1、slave2、slave3的myid文件内容改为1,3,4,5
2.修改zoo.cfg文件
复制zoo_sample.cfg文件并重命名为zoo.cfg
dataDir=/opt/workspace/zookeeper/data
dataLogDir=/opt/workspace/zookeeper/datalog
server.1=master1:2888:3888
server.3=slave1:2888:3888
server.4=slave2:2888:3888
server.5=slave3:2888:3888说明:client port,顾名思义,就是客户端连接zookeeper服务的端口。这是一个TCP port。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。
1.tickTime:CS通信心跳数
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=10
3.syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=5
依旧将zookeeper传输到其他的机器上
3.启动zookeeper
切换到/opt/workspace/zookeeper/zookeeper-3.4.12/bin目录下,执行
zkServer.sh start注:成功配置zookeeper之后,需要在每台机器上启动zookeeper
在所有节点启动后,等待一段时间查看即可
[root@master1 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/workspace/zookeeper/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: follower
[root@slave3 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/workspace/zookeeper/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: leader4.HBase安装
1.下载源码
地址http://mirrors.shu.edu.cn/apache/hbase/
下载stable版源码
解压缩到/opt/workspace目录
2.环境配置
编辑/etc/profile文件
# HBase Config
export HBASE_HOME=/opt/workspace/hbase-1.4.6
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${HIVE_HOME}/bin:${SPARK_HOME}/bin:${HBASE_HOME}/bin:$SQOOP_HOME/bin:$PATH使配置生效
source /etc/profile查看版本
[root@master1 hbase-1.4.6]# hbase version
HBase 1.4.6
Source code repository git://apurtell-ltm4.internal.salesforce.com/Users/apurtell/src/hbase revision=a55bcbd4fc87ff9cd3caaae25277e0cfdbb344a5
Compiled by apurtell on Tue Jul 24 16:25:52 PDT 2018
From source with checksum 265f6798aa3f8da7100f0d0f243de9213.修改配置文件
切换到/opt/workspace/hbase-1.4.6/conf
1.修改hbase.env.sh文件
编辑 hbase-env.sh 文件,添加以下配置
export JAVA_HOME=/opt/workspace/jdk1.8
export HADOOP_HOME=/opt/workspace/hadoop-2.9.1
export HBASE_HOME=/opt/workspace/hbase-1.4.6
export HBASE_CLASSPATH=$HADOOP_HOME/etc/hadoop
export HBASE_PID_DIR=/root/hbase/pids
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=${HBASE_HOME}/logsHBASE_MANAGES_ZK=false 是不启用HBase自带的Zookeeper集群。
2.修改 hbase-site.xml
<property>
<name>hbase.rootdirname>
<value>hdfs://master1:9000/hbasevalue>
<description>The directory shared byregion servers.description>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
<property>
<name>zookeeper.session.timeoutname>
<value>120000value>
property>
<property>
<name>hbase.master.maxclockskewname>
<value>150000value>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>master1,slave1,slave2,slave3value>
property>
<property>
<name>hbase.tmp.dirname>
<value>/root/hbase/tmpvalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.mastername>
<value>master1:60000value>
property>其中hbase.rootdir配置的是hdfs地,用来持久化Hbase,ip:port要和hadoop/core-site.xml中的fs.defaultFS保持一致。hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式
3.修改regionservers
指定hbase的主从,和hadoop的slaves文件配置一样
slave1
slave2
slave3最后将环境传输到其他主机
5.配置Hive
1.下载hive包
对照官网,下载对应的hive包。
Hive on spark官网指南
hive源码http://mirrors.hust.edu.cn/apache/hive/
下载3.1.0并解压缩,移动到/opt/workspace/目录下
2.在lib目录下加入相应的jar包
Since Hive 2.2.0, Hive on Spark runs with Spark 2.0.0 and above, which doesn’t have an assembly jar. To run with YARN mode (either yarn-client or yarn-cluster), link the following jars to HIVE_HOME/lib.
- scala-library
- spark-core
- spark-network-common
加入jdbc驱动
cp mysql-connector-java-8.0.12.jar /opt/workspace/hive-3.1.0/lib/3.配置hive-site.xml文件
首先在master机器上上创建临时目录/opt/workspace/tmp-hive
将hive-site.xml文件中的所有${system:java.io.tmpdir}替换为
/opt/workspace/tmp-hive
将hive-site.xml文件中的所有${system:user.name}都替换为root
在/opt/workspace/hive-3.1.0/conf执行cp hive-default.xml.template hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://10.2.4.60:3306/hive1?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8value>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
<description>Username to use against metastore databasedescription>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
<description>password to use against metastore databasedescription>
property>
<property>
<name>hive.execution.enginename>
<value>sparkvalue>
property>
<property>
<name>hive.enable.spark.execution.enginename>
<value>truevalue>
property>
<property>
<name>spark.mastername>
<value>yarn-clustervalue>
property>
<property>
<name>spark.serializername>
<value>org.apache.spark.serializer.KryoSerializervalue>
property>
<property>
<name>spark.eventLog.enabledname>
<value>truevalue>
property>
<property>
<name>spark.eventLog.dirname>
<value>hdfs://master:9000/directoryvalue>
property>
<property>
<name>spark.executor.instancesname>
<value>3value>
property>
<property>
<name>spark.executor.coresname>
<value>5value>
property>
<property>
<name>spark.executor.memoryname>
<value>5120mvalue>
property>
<property>
<name>spark.driver.coresname>
<value>2value>
property>
<property>
<name>spark.driver.memoryname>
<value>4096mvalue>
property>4.配置hive-env.sh文件
cp hive-env.sh.template hive-env.shexport HADOOP_HEAPSIZE=4096
export HADOOP_HOME=/opt/workspace/hadoop-2.9.1
export HIVE_CONF_DIR=/opt/workspace/hive-3.1.0/conf
export HIVE_AUX_JARS_PATH=/opt/workspace/hive-3.1.0/lib5.初始化hive
初始化
[root@master1 bin]# schematool -initSchema -dbType mysql Metastore connection URL: jdbc:mysql://10.2.4.60:3306/hive1?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sql
Initialization script completed
schemaTool completed出现以上信息即初始化成功
6.启动hive
[root@master1 hive-3.1.0]# cd bin
[root@master1 bin]# ./hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/workspace/hbase-1.4.6/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/workspace/hadoop-2.9.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2018-08-23 20:15:27,108 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Hive Session ID = 5d68f66b-dc5a-4f3b-b080-0a4dd57a5a16
Logging initialized using configuration in jar:file:/opt/workspace/hive-3.1.0/lib/hive-common-3.1.0.jar!/hive-log4j2.properties Async: true
Hive Session ID = 03da6ad2-295f-4264-b2e4-b955fe975f2a
hive>成功
Errors
1.初始化hive失败
[root@master1 bin]# schematool -initSchema -dbType mysql
Metastore connection URL: jdbc:mysql://10.2.4.60:3306/hive1?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: java.sql.SQLException : Access denied for user 'root'@'master1' (using password: YES)
SQL Error code: 1045
Use --verbose for detailed stacktrace.
*** schemaTool failed ***错误一:This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver’.
解决:因安装的最新版本的jdbc驱动,更改hive-site.xml文件中jdbc driver的name为com.mysql.cj.jdbc.Driver
javax.jdo.option.ConnectionDriverName
com.mysql.cj.jdbc.Driver 错误二:Access denied for user ‘root’@’master1’ (using password: YES)
解决:授权
设置用户root可以在任意IP下被访问:
mysql> grant all privileges on *.* to root@"%" identified by '123456';
Query OK, 0 rows affected (0.00 sec)
设置用户root可以在本地被访问:
mysql> grant all privileges on *.* to root@"localhost" identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> grant all privileges on *.* to root@"master1" identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
再次初始化
[root@master1 bin]# schematool -initSchema -dbType mysql Metastore connection URL: jdbc:mysql://10.2.4.60:3306/hive1?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sql
Initialization script completed
schemaTool completed出现以上信息即初始化成功
错误三:jar包冲突
解决:删除hive中$HIVE_HOME/lib下面的log4j-slf4j-impl-2.10.0.jar
不要删除hadoop下面的,否则调用shell 脚本start-all.sh远程启动hadoop时会报找不到log4j包的错误。
2.zookeeper启动错误
若某些节点未启动
[root@slave3 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/workspace/zookeeper/zookeeper-3.4.12/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.zookeeper.out中错误信息:
2018-08-23 16:53:02,147 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@584] - Cannot open channel to 4 at election address slave2/10.2.4.63:3888
java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:558)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:534)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:454)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:435)
at java.lang.Thread.run(Thread.java:748)启动所有节点后等待一段时间再次查看,若依然有错
1.查看zookeeper的端口2181是否已经被占用了
[root@master1 hive-3.1.0]# netstat -apn | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 9296/java若2181端口被占用,使用kill -9 端口号杀掉进程
再次尝试启动
2.如果上面的操作还解决不了问题,那么我们接着到/opt/workspace/zookeeper/data目录下,可以看到如下所示的文件
[root@master1 data]# ls
myid version-2 zookeeper_server.pid
删除version-2 、zookeeper_server.pid两个文件
再次尝试启动
参考:
hive on spark安装(hive2.3 spark2.1)
hive on spark入门安装(hive2.0、spark1.5)
centos7安装mysql并jdbc测试
hive常见问题解决
解决Zookeeper无法启动的问题
大数据学习系列之七 —– Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
Linux搭建Hive On Spark环境(spark-1.6.3-without-hive+hadoop2.8.0+hive2.1.1)