什么是索引下推
概述
索引条件下推优化(Index Condition Pushdown (ICP) )是MySQL5.6添加的,用于优化数据查询。
- 不使用索引条件下推优化时存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件。
- 当使用索引条件下推优化时,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
网上搜了下相关的文章不少都将Index Condition Pushdown 称为索引下推优化,我认为还是索引条件下推优化更合适一些,因为这个优化技术关键的操作就是将与索引相关的条件由MySQL服务器向下传递至存储引擎,由此减少IO次数。MySQL服务器到存储引擎是向下,传递的是与索引列相关的查询条件,所以还是索引条件下推优化更容易理解一些。
适用条件
- 需要整表扫描的情况。比如:range, ref, eq_ref, ref_or_null 。适用于InnoDB 引擎和 MyISAM 引擎的查询。(5.6版本不适用分区表查询,5.7版本后可以用于分区表查询)。
- 对于InnDB引擎只适用于二级索引,因为InnDB的聚簇索引会将整行数据读到InnDB的缓冲区,这样一来索引条件下推的主要目的减少IO次数就失去了意义。因为数据已经在内存中了,不再需要去读取了。
- 引用子查询的条件不能下推。
- 调用存储过程的条件不能下推,存储引擎无法调用位于MySQL服务器中的存储过程。
- 触发条件不能下推。
工作过程
既然是优化,我们要清楚优化了些什么就要了解原本是如何工作的,所以分为两部分来描述工作过程。
不使用索引条件下推优化时的查询过程
获取下一行,首先读取索引信息,然后根据索引将整行数据读取出来。
然后通过where条件判断当前数据是否符合条件,符合返回数据。
使用索引条件下推优化时的查询过程
获取下一行的索引信息。
检查索引中存储的列信息是否符合索引条件,如果符合将整行数据读取出来,如果不符合跳过读取下一行。
用剩余的判断条件,判断此行数据是否符合要求,符合要求返回数据。
EXPLAN分析
当使用explan进行分析时,如果使用了索引条件下推,Extra会显示Using index condition。并不是Using index因为并不能确定利用索引条件下推查询出的数据就是符合要求的数据,还需要通过其他的查询条件来判断。
图一:不使用ICP技术(过程使用数字符号标示,如①②③等)
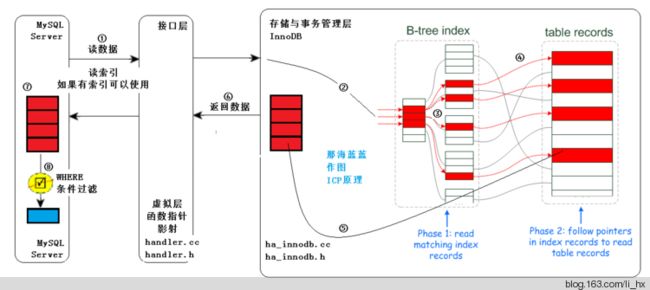
过程解释:
①:MySQL Server发出读取数据的命令,这是在执行器中执行如下代码段,通过函数指针和handle接口调用存储引擎的索引读或全表表读。此处进行的是索引读。
if (in_first_read)
{
in_first_read= false;
error= (*qep_tab->read_first_record)(qep_tab); //设定合适的读取函数,如设定索引读函数/全表扫描函数
}
else
error= info->read_record(info);②、③:进入存储引擎,读取索引树,在索引树上查找,把满足条件的(经过查找,红色的满足)从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要进行进行步骤④,通常有IO。
⑥:从存储引擎返回查找到的多条元组给MySQL Server,MySQL Server在⑦得到较多的元组。
⑦--⑧:⑦到⑧依据WHERE子句条件进行过滤,得到满足条件的元组。注意在MySQL Server层得到较多元组,然后才过滤,最终得到的是少量的、符合条件的元组。
图二:使用ICP技术(过程使用数字符号标示,如①②③等)

过程解释:
①:MySQL Server发出读取数据的命令,过程同图一。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足已经下推的条件的(经过查找,红色的满足)从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。
此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要在③这个阶段依据下推的条件进行进行判断,不满足条件的,不去读取表中的数据,直接在索引树上进行下一个索引项的判断,直到有满足条件的,才进行步骤④,这样,较没有ICP的方式,IO量减少。
⑥:从存储引擎返回查找到的少量元组给MySQL Server,MySQL Server在⑦得到少量的元组。因此比较图一无ICP的方式,返回给MySQL Server层的即是少量的、符合条件的元组。
另外,图中的部件层次关系,不再进行解释。
示例
假设有一张people表,包含字段name、address、first_name
索引为(name,address,first_name)
然后我们执行下面的查询
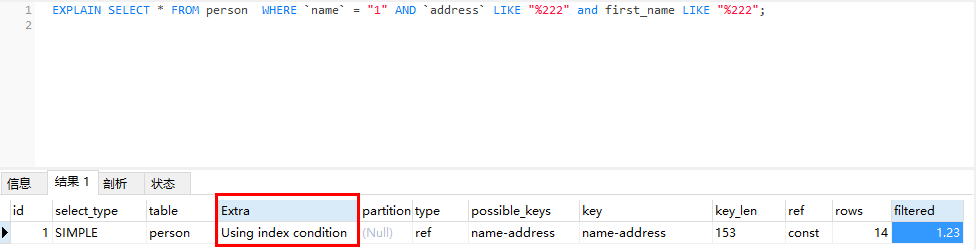
SELECT * FROM person WHERE `name` = "1" AND `address` LIKE "%222" and first_name LIKE "%222";如果不使用索引条件下推优化的话,MySQL只能根据索引查询出name=1的所有行,然后再依次比较是否符合全部条件。
当使用了索引条件下推优化技术后,可以通过索引中存储的数据判断当前索引对应的数据是否符合条件,只有符合条件的数据才将整行数据查询出来。查看执行计划时发现extra一栏中有Using index condition信息,说明使用了索引下推。
配置
索引下推优化是默认开启的。可以通过下面的脚本控制开关
SET optimizer_switch = 'index_condition_pushdown=off';
SET optimizer_switch = 'index_condition_pushdown=on';思考
索引下推优化技术其实就是充分利用了索引中的数据,尽量在查询出整行数据之前过滤掉无效的数据。
由于需要存储引擎将索引中的数据与条件进行判断,所以这个技术是基于存储引擎的,只有特定引擎可以使用。并且判断条件需要是在存储引擎这个层面可以进行的操作才可以,比如调用存储过程的条件就不可以,因为存储引擎没有调用存储过程的能力。