python批量爬取网页图片的初步实现
最近本人正在学习python网络爬虫,尝试实现爬取网页图片,通过对网上一些相关博客的学习,目前初步实现,分享一下实现代码。
爬取图片的目标网页是https://findicons.com/pack/2787/beautiful_flat_icons:
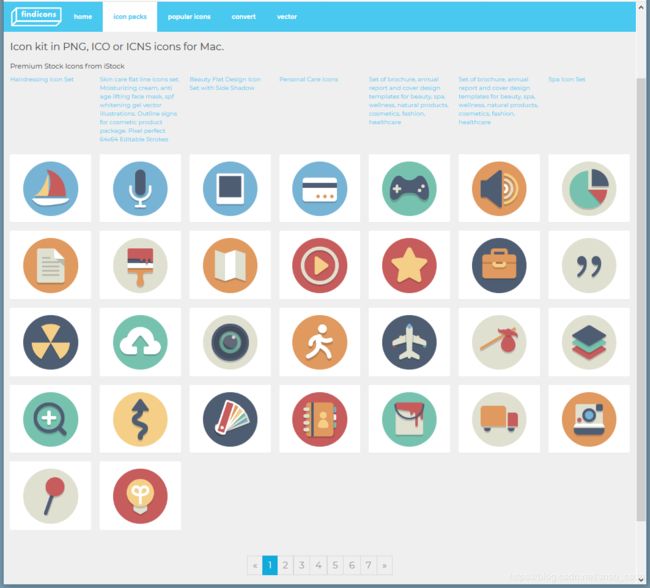
1. 获取html
import requests
import urllib.request
import re
html = requests.get('https://findicons.com/pack/2787/beautiful_flat_icons')
encoding = html.apparent_encoding #获取该页面的字符集编码类型
html.encoding = encoding #使用该编码类型来对页面编码
text = html.text
2. 从html内容中提取图片链接
text_splited = re.split(r'\s+',text) #将html内容按空格分割为一个列表
target = []
target_index = []
for i in text_splited:
if(re.match(r'src',i)):
if(re.match(r'.*?png',i)):
target.append(i)
target_index.append(text_splited.index(i))
在这部分代码中,我们将网页的html内容按空格进行分割并保存在列表text_splited中。
 ▲左图:网页的html文本;右图:html文本被分割为一个列表,包含4853个元素
▲左图:网页的html文本;右图:html文本被分割为一个列表,包含4853个元素
随后,对text_splited列表中的每一个元素,利用正则表达式,通过两个if判断,提取得到图片链接。代码中target_index不是必须的,加上它是想观察所获得的图片链接在text_splited列表中的位置,加深理解。
 ▲一共获得了32个图片链接,观察第一个图片链接,target_index显示它来自于text_splited的第459个元素。
▲一共获得了32个图片链接,观察第一个图片链接,target_index显示它来自于text_splited的第459个元素。
3. 保存图片到本地
count = 1
for i in target:
img_url =re.search(r'src="(.*?)"',i)
img_url = img_url.group(1) #获得准确的图片url
print(img_url)
web = urllib.request.urlopen(img_url)
web_data = web.read()
#open函数打开(创建)一个文件,其中模式'wb'表示以二进制格式打开一个文件只用于写入:
#如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除;如果该文件不存在,则创建新文件。
save_image = open('saved image/'+str(count)+'.png','wb')
save_image.write(web_data)
save_image.close()
count += 1
运行时出现错误:
ValueError: unknown url type: '/static/images/flecha.png'
观察发现,所抓取的第一个png图片链接其实是网页上的按钮图标,并不是我们想要的,因此出错。(第二个图片链接也是相似的情况)。

 为此,我们需要在第2步提取图片链接时将这两个链接剔除。
为此,我们需要在第2步提取图片链接时将这两个链接剔除。
对比这两个链接与其他链接,发现这两个链接不包含‘com’字符串,因此可以以此作为判断标准将将其剔除,在第2步代码的两个if中再嵌套一个if判断语句:
for i in text_splited:
if(re.match(r'src',i)):
if(re.match(r'.*?png',i)):
if(re.match(r'.*?com',i)): #新增的判断
增加后,获得的图片链接为30个,不再包含按钮图片:

运行后,成功将30个图片保存到本地文件夹中。

4. 完整代码
import requests
import urllib.request
from bs4 import BeautifulSoup as bs
import re
html = requests.get('https://findicons.com/pack/2787/beautiful_flat_icons')
encoding = html.apparent_encoding #获取该页面的字符集编码类型
html.encoding = encoding #使用该编码类型来对页面编码
text = html.text
text_splited = re.split(r'\s+',text)
target = []
target_index = []
for i in text_splited:
if(re.match(r'src',i)):
if(re.match(r'.*?png',i)):
if(re.match(r'.*?com',i)):
target.append(i)
target_index.append(text_splited.index(i))
count = 1
for i in target:
img_url =re.search(r'src="(.*?)"',i)
img_url = img_url.group(1)
print(img_url)
web = urllib.request.urlopen(img_url)
web_data = web.read()
save_image = open('saved image/'+str(count)+'.png','wb')
save_image.write(web_data)
save_image.close()
count += 1
5. 后记
目前,我对利用python爬取某网页上的图片的理解是:
- 获取该网页的html。
- 将该网页的html进行分割,通过一些关键字符串(‘href’、‘src’、‘png’)来寻找、筛选和提取所想要的png、jpg等格式的图片。
- 将该图片保存到本地。
下一步,我会尝试采用这个方法对其他网页的图片内容进行爬取,加深理解。
在练习过程中,以下博客和网页的内容提供了有益的帮助:
https://www.cnblogs.com/itlqs/p/5767054.html
https://www.runoob.com/python/python-func-open.html