python 爬取海量网易云评论并写入数据库
本人是一个网易云音乐的重度患者,最近闲来无事,就想起来写一个爬虫爬一下网易云音乐上都有哪些有趣的评论,于此记录一下过程。
整体思路
可能是我的脑回路那啥,作为一个新手,咱一上来,是直接尝试爬取评论。随便挑了一首歌,进行尝试,看是否能够拿到评论数据。虽然过程有些曲折,但还是让咱拿到了评论。于是开始正儿八经进行分析,应该如何才能拿到大量的评论数据。经过咱的观察。我发现,每一首歌都有一个 id ,如果能够获取到这首歌的 id ,就可以爬取到这首歌的评论数据。那么,如何获取歌曲的 id 呢?问的好,经过我的尝试,我发现,歌单中包含了歌曲的 id ,而且歌单也是利用 id 进行管理的。简单理一下,思路就出来了,我们可以先爬取一定量的歌单,取出歌单的 id ;然后通过歌单的 id 爬取歌单中包含的歌曲的 id ;最后,利用得到的歌曲 id 爬取相应的评论数据。
获取歌单的id

上图中的箭头所指就是我们需要的,歌单的 id 。但很多朋友经过分析,会发现直接用这个 url 请求的页面,其实是不包含 id 。这是为什么呢?其实这里采用了 js 异步加载的技术,一是为了降低网络带宽,减少响应时间,还有就是简单的反爬。大底就是,将第一次响应的页面框架保留,后面响应的时候,只是通过 js 将数据插入到框架中,而不是将整个框架重传(个人理解,若有偏差欢迎大家指正)。换句话来说,直接 用 url 请求到的其实只是一个页面的框架,而我们需要的数据其实是在其他的文件中。那么这个文件又在哪呢?别着急,咱们来找找。
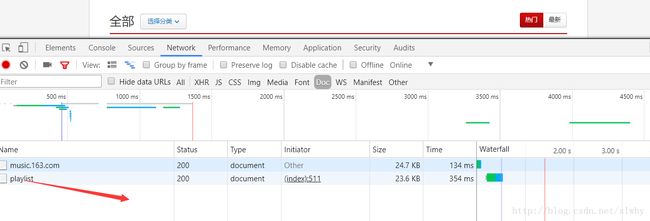
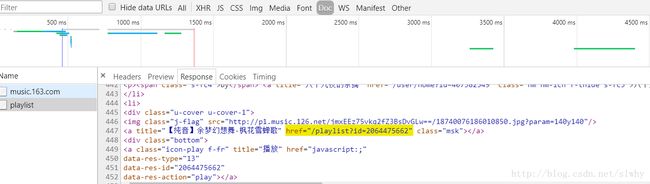
经过多次尝试,咱终于在一个名为 playlist 的文件中找到了需要的 id (对于这个查找,我也没有什么有效的方法,最多增加一些筛选条件,很多都是经验之谈)找到了这个文件,拿到 相应的 url ,接下来就是分析,提取数据了咱就不多啰嗦了。不过要稍微注意一下的是,歌单是分页存放的,要通过修改 offset 的值进行翻页的操作(咱弄的时候,每 35 为一页)。
获取歌单中歌曲的 id
通过之前拿到手的歌单的 id ,咱就不难访问对应的的歌单。现在我们要做的就是,取出每张歌单里面包含的歌曲所对应的 id 。通过分析,大家会发现,歌曲 id 的获取和 歌单 id 类似,数据都是一个以 playlist 开头的文件中。
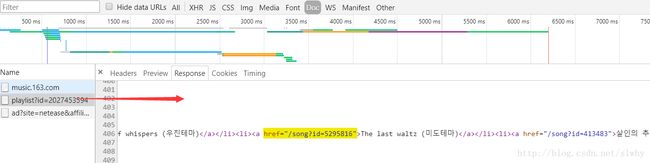
不过貌似网易云对请求头做了简单的判别,如果咱用 python 默认的请求头进行访问,是拿不到数据的,要对 UA 进行修改。
获取每首歌的评论
通过之前的努力,咱们已经获取到了大量歌曲所对应的 id ,于是开始磨刀霍霍,直奔评论数据而去。但很快大家就会发现,评论不是那么好拿的。主要问题有两个,一是xhr技术,你得分析出评论所在文件;二是加密。第一个还不是很麻烦,添加一个筛选条件,大家很快便能找到,评论所在的文件。
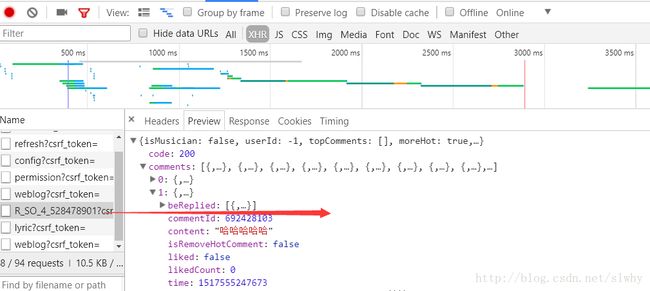
但第二个则比较糟心了,大家来看一下这个文件的请求头。

这个请求头有一个 from data ,而这里面又有两个字段的参数,特别是这两个参数还是一堆又臭又长的乱七八糟的不知道啥玩意的字符。这个时候,咱一般会猜,这应该是采用了某种加密吧,而且还是在前端进行的加密。于是乎,咱找到这个相应的 js 文件,将代码拷贝出来,格式化好,看一下。
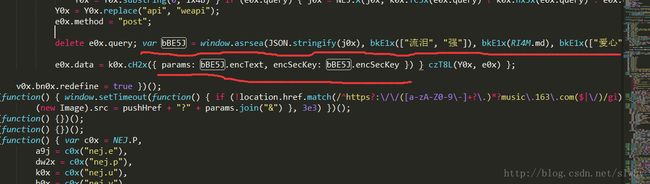

虽然大家不一定都懂 js ,但观察其逻辑大概能发现,其采用了 AES,rsa 加密算法,对数据进行了两次 AES 加密,第一次加密的密钥已知,第二次加密的密钥是随机产生的,所以又需要将第二次的密钥通过 rsa 加密传输给服务器。对于这个加密的过程,本人分析的不是很透彻,不过我找到了一篇写的不错的博客,推荐给大家:网易云音乐Web API 加密算法分析
这里给出我的方法,咱对 js 完全不懂,要想用 python 将其改写出来,完全不现实。所以咱给 ta 来了个移花接木。利用 Fiddle 在线调试 js(如何在线调试 js :Fiddle 提交本地 js 文件进行调试) ,将 AES 加密的参数打印出来,咱用这些参数去实现加密的最后一部分,两重 AES 加密和 rsa 加密。这个是不难实现的, python 都提供了相应的第三方模块可供调用。具体实现可参考代码。
将数据写入数据库
数据已经获取到了,那么该如何保存呢?我的选择是将其写入 MySQL 数据库中。对于数据库咱也是刚刚上手,不过 python 操作 MySQL 还是挺简单的。安装 MySQL-python 模块
db = MySQLdb.connect(host='localhost', user=str(user), passwd=str(passwd), db=str(db), port=3306, charset='utf8')
db.cur.execute('insert into ' + table + key + ' values (%s)' % value)
db.con.commit()这里只是做一个简单的示范,先连接数据库,而后就可以通过 execute 执行 sql 了,不过需要注意一下, execute 的参数是作为字符串传入的,而且对数据库修改后需要用 commit 提交。咱只需要不停的将爬取到的数据 insert 进事先创建好的 table 中。
代码见 GitHub (代码有点乱,大家将就着看吧╮(╯▽╰)╭)
https://github.com/Slwhy/wangyiyun.git