详细Ubuntu系统下搭建Hadoop完全分布式
1.Hadoop的运行环境介绍
hadoop主要有三种运行模式:单机模式、伪分布模式、完全分布模式。
其中在单机模式下所有3个XML文件均为空,当配置文件为空时,Hadoop会完全运行在本地,因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
在伪分布式模式下是指在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上,即Jobtracker、Tasktracker、Namenode、Datanode、Secondarynamenode进程都运行在同一台主机上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
完全分布式模式是将hadoop运行在了一个真正的集群上,该集群内含有一个主节点master,及至少两个的从节点slave;其中主节点上主要运行Namenode、Jobtracker、Secondarynamenode进程,从节点主要运行Datanode、Tasketracker进程。这种模式下可以真正实现hadoop的分布式处理,有主节点对从节点的任务分配调度以及HDFS在主机间的输入输出。
2.集群介绍
之前我们在实验课上已经搭建好了单机模式以及伪分布式,已在虚拟操作系统Ubuntu中安装了SSH(安装外壳协议),在搭建完全分布式模式时需要通过SSH来启动Slave列表中各台机器的守护进程。
环境说明
虚拟机:VMware Workstation Pro
操作系统:Ubuntu14.04
hadoop版本:hadoop1.0.4
节点信息:
192.168.191.91master
192.168.191.101slave1
192.168.191.111slave2
192.168.191.121 slave3
jdk版本:jdk-7u80-linux-x64
hive版本:hive-0.9.0-bin
mysql版本:mysql-5.5.45-linux2.6-x86_64.tar
2.实现各主机间的通信
2.1VWare下的网络连接模式
2.1.1 本地模式(host-only)
在host-only模式中,所有的虚拟系统是可以相互通信的,但虚拟系统和真实的网络是被隔离开的。可以利用Windows 里自带的Internet连接共享(实际上是一个简单的路由NAT)来让虚拟机通过主机真实的网卡进行外网的访问。虚拟系统的TCP/IP配置信息(如IP地址、网关地址、DNS服务器等),都是由VMnet1(host-only)虚拟网络的DHCP服务器来动态分配的。如果想利用VMware创建一个与网内其他机器相隔离的虚拟系统,进行某些特殊的网络调试工作,可以选择host-only模式。
2.1.2 NAT模式(网络地址转换模式)
NAT模式下就是让虚拟系统借助NAT(网络地址转换)功能,通过宿主机器所在的网络来访问公网。也就是说,使用NAT模式可以实现在虚拟系统里访问互联网。NAT模式下的虚拟系统的TCP/IP配置信息是由VMnet8(NAT)虚拟网络的DHCP服务器提供的,无法进行手工修改,因此虚拟系统也就无法和本局域网中的其他真实主机进行通讯。采用NAT模式最大的优势是虚拟系统接入互联网非常简单,你不需要进行任何其他的配置,只需要宿主机器能访问互联网即可。如果你想利用VMware安装一个新的虚拟系统,在虚拟系统中不用进行任何手工配置就能直接访问互联网,就可直接采用NAT模式。
2.1.3 桥接模式(bridge)
在桥接模式下,VMware虚拟出来的操作系统就像是局域网中的一独立的主机,它可以访问网内任何一台机器。不过你需要多于一个的IP地址,并且需要手工为虚拟系统配置IP地址、子网掩码,而且还要和宿主机器处于同一网段,这样虚拟系统才能和宿主机器进行通信。该模式下可以利用VMware在局域网内新建一个虚拟服务器,将虚拟机模拟接入主机所在的局域网,便可为局域网用户提供网络服务。
2.2桥接模式实现主机间通信
通过了解Ubuntu下的三种网络连接模式,为实现不同的虚拟主机间相互通信,我们不可采取NAT模式,只能选择桥接模式。因为在NAT模式下即使为各个虚拟主机设置静态ip使其同在一个局域网内,也只能实现其访问互联网,而不能使本局域网中的主机相互通信;而在桥接模式下,我们可以让一台计算机开启共享wifi,其他主机连接到该路由器下,使各宿主机处于同一个局域网内,再为本机的虚拟主机设置静态ip,ip地址要与宿主机处于同一网段,子网掩码、网关要与宿主机的一致,至此各虚拟主机就处于同一局域网内了。以下是具体操作步骤:
(1)更改Vmware网络连接模式
在此之前还需要在宿主机的网络和共享中心中查看此时所用网络的网卡,之前也提到了各宿主机连接到同一个路由器上,即此时网卡为本机的无线网卡(此处的宿主机作为路由器,也就选择开启共享wifi的对应网卡)
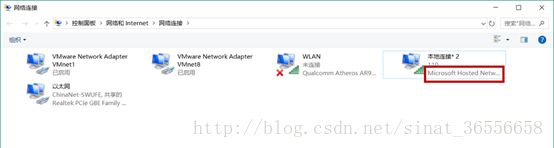
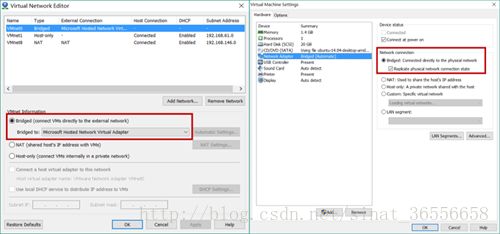
打开虚拟机编辑>虚拟网络编辑器>更改设置,将网络连接方式更改为桥接模式,网卡选取之前查看到的部分;再更改虚拟机>设置>网络适配器,更改网络连接至此打开虚拟机。
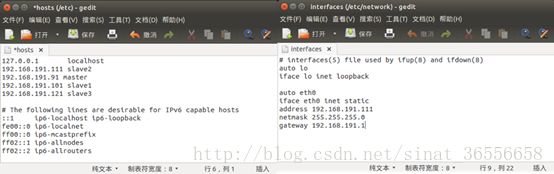
(2)设置静态ip
开始设置虚拟主机的静态ip,主要需要配置这样几个文件(注意需要使用之前就创建的hadoop用户登陆)/etc/hostname用于更改虚拟主机的主机名,主节点为master,从节点分别改为slave1,slave2,slave3;/etc/hosts用于添加该局域网内的集群中其他虚拟主机ip;/etc/network/interfaces用于设置静态ip,默认网关为192.168.191.1,子网掩码为255.255.255.0;/etc/resolv.cnf用于更改DNS 10.200.255.1;最后需要重启网络,在终端输入命令sudo /etc/init.d/networking restart.
由于虚拟机中一般由NetworkManager接管网路,当我们配置了interfaces文件和resolv.cnf文件时,再重启网络发现更改会还原,文档又被重写了;此时就是设置静态ip和NetworkManager两者冲突了,导致网络连接失败。此时需要将NetworkManager删除掉,直接由静态ip决定。
卸载NetworkManager需执行命令为:
sudo apt-getpurge network-manager
sudo apt-getpurge network-manager-gnome
若命令执行完毕后,桌面右上角没有NetworkManager标志后就表示卸载成功。
另外,更改DNS后每次重启都会被重写,若想要永久更改DNS地址需要编辑文件/etc/resolvconf/resolv.conf.d/base,添加nameserver DNS地址。
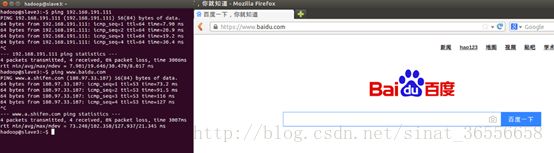
至此,集群已搭建成功,集群内的虚拟主机可以和宿主机通信,也能和集群内的其他虚拟主机通信,还能访问外网
3.节点间ssh免密登陆
在之前搭建单机模式和伪分布式时,我们已经安装了ssh,并且为虚拟本机生成了一对密钥,实现了虚拟本机的免密登陆。这里,我们要实现的是使各节点间能够免密登陆,免密通信。具体做法是将各个slave从节点给主节点发送其公钥,master将所有从节点的公钥汇总到本机文件~/.ssh/authorized_keys中,最后再由master将该文件分发给各个从节点,进而实现各节点间免密登陆。
slave端在终端执行命令ssh-copy-id -i ~/.ssh/id_rsa.pub master,表示给master发送公钥,master端在终端执行命令scp ~/.ssh/authorized_keyshadoop@slave1: ~/.ssh/authorized_keys,表示将由slave1发送过来的公钥保存到master虚拟本机的authorized_keys中。
注意在登陆其他节点时,要保证各节点都是用hadoop用户登陆虚拟机。通过命令ssh master登陆master节点,在第一次登陆时需要输入节点的登陆密码,当第二次登陆时能直接登陆进去,表示设置ssh免密登陆成功。
4.安装新版SUN JDK
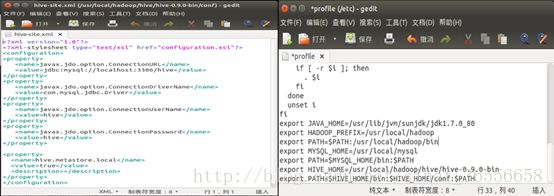
为实现更广泛的功能,我们选择重新安装新版的sun jdk;在官网下载对应版本jdk-7u80-linux-x64.tar.gz后,解压到目录/usr/lib/jvm下,更改jdk后还需进行对应的环境变量设置,编辑文件~/.bashrc或etc/profile,更新JAVA_HOME的路径;同时还应在hadoop的环境变量配置中更改对应的JAVA_HOME,以免之后会出错,即编辑该目录下文件中的环境变量/usr/local/hadoop/conf/hadoop-env.cnf
至此,虽已安装了新版的jdk,但是Ubuntu系统默认的jdk还是其自带的openjdk,需要进一步设置,在终端执行下列命令将我们安装的jdk加入java选择单:
sudo update-alternatives --install /usr/bin/java java/usr/lib/jvm/jdk1.7.0_25/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac/usr/lib/jvm/jdk1.7.0_25/bin/javac 300
再执行命令,选择系统默认的jdk,最后再查看java版本,确定sunjdk是否安装成功
sudo update-alternatives --config java
sudo update-alternatives --config javac

5.hadoop配置
(1)配置master及slave
在每个节点中都要配置conf下的masters及slaves文件为对应分配好的hostname
(2)配置*.xml
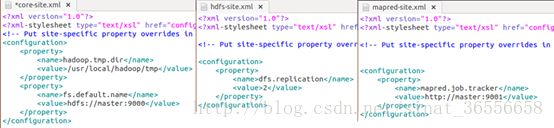
配置core-site.xml文件时更改了两项,默认dfs.name.dir、dfs.data.dir和mapred.system.dir均放在hadoop.tmp.dir下,这些文件夹存有NameNode和DataNode的数据和各种系统资料,而hadoop.tmp.dir却默认放在/tmp/hadoop-${user.name},这意味着重启之后这些东西很可能全都没了。在正式的集群中,这些子文件夹最好放在不依赖于hadoop.tmp.dir的地方。这里为了方便,我们直接先修改hadoop.tmp.dir来改变其他子文件夹,将它放在hadoop安装目录的tmp文件夹,并且显式指明默认的Namenode位置fs.default.name为master的9000端口。
配置hdfs-site.xml,这里修改dfs.replication即备份多少副本,1的话就是不备份。这个值不能超过Datanode的数目。
配置mapred-site.xml,这里指明所有的node在找jobtracker时都要去找master的9001端口。
6.1hive介绍
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。hive将元数据存储在数据库中,如mysql、derby。hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等,但是hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织hive中的表;hive 的数据存储在HDFS中,大部分的查询由MapReduce完成。因此为方便存储、查询大量的数据,我们采用将hive和mysql连接起来。
5.2安装mysql
在搭建hadoop集群时,已经实现每一个虚拟主机都可以访问互联网(作为路由器的主机除外),此种情况可以为在线安装,在Ubuntu终端执行命令sudo apt-get install mysql-server直接获取mysql安装包;
另外还有一种离线安装,即到官网下载linux系统下的对应版本,再解压到指定目录下,这里我们指定目录为/usr/local/mysql,再通过命令sudo scripts/mysql_install_db --user=root安装mysql,若有报错则还需下载安装一个依赖包libaio1_0.3.110-2_amd64.deb然后执行命令dpkg–i libaio1_0.3.109-2ubuntu1_amd64.deb,之后在mysql目录下启动mysql sudo./support-files/mysql.server start。
启动mysql后,用root用户登陆mysql,创建一个新用户hive并授权
mysql>grant all on hive.* tohive@'%' identified by 'hive';
mysql>flush privileges;
6.3安装hive
在官网下载hive-0.9.0-bin.tar.gz并解压到指定路径/usr/local/hive中,同样的需要更改环境变量。接着需要配置文件,复制hive-env.sh.template,修改hive-env.sh文件添加HIVE_HOME,JAVA_HOME,HADOOP_HOME,以及文件hive-site.xml。文件配置完成后便可启动hive服务了。
为连接hive和mysql还需下载一个JDBC驱动包,这里我们选择了mysql-connector-java-5.1.44.tar.gz,将该文件解压到hive目录下的lib中。
6.4验证配置
各节点都安装完成hive及mysql,启动hadoop服务,只需在master节点上执行启动服务命令先执行初始化命令hadoop namenode-format ,再分别执行命令start-dfs.sh,start-mapred.sh,服务启动成功后可以在master节点jps看到Jobtracker、Namenode、Secondarynamenode进程,在各slave节点jps看到Datanode、Tasktracker进程。
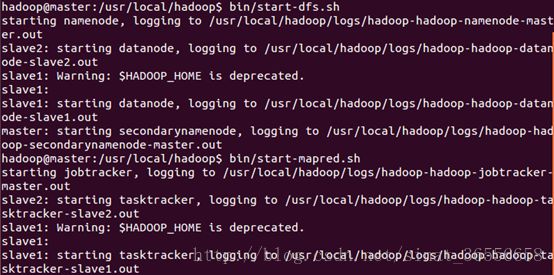

之后运行hive,创建一个表
hive>CREATETABLE xp(idINT,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
用hive用户登陆mysql,执行命令showtables,可以看到刚由hive创建的表xp。至此hadoop的完全分布式已经完全搭建成功,并且实现了各节点的hive、mysql功能。