练习题︱ python 协同过滤ALS模型实现:商品推荐 + 用户人群放大
之前的一个练习题:练习题︱豆瓣图书的推荐与搜索、简易版知识引擎构建(neo4j)提及了几种简单的推荐方式。
但是在超大规模稀疏数据上,一般会采用一些规模化的模型,譬如spark-ALS就是其中一款。
这边,笔者也是想调研一下这个模型的操作性,所有就先用单机版的测试一下;对应的spark.mlib有分布式的版本。
练习代码可见:mattzheng/pyALS
文章目录
- 1 ALS算法 - Alternating Least Square - 交替最小二乘法
- 1.1 理论介绍
- 1.2 58同城的推荐场景实战
- 2 pyALS
- 2.1 商品推荐
- 2.2 人群放大
1 ALS算法 - Alternating Least Square - 交替最小二乘法
1.1 理论介绍
参考:
在线图书推荐系统的实现含源码(协同过滤)
如何解释spark mllib中ALS算法的原理?
是协同过滤的一种,并被集成到Spark的Mllib库中。
对于一个users-products-rating的评分数据集,ALS会建立一个userproduct的mn的矩阵其中,m为users的数量,n为products的数量但是在这个数据集中,并不是每个用户都对每个产品进行过评分,所以这个矩阵往往是稀疏的,
用户i对产品j的评分往往是空的ALS所做的事情就是将这个稀疏矩阵通过一定的规律填满,这样就可以从矩阵中得到任意一个user对任意一个product的评分,ALS填充的评分项也称为用户i对产品j的预测得分所以说,ALS算法的核心就是通过什么样子的规律来填满。

矩阵因子分解(如奇异值分解,奇异值分解+ +)将项和用户都转化成了相同的潜在空间,它所代表了用户和项之间的潜相互作用。矩阵分解背后的原理是潜在特征代表了用户如何给项进行评分。给定用户和项的潜在描述,我们可以预测用户将会给还未评价的项多少评分。

优势:
- 支持训练
- 不用输入一个超大matrix矩阵
劣势:
- 不支持全新的内容输入,用户ID只能是现有的
- 增量训练不支持
输入训练:
# [[1, 1, 4.0], [1, 3, 4.0], [1, 6, 4.0], [1, 47, 5.0], [1, 50, 5.0]]
# (用户ID,购物ID,评分)
全部应用用户ID/购物ID即可。
关于增量训练:
在文章在线图书推荐系统的实现含源码(协同过滤)中是,我们借用Spark的ALS算法的训练和预测函数,每次收到新的数据后,将其更新到训练数据集中,然后更新ALS训练得到的模型。
感觉是全部重新训练?
1.2 58同城的推荐场景实战
相对来说,在一些推荐场景该方法还是有一定效力的【参考:Embedding技术在房产推荐中的应用】:

在这些推荐场景中都离不开两类相似性的计算:
- 一类是用户和房源之间的相关性
- 另一类是两个房源之间的相关性。
具体该怎么计算这两类相关性呢?我们首先需要把房源和用户这两个实体用向量表征出来,然后通过计算向量的差异,衡量用户和房源、房源和房源是否相似。
用户矩阵和评分矩阵都有“豪华指数”和“刚需指数”这两个维度。当然这两个维度的表述是我们在矩阵分解完成之后,人为总结的。其实,用户矩阵和物品矩阵可以理解为针对用户和房源的Embedding。从用户矩阵中可以看出,User1对豪宅的偏好度比较高,所以他对耀华路550弄不太感兴趣。同时,从物品矩阵中可以看出,汤臣一品和上海康城的相似度应该是大于汤臣一品和耀华路550弄的相似度。

2 pyALS
这边感谢 协同过滤(ALS)的原理及Python实现手写了一个版本,可以便于做小规模的测试als.py
这边笔者在此基础上进行了一些测试性工作。
训练步骤:
- 数据预处理
- 变量k合法性检查
- 生成随机矩阵U
- 交替计算矩阵U和矩阵I,并打印RMSE信息,直到迭代次数达到max_iter
- 保存最终的RMSE
2.1 商品推荐
所使用的数据是【用户ID,电影ID,评分数据】

先是训练环节:
# 加载数据
path = 'data/movie_ratings.csv'
X = load_movie_ratings(path) # 100836
# [[1, 1, 4.0], [1, 3, 4.0], [1, 6, 4.0], [1, 47, 5.0], [1, 50, 5.0]]
# (用户ID,购物ID,评分)
# 训练模型
from ALS.pyALS import ALS
model = ALS()
model.fit(X, k=20, max_iter=2)
>>> Iterations: 1, RMSE: 3.207636
>>> Iterations: 2, RMSE: 0.353680
其中X的格式是一个有序的列表性,K代表表征的维度,max_iter表示迭代次数。
k / max_iter越大迭代的时间就越长。
然后是预测:
# 商品推荐
print("Showing the predictions of users...")
# Predictions
user_ids = range(1, 5)
predictions = model.predict(user_ids, n_items=2)
for user_id, prediction in zip(user_ids, predictions):
_prediction = [format_prediction(item_id, score)
for item_id, score in prediction]
print("User id:%d recommedation: %s" % (user_id, _prediction))

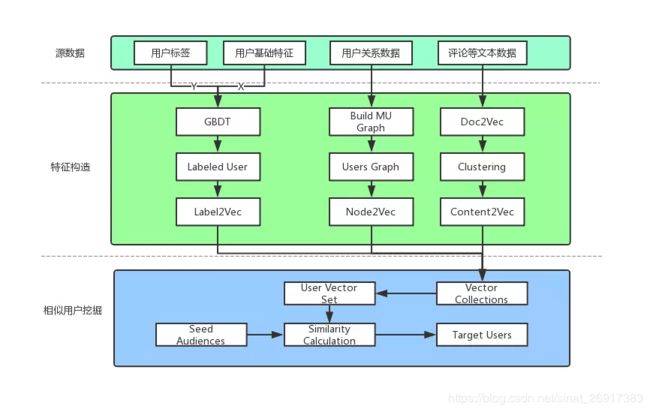
2.2 人群放大
这个模块其实实验是借助user的embedding作为用户向量来求解相似性高的人群。
大致的操作步骤为:
- 先将训练得到的用户user_embedding 和商品的item_embedding都进行.txt保存
- gensim加载
- 求人群相似
这里笔者偷懒,直接借助gensim来进行相似性求解。
# 将用户矩阵+商品矩阵,像word2vec一样进行保存
user_matrix = np.array(model.user_matrix.data)
item_matrix = np.array(model.item_matrix.data)
print(user_matrix.shape,item_matrix.shape) # ((20, 610), (20, 9724))
user_embedding = {model.user_ids[n]:user_matrix.T[n] for n in range(len(model.user_ids))}
item_embedding = {model.item_ids[n]:item_matrix.T[n] for n in range(len(model.user_ids))}
wordvec_save2txt(user_embedding,save_path = 'w2v/user_embedding_10w_50k_10i.txt',encoding = 'utf-8-sig')
wordvec_save2txt(item_embedding,save_path = 'w2v/item_embedding_10w_50k_10i.txt',encoding = 'utf-8-sig')
然后根据此用户向量来求解相似用户
embedding = gensim.models.KeyedVectors.load_word2vec_format('w2v/user_embedding_10w_50k_10i.txt',binary=False)
embedding.init_sims(replace=True) # 神奇,很省内存,可以运算most_similar
# 向量求相似
item_a = 1
simi = embedding.most_similar(str(item_a), topn=50)
#[('79', 0.9031778573989868),
# ('27', 0.882379412651062)]
当然这里单个人求解在实际使用上不可行,因为种子人群 / 总人群量级都比较大,所以一开始会需要聚类。
关于Look - Like还会有很多内容需要注意。