Python Requests post并将得到结果转换为json
编程小白一个,目前在学习python 爬虫。
之前看到一个博主说些博客对于程序员来说挺重要的,没怎么在意。今天觉得面对一个问题好不容易找到解决方案,是应该记录一下。说不定还有人来讨论讨论,哈哈!
之前开始接触用scrapy批量抓取网页,一直很怕面对要调用JS的内容,因为对JS和http request完全不懂,这次遇到一个小地方需要分析url请求,只能硬着头皮上了,东查查西问问的。遇到问题不能怕,虽然会费点时间解决,但是这就是学习的过程。一直不挑战就一直不会成长。
这次的任务是为了获得携程飞机票对应的ticket policy 内容,只要退改签的价格。

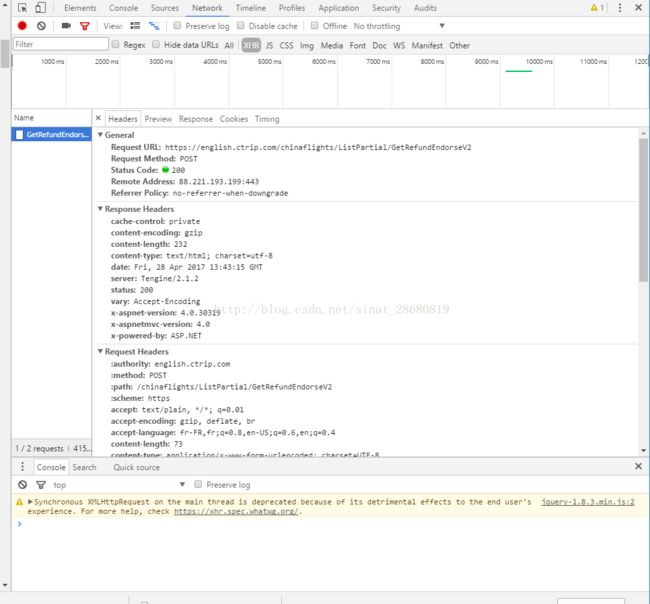
点击Ticket policy 弹出一个窗口,在chrome的开发者工具的network里查看。

分析请求,请问这里是不是用了jquery,我不是很懂这块(问题1)。之前还花了一点时间了解什么是http request....这里就不解释了,原理很好懂。
点击network了之后本来是什么的没有的,点击一下ticket policy之后再XHR里面会多出一个请求。
查看preview,我要的价格就在里面,ADUText里的内容

然后我上网搜了python request方法,
注意这里是post不是get,我一开始以为post和get差不多,语法也一样,但还是有区别的。
我先用postman试了一下,发现不写header,只写url 和body也可以返回结果,就偷懒了,不知道有什么影响 (问题2)。
小白又千辛万苦的找到了正确写request post form data的方式:
>>> import requests
>>> url="http://english.ctrip.com/chinaflights/ListPartial/GetRefundEndorseV2"
>>> payload = {"item":"1285|282|922|880|890|0.74|4|False|False|ADU|1284,280,620,0,0,0,4,False,False|"}
>>> r = requests.post(url,data=payload)
结果如下:
>>> r.text
[{"KindType":2,"Sequence":1,"TimeText":"More than 4 hours prior to departure","ADUType":0,"ADUText":"CNY 89","CHIType":0,"CHIText":null,"BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":"When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged."},{"KindType":2,"Sequence":2,"TimeText":"Within 4 hours of departure","ADUType":0,"ADUText":"CNY 178","CHIType":0,"CHIText":null,"BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":"When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged."},{"KindType":1,"Sequence":1,"TimeText":"More than 4 hours prior to departure","ADUType":0,"ADUText":"CNY 178","CHIType":0,"CHIText":"CNY 31","BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":null},{"KindType":1,"Sequence":2,"TimeText":"Within 4 hours of departure","ADUType":0,"ADUText":"CNY 356","CHIType":0,"CHIText":"CNY 62","BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":null}]
至此我的任务完成了一半,然后另一个问题来了,我怎么提取这里面的内容呢,毕竟我要的只是退票改签的费用数据而已。
朋友告诉我你把它转成json就好了
于是我又学学python json module
初次尝试代码:
>>> import json
>>> a= r.text
>>> json = json.dumps(a)
>>> print json
"[{\"KindType\":2,\"Sequence\":1,\"TimeText\":\"More than 4 hours prior to departure\",\"ADUType\":0,\"ADUText\":\"CNY 89\",\"CHIType\":0,\"CHIText\":null,\"BABType\":0,\"BABText\":null,\"HasCHI\":true,\"HasBAB\":false,\"HasADU\":true,\"ConCurrentDescription\":\"When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged.\"},{\"KindType\":2,\"Sequence\":2,\"TimeText\":\"Within 4 hours of departure\",\"ADUType\":0,\"ADUText\":\"CNY 178\",\"CHIType\":0,\"CHIText\":null,\"BABType\":0,\"BABText\":null,\"HasCHI\":true,\"HasBAB\":false,\"HasADU\":true,\"ConCurrentDescription\":\"When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged.\"},{\"KindType\":1,\"Sequence\":1,\"TimeText\":\"More than 4 hours prior to departure\",\"ADUType\":0,\"ADUText\":\"CNY 178\",\"CHIType\":0,\"CHIText\":\"CNY 31\",\"BABType\":0,\"BABText\":null,\"HasCHI\":true,\"HasBAB\":false,\"HasADU\":true,\"ConCurrentDescription\":null},{\"KindType\":1,\"Sequence\":2,\"TimeText\":\"Within 4 hours of departure\",\"ADUType\":0,\"ADUText\":\"CNY 356\",\"CHIType\":0,\"CHIText\":\"CNY 62\",\"BABType\":0,\"BABText\":null,\"HasCHI\":true,\"HasBAB\":false,\"HasADU\":true,\"ConCurrentDescription\":null}]"
看着好像做了什么转换,可是我希望的转换成字典,我不明白为什么得到的结果是这样的:(问题3)
>>> json[0]
'"'
还是一个字符串。
>>> r.content
'[{"KindType":2,"Sequence":1,"TimeText":"More than 4 hours prior to departure","ADUType":0,"ADUText":"CNY 89","CHIType":0,"CHIText":null,"BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":"When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged."},{"KindType":2,"Sequence":2,"TimeText":"Within 4 hours of departure","ADUType":0,"ADUText":"CNY 178","CHIType":0,"CHIText":null,"BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":"When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged."},{"KindType":1,"Sequence":1,"TimeText":"More than 4 hours prior to departure","ADUType":0,"ADUText":"CNY 178","CHIType":0,"CHIText":"CNY 31","BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":null},{"KindType":1,"Sequence":2,"TimeText":"Within 4 hours of departure","ADUType":0,"ADUText":"CNY 356","CHIType":0,"CHIText":"CNY 62","BABType":0,"BABText":null,"HasCHI":true,"HasBAB":false,"HasADU":true,"ConCurrentDescription":null}]'
然后我看又试了一下r.content,看着content和text的区别就是content在外面多了一对单引号。
>>> type(r.content)
>>> type(r.text)
题外话,这里我一直不明白,unicode怎么也可以是一种类型呢,我以为r.text是列表啊,而unicode是一种编码类型。。。不明白(问题4)
然后朋友直接套用他的项目代码,说他用的loads,是可以的。结果试了,还是有问题
>>> b = json.loads(r.text)
Traceback (most recent call last):
File "
AttributeError: 'str' object has no attribute 'loads'
>>> b = json.loads(r.content)
Traceback (most recent call last):
File "
AttributeError: 'str' object has no attribute 'loads'
这里我觉得我本来是字符串,可能应该用dump和load 但是结果还是一样的。
后来在python-requests高级用法里找到了解决方法
>>> c= r.json()
>>> print c
[{u'ConCurrentDescription': u'When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged.', u'TimeText': u'More than 4 hours prior to departure', u'Sequence': 1, u'CHIText': None, u'ADUText': u'CNY 89', u'CHIType': 0, u'HasADU': True, u'BABType': 0, u'HasCHI': True, u'HasBAB': False, u'BABText': None, u'KindType': 2, u'ADUType': 0}, {u'ConCurrentDescription': u'When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged.', u'TimeText': u'Within 4 hours of departure', u'Sequence': 2, u'CHIText': None, u'ADUText': u'CNY 178', u'CHIType': 0, u'HasADU': True, u'BABType': 0, u'HasCHI': True, u'HasBAB': False, u'BABText': None, u'KindType': 2, u'ADUType': 0}, {u'ConCurrentDescription': None, u'TimeText': u'More than 4 hours prior to departure', u'Sequence': 1, u'CHIText': u'CNY 31', u'ADUText': u'CNY 178', u'CHIType': 0, u'HasADU': True, u'BABType': 0, u'HasCHI': True, u'HasBAB': False, u'BABText': None, u'KindType': 1, u'ADUType': 0}, {u'ConCurrentDescription': None, u'TimeText': u'Within 4 hours of departure', u'Sequence': 2, u'CHIText': u'CNY 62', u'ADUText': u'CNY 356', u'CHIType': 0, u'HasADU': True, u'BABType': 0, u'HasCHI': True, u'HasBAB': False, u'BABText': None, u'KindType': 1, u'ADUType': 0}]
>>> print c[0]
{u'ConCurrentDescription': u'When flight changes and class upgrade both occur,both flight change fee and upgrade fee will be charged.', u'TimeText': u'More than 4 hours prior to departure', u'Sequence': 1, u'CHIText': None, u'ADUText': u'CNY 89', u'CHIType': 0, u'HasADU': True, u'BABType': 0, u'HasCHI': True, u'HasBAB': False, u'BABText': None, u'KindType': 2, u'ADUType': 0}
这里我不懂.json()这个方法了,用help查看了一下,不就是返回json编码嘛,正是我需要的,但是为什么之前查到的资料里都是用dump转换之类的,我不太明白这两个方法的区别。(问题5)
>>> help(requests.models.Response.json)
Help on method json in module requests.models:
json(self, **kwargs) unbound requests.models.Response method
Returns the json-encoded content of a response, if any.
:param \*\*kwargs: Optional arguments that ``json.loads`` takes.
:raises ValueError: If the response body does not contain valid json.
然后试了一下,果然可以按照字典查找的方法找到我要的数据了。至此我的一大难题就完成了。
>>> print c[1].keys()
[u'ConCurrentDescription', u'TimeText', u'Sequence', u'CHIText', u'ADUText', u'CHIType', u'HasADU', u'BABType', u'HasCHI', u'HasBAB', u'BABText', u'KindType', u'ADUType']
>>> print c[1]['ADUText']
CNY 178
最近一边学爬虫,一边也看了反爬虫的文章,ctrip貌似挺注重反爬虫。我之前也爬了一下网站了,没遇到什么反爬虫的,现在要爬它,有点怕啊,不知道又要搞出什么幺蛾子来。
另外其实还是一知半解的,希望有一天能搞懂这些问题。