(1)使用Docker-compose实现Tomcat+Nginx负载均衡
项目结构
.
├── docker-compose.yml
├── nginx
│ └── default.conf
├── tomcat00
│ └── index.html
├── tomcat01
│ └── index.html
└── tomcat02
└── index.html
nginx配置文件
default.conf
upstream tomcats {
server tomcat00:8080;
server tomcat01:8080;
server tomcat02:8080;
}
server {
listen 2420;
server_name localhost;
location / {
proxy_pass http://tomcats;
}
}
docker-compose.yml
version: "3"
services:
nginx:
image: nginx
container_name: nginx0
ports:
- 80:2420
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat00
- tomcat01
- tomcat02
tomcat00:
image: tomcat
container_name: tomcat00
volumes:
- ./tomcat00:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat01:
image: tomcat
container_name: tomcat01
volumes:
- ./tomcat01:/usr/local/tomcat/webapps/ROOT
tomcat02:
image: tomcat
container_name: tomcat02
volumes:
- ./tomcat02:/usr/local/tomcat/webapps/ROOT
负载均衡测试
1.轮询策略(默认)
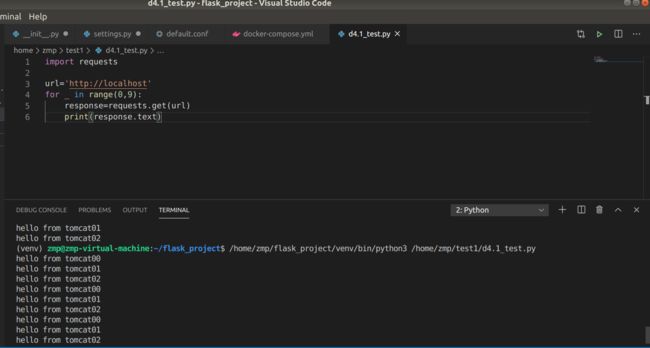
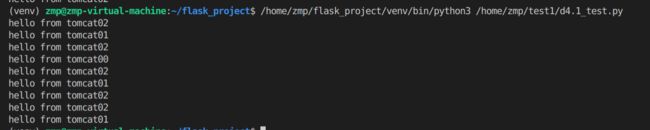
2.加权轮询

测试
(2)使用Docker-compose部署javaweb运行环境
项目结构
.
├── default.conf
├── docker-compose.yml
├── docker-entrypoint.sh
├── Dockerfile
├── grogshop.sql
└── webapps
├── docs
├── examples
├── host-manager
├── manager
├── ROOT
├── ssmgrogshop_war
└── ssmgrogshop_war.war
default.conf
upstream tomcats { #权重策略
server tomcat0:8080 weight=4;
server tomcat1:8080 weight=1;
server tomcat2:8080 weight=1;
}
server {
listen 2020; #nginx的监听端口
server_name localhost;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
proxy_pass http://tomcats; #访问nginx之后,会轮询访问代理的tomcat服务器
}
}
docker-compode.yml
#所有容器都处于同一子网下;静态ip可自由分配
version: "3"
services:
tomcat0:
image: tomcat
container_name: tomcat0
volumes:
- ./webapps:/usr/local/tomcat/webapps
networks: #网络设置静态IP,保证在同一子网下可随意分配
webnet:
ipv4_address: 15.22.0.15
tomcat1:
image: tomcat
container_name: tomcat1
volumes:
- ./webapps:/usr/local/tomcat/webapps
networks: #网络设置静态IP,
webnet:
ipv4_address: 15.22.0.16
tomcat2:
image: tomcat
container_name: tomcat2
volumes:
- ./webapps:/usr/local/tomcat/webapps
networks: #网络设置静态IP,
webnet:
ipv4_address: 15.22.0.17
mysql:
build: .
image: mysql
container_name: mysql
ports:
- "3309:3306"
command: [ #设置编码模式
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_unicode_ci'
]
environment:
MYSQL_ROOT_PASSWORD: "123456" #root密码
networks:
webnet:
ipv4_address: 15.22.0.6
nginx:
image: nginx
container_name: mynginx
ports:
- 80:2020
volumes:
- ./default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat0
- tomcat1
- tomcat2
tty: true
stdin_open: true
networks:
webnet:
ipv4_address: 15.22.0.7
networks: #网络设置
webnet:
driver: bridge #网桥模式
ipam:
config:
-
subnet: 15.22.0.0/24 #子网
JavaWeb项目
参考项目
验证
- 访问localhost/ssmgrogshop_war/
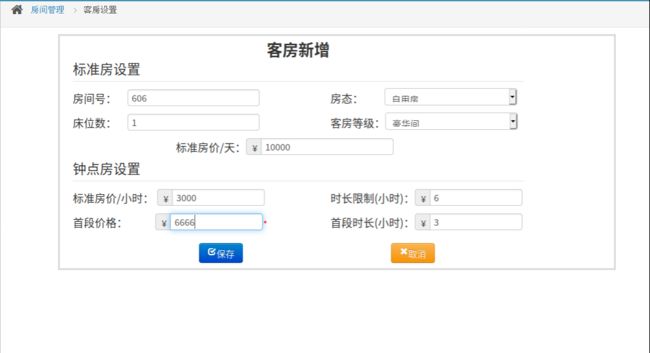
- 增加房间
- 操作后页面和后端数据库情况
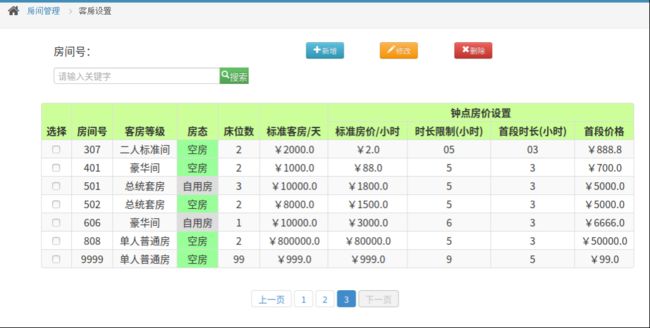
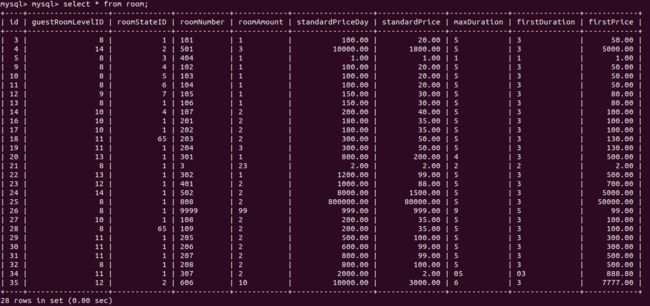
- 修改房间信息
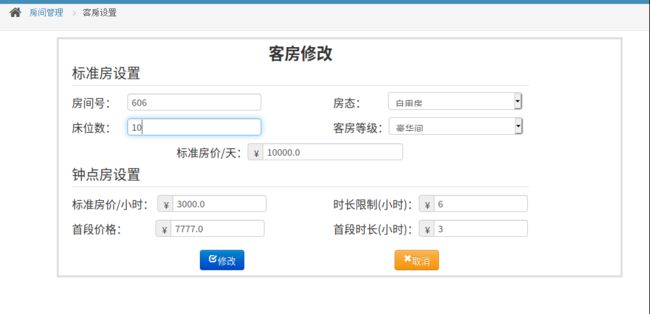
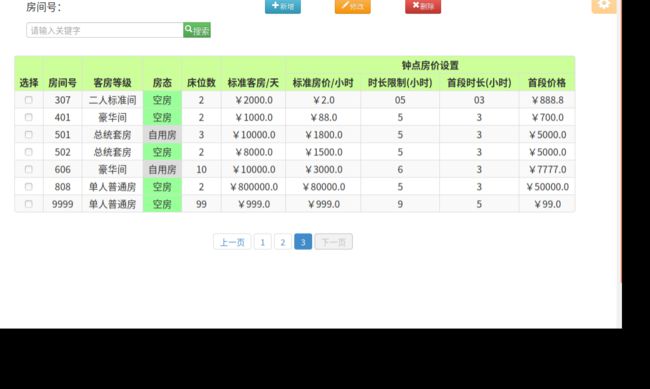
- 操作后页面和后端数据库情况
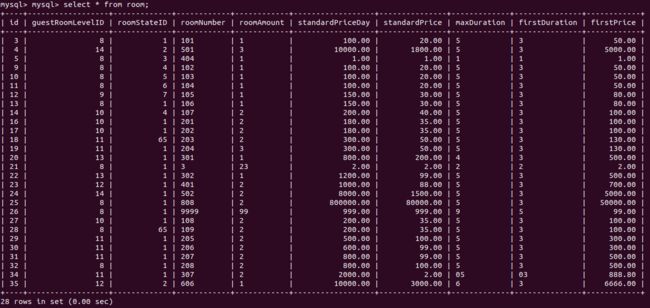
- 删除新建的房间
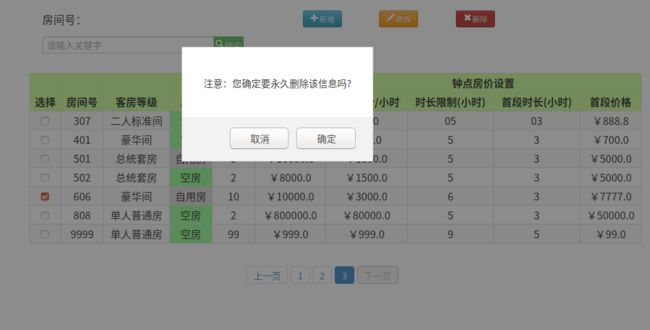
- 操作后页面

(3)使用Docker搭建大数据集群环境
项目结构:
├── Dockerfile
├── build
│ └── hadoop-3.2.1.tar.gz
├── config
│ ├── hadoop-env.sh
│ ├── hdfs-site.xml
│ ├── mapred-site.xml
│ └── yarn-site.xml
└── sources.list
dockerfile:
FROM ubuntu
#基础镜像
环境搭建:
创建容器:
使用sudo docker pull ubuntu拉取ubuntu镜像
使用如下命令创建并进入ubuntu容器
docker build -t ubuntu .
docker run -it --name ubuntu ubuntu
ubuntu环境的初始化:
apt-get update # 更新系统源
apt-get install vim # 修改配置文件
apt-get install ssh # 安装sshd
/etc/init.d/ssh start # 运行脚本开启sshd服务器
安装好sshd之后,我们需要配置ssh无密码连接本地sshd服务,输入如下命令,即可无密码访问本地sshd服务:
cd ~/.ssh
sh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
为容器安装SDK:
apt install openjdk-8-jdk
配置环境变量:
vim ~/.bashrc打开配置文件,在最后添加:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc 使~/.bashrc生效
保存配置好的镜像文件
docker ps # 查看当前容器id
docker commit # 存为镜像
安装Hadoop:
docker run -it -v /home/hadoop/build:/root/build --name ubuntu-d4.3 ubuntu/d4.3开启保存的那份镜像ubuntu/d4.3
下载完成后,用cp命令将文件复制入共享文件夹/home/hadoop/build:
sudo cp /home/ubuntu/Desktop/hadoop-3.2.1.tar.gz /home/hadoop/build
此时,能在ubuntu镜像的/root/build下看见文件
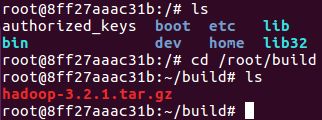
解压文件tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local
./bin/hadoop version # 验证安装

配置Hadoop集群
先进入配置文件存放目录:
cd /usr/local/hadoop-3.2.1/etc/hadoop
修改环境变量:
vim hadoop-env.sh
加入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
修改core-site.xml:
vim core-site.xml
添加:
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://master:9000
修改hdfs-site.xml:
vim hdfs-site.xml
添加:
dfs.namenode.name.dir
file:/usr/local/hadoop/namenode_dir
dfs.datanode.data.dir
file:/usr/local/hadoop/datanode_dir
dfs.replication
3
修改mapred-site.xml:
vim mapred-site.xml
添加:
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1
mapreduce.map.env
HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1
mapreduce.reduce.env
HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1
修改yarn-site.xml:
vim yarn-site.xml
添加:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
存档:
sudo docker commit 8ff ubuntu/hadoopinstalled
![]()
运行Hadoop集群
在三个终端上开启三个容器运行ubuntu/hadoopinstalled镜像,分别表示Hadoop集群中的master,slave01和slave02;
# 第一个终端
sudo docker run -it -h master --name master ubuntu/hadoopinstalled
# 第二个终端
sudo docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled
# 第三个终端
sudo docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled
配置master,slave01和slave02的地址信息
分别打开/etc/hosts可以查看本机的ip和主机名信息,最后得到三个ip和主机地址信息如下:
172.17.0.2 master
172.17.0.3 slave01
172.17.0.4 slave02
(将上述三个地址信息分别复制到master,slave01和slave02的/etc/hosts)
测试ssh,检测master是否可以连上slave01和slave02
ssh slave01
ssh slave02
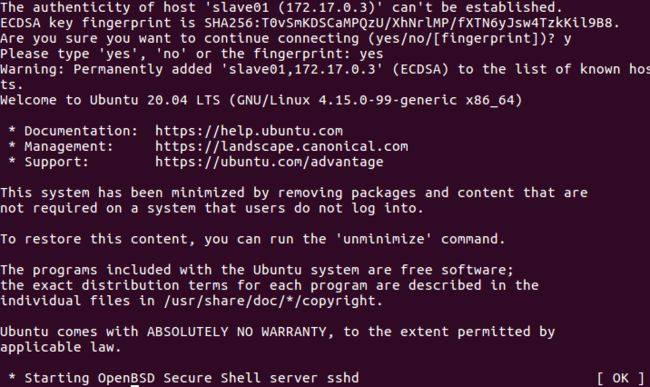
修改slaves:
vim /usr/local/hadoop-3.2.1/etc/hadoop/workers
将localhost替换成两个slave的主机名:
slave01
slave02
配置完成,启动集群
master终端上,首先进入/usr/local/hadoop-3.2.1
cd /usr/local/hadoop-3.2.1
bin/hdfs namenode -format # 格式化文件系统
sbin/start-dfs.sh # 开启NameNode和DataNode服务
用jsp命令测试结果:
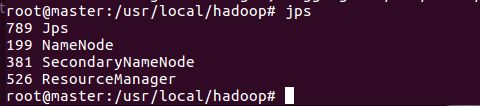
运行Hadoop实例程序grep:
在hdfs上创建一个目录:
./bin/hdfs dfs -mkdir -p /user/hadoop/input
将/usr/local/hadoop/etc/hadoop/目录下的所有文件拷贝到hdfs上的目录:
bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
执行实例程序:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /user/hadoop/input output 'dfs[a-z.]+'
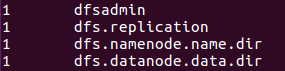
可以在hdfs上的output目录下查看到运行结果:
./bin/hdfs dfs -cat output/*
结果:
实验用时&心得
查阅资料6小时,程序部署2小时。
本次实验涉及了很多没学过的知识,因此用了大量的时间查阅资料和相应的学习。