自定义损失函数
In statistics, the Huber loss is a loss function used in robust regression, that is less sensitive to outliers in data than the squared error loss. A variant for classification is also sometimes used.
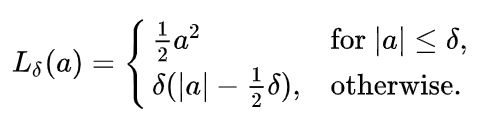
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < 1
squared_loss = tf.square(error) / 2
linear_loss = tf.abs(error) - 0.5
return tf.where(is_small_error, squared_loss, linear_loss)
注意,自定义损失函数的返回值是一个向量而不是损失平均值,每个元素对应一个实例。这样的好处是Keras可以通过class_weight或sample_weight调整权重。
huber_fn(y_valid, y_pred)
导入损失函数
model = keras.models.load_model("my_model_with_a_custom_loss.h5",
custom_objects={"huber_fn": huber_fn})
带参数的自定义损失函数
def create_huber(threshold=1.0):
def huber_fn(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) < threshold
squared_loss = tf.square(error) / 2
linear_loss = threshold * tf.abs(error) - threshold**2 / 2
return tf.where(is_small_error, squared_loss, linear_loss)
return huber_fn
model.compile(loss=create_huber(2.0), optimizer="nadam", metrics=["mae"])
导入模型的时候注意:
model = keras.models.load_model("my_model_with_a_custom_loss_threshold_2.h5",
custom_objects={"huber_fn": create_huber(2.0)})
导入的是带有参数的create_huber(2.0),而不是create_huber。如果想要保留参数设置,必须自定义