深度学习中的注意力机制
深度学习中的注意力机制
文章目录
- 深度学习中的注意力机制
- @[toc]
- 前言
- Sequence to Sequence
- Sequence to Sequence 的各种形式
- Attention Mechanism
- Attention 于机器翻译
- Self-Attention
- 文字识别中的 Attention
- 推荐系统中的 Attention
- Attention is all you need
- Attention 的用途与缺陷
- 最后一点话
- 参考文献
文章目录
- 深度学习中的注意力机制
- @[toc]
- 前言
- Sequence to Sequence
- Sequence to Sequence 的各种形式
- Attention Mechanism
- Attention 于机器翻译
- Self-Attention
- 文字识别中的 Attention
- 推荐系统中的 Attention
- Attention is all you need
- Attention 的用途与缺陷
- 最后一点话
- 参考文献
前言
注意力机制(Attention Mechanism)并非是在最近才被提出的,但它确实在最近几年才变得火热起来,尤其是谷歌2017年发表的那篇《Attention is all you need》,为人们提供了一种用Attention结构完全替代传统CNN和RNN结构的新思路,在那之后似乎有着层出不穷的Attention结构应用。Attention,顾名思义,是由人类观察环境的习惯规律总结而来的,人类在观察环境时,大脑往往只关注某几个特别重要的局部,获取需要的信息,构建出关于环境的某种描述,而Attention Mechanism正是如此,去学习不同局部的重要性,再结合起来。
听起来简单,实现起来其实也简单,我认为对于Attention可以有三种理解。
- 首先,从数学公式上和代码实现上Attention可以理解为加权求和。
- 其次,从形式上Attention可以理解为键值查询。
- 最后,从物理意义上Attention可以理解为相似性度量。
Sequence to Sequence
Attention Mechanism的大量使用源于机器翻译,机器翻译本质上是解决一个Sequence-to-Sequence问题,所以这里从Sequence-to-Sequence讲起,将要说明为什么需要Attention,哪里使用Attention,以及如何使用Attention。
Sequence to Sequence 的各种形式

如上图所示,Sequence-to-Sequence一般有5种形式,区别无非在于输入和输出序列的长度,以及是否同步产出,具体到每一个基本的模块,又能用不同的网络结构实现,包括CNN、RNN,但是万变不离其宗,即它们的实现基本上离不开一个固定的结构:Encoder-Decoder结构。
Encoder-Decoder结构作为Sequence-to-Sequence任务的最佳拍档,常见于各种深度学习任务,从简单的时序预测分类,到GAN里都有它的影子。之所以强调这个结构,就是因为Attention解决了它的“分心问题”。下图给出了一个通用的Encoder-Decoder结构,它可能会给你某种强烈的既视感。Encoder负责从输入序列 X X X中学习某种表达 C C C,然后Decoder参考该表达 C C C生成每一个输出 Y i Y_i Yi。
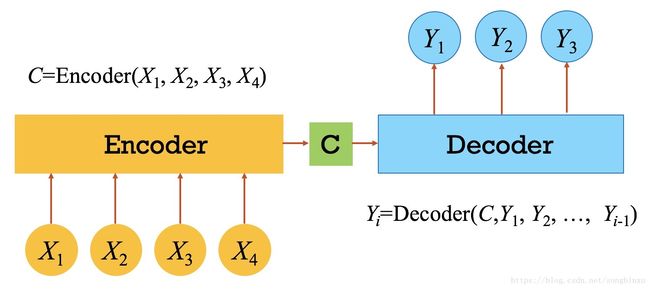
Encoder-Decoder这种原始的做法是不太合理的,因为在生成每一个 Y i Y_i Yi时,Decoder参照的是同一个表征 C C C,它没有抓住重点。这有点像老师让一个小学生写作文,结果他写了一篇流水账一样。在机器翻译中,输出序列的每一个局部,往往只与输入序列的某个或几个局部有关。这里举一个例子,英译中任务:
显然答案是:
在Sequence-to-Sequence里我们要解决的是这样一个问题:
按照Encoder-Decoder的原始做法,我们为三个中文单词分别计算 C C C:
C 比 利 = h ( B i l l y ) + h ( e a t s ) + h ( a ) + h ( b a n a n a ) C 吃 = h ( B i l l y ) + h ( e a t s ) + h ( a ) + h ( b a n a n a ) C 香 蕉 = h ( B i l l y ) + h ( e a t s ) + h ( a ) + h ( b a n a n a ) C_{比利}=h(Billy)+h(eats)+h(a)+h(banana)\\ C_{吃}=h(Billy)+h(eats)+h(a)+h(banana)\\ C_{香蕉}=h(Billy)+h(eats)+h(a)+h(banana) C比利=h(Billy)+h(eats)+h(a)+h(banana)C吃=h(Billy)+h(eats)+h(a)+h(banana)C香蕉=h(Billy)+h(eats)+h(a)+h(banana)
这并不合理,为什么翻译输出“比利”这个词要关注整个原句子呢?只关注或者主要关注“Billy”这个词不是更好吗?同理,输出“吃”这个词时应该更多地关注“eat”,所以下面这种计算 C C C的方式要更加合理一些。
C 比 利 = 0.6 ⋅ h ( B i l l y ) + 0.2 ⋅ h ( e a t s ) + 0.1 ⋅ h ( a n ) + 0.1 ⋅ h ( b a n a n a ) C 吃 = 0.2 ⋅ h ( B i l l y ) + 0.6 ⋅ h ( e a t s ) + 0.1 ⋅ h ( a n ) + 0.1 ⋅ h ( b a n a n a ) C 香 蕉 = 0.1 ⋅ h ( B i l l y ) + 0.1 ⋅ h ( e a t s ) + 0.2 ⋅ h ( a n ) + 0.6 ⋅ h ( b a n a n a ) C_{比利}=0.6\cdot h(Billy)+0.2\cdot h(eats)+0.1\cdot h(an)+0.1\cdot h(banana)\\ C_{吃}=0.2\cdot h(Billy)+0.6\cdot h(eats)+0.1\cdot h(an)+0.1\cdot h(banana)\\ C_{香蕉}=0.1\cdot h(Billy)+0.1\cdot h(eats)+0.2\cdot h(an)+0.6\cdot h(banana) C比利=0.6⋅h(Billy)+0.2⋅h(eats)+0.1⋅h(an)+0.1⋅h(banana)C吃=0.2⋅h(Billy)+0.6⋅h(eats)+0.1⋅h(an)+0.1⋅h(banana)C香蕉=0.1⋅h(Billy)+0.1⋅h(eats)+0.2⋅h(an)+0.6⋅h(banana)
下图是一个简单的Encoder-Decoder,它的Encoder和Decoder都是RNN结构,输入序列表征 C C C有多种计算方法,包括取最后一个时刻的Encoder隐层输出、取所有时刻Encoder隐层输出的均值或加权平均、取最大值等等。它实现了对不同的局部采取不同的权重,然而它对于任意输出都采用同一套权重,本质上没有做出任何改进。

总结一下,我们的要求有两个:
- 对输入序列的不同局部,赋予不同的重要性(权重)
- 对于不同的输出序列局部,给输入局部不一样赋权规划或方案
Attention Mechanism
有了上面的分析以及需求,就能自然而然地引出注意力机制(Attention Mechanism)——它一定程度上解决了上述问题。对于上面给出的疑问(那些权重应该怎么给),Attention给出的答案是,让输出序列决定。如下图所示,这是文献中的结构,我简化了画出来。
假设当前Docoder要输出的是 Y t Y_t Yt,已知Decoder上一时刻的隐层输出 S t − 1 S_{t-1} St−1,用它与Encoder的各时刻隐层输出 h j h_j hj 做某种操作 f a t t f_{att} fatt,计算出来的相应用 softmax 转化为概率,就是我们所需的权重 a a a,对输入加权求和,计算出输入序列的表达 C C C,作为Decoder当前的部分输入,从而生成 Y t Y_t Yt。这就是Attention的工作机制。
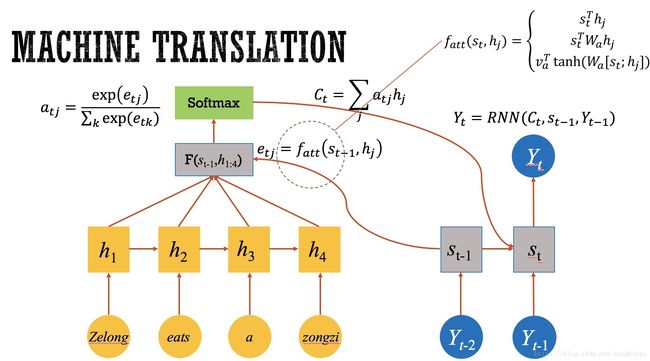
可以说Attention的核心就是 C C C的计算,不同的Attention变体主要体现在 f a t t f_{att} fatt上,常见的计算方法有相乘(dot)与拼接(concat),此外,参与计算的 s s s 和 h h h 也可以做文章,搞出不同的花样,你甚至可以发现,即使跳出Encoder-Decoder这个框架,Attention也可以单独存在,因为他的本质就是“加权求和”。
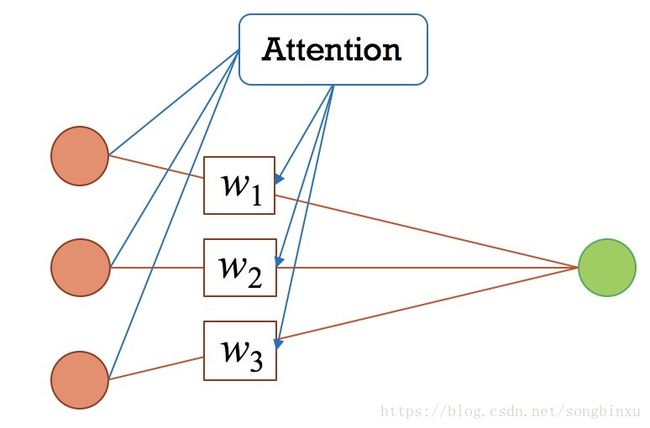
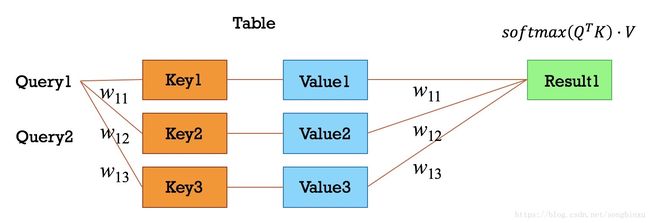
还可以从另一个角度看Attention,那就是键值查询。键值查询应该有三个基本元素:索引(Query),键(Key)和值(Value),你可以理解为这是一个查字典的过程,Key-Value对构成一个字典,用户给一个Query,系统找到与之相同的Key,返回对应的Value。那么问题来了,字典里没有与Query相同的Key怎么办?答案是分别计算Query和每一个已有的Key的相似度 w w w,作为权重分配到所有的Value上,并返回它们的加权求和。对应到上面机器翻译的例子,输出序列的局部信息是Query,输入序列的局部信息是Key, w w w是二者的相似度,而Value设为1即可。从上面的分析看出,Attention也可以理解为某种相似性度量。
Attention 于机器翻译
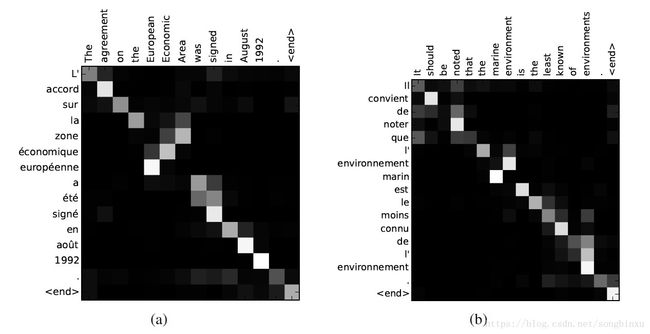
下图即文献给出的法译英任务的Attention概率图,这是两个句子,横轴表示英语,纵轴表示法语,矩阵上的像素值表示概率 a a a(或称重要性、权重、对齐概率等等),颜色越亮表示概率越大。可以明显地看出,由于英语和法语的语法结构不一样,注意力是有所偏移的。
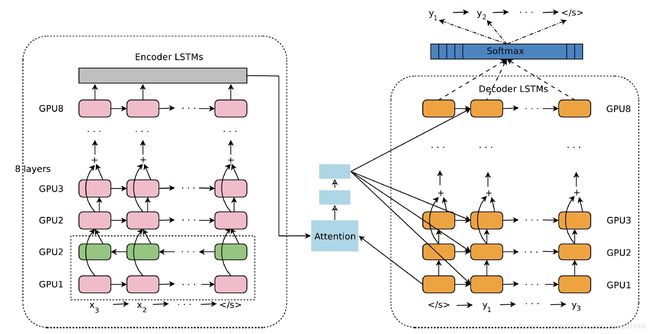
下图是谷歌在2017年发布的线上机器翻译框架,这是一个Encoder-Decoder结构,两者都是多层的LSTM或Bi-LSTM堆叠而成,在中间加入了Attention,看上去比较复杂,但实际上就是上文所述的Attention的使用方法。文章表示,引入Attention之后,中译英任务的相对错误率下降了60%,英译西(西班牙语)错误率甚至下降了83%,这表明Attention确实是有效的。
Self-Attention
有一种特殊的Attention,叫做Self-Attention(自注意力机制)。它是Attention的特例,在Encoder-Decoder中,输入和输出序列是同一个序列时,称为Self-Attention。普通的Attention,在机器翻译中的物理意义是目标语单词和源语单词之间的一种单词对齐机制,而Self-Attention学习的是句子内部的联系(语法结构等),例如下图中的动词“making”与下文的“more difficult”产生了较大联系。
引入Self-Attention的好处在于可以在 O ( 1 ) O(1) O(1)的代价联系序列中两个长期依赖的特征,对于RNN结构可能需要累积更多的时间步骤才能反应过来,因此Self-Attention能够提升网络的可并行性。

文字识别中的 Attention
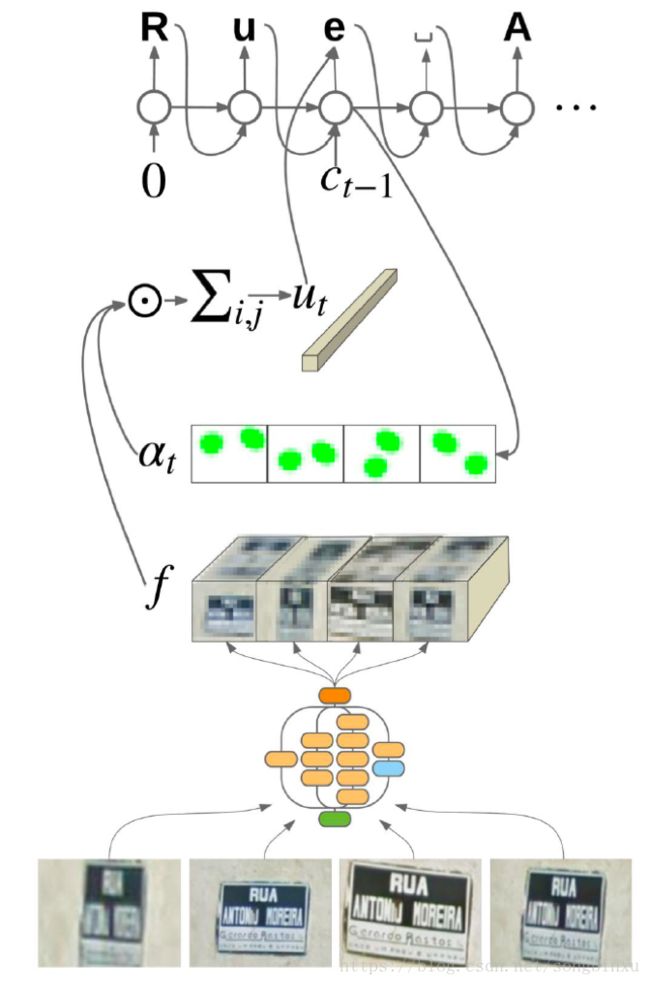
Attention在场景文字识别中有所应用,如上图所示,该识别框架是一个Encoder-Decoder结构,底层由CNN结构提取原始图像及其Augmentation的feature map,即 f i , j , c f_{i,j,c} fi,j,c),此处的 i , j i,j i,j 表示图像中的坐标, c c c 表示通道,并由当前时刻的对齐概率向量 a t , i , j a_{t,i,j} at,i,j 加权求和,得到上下文变量 u t , c u_{t,c} ut,c。
a t , i , j a_{t,i,j} at,i,j 可以理解为当前时刻对输入图像的每一个局部的关注程度,从图像处理的角度也可以理解为一个mask,它是由Decoder网络前一时刻的隐层输出与 f f f 经过某种操作后产生的, a t , i , j a_{t,i,j} at,i,j 与 f f f 加权得到的 u u u 可以理解为网络对输入图像选择性观察得到的结果。 u u u 既作为RNN的输入,也参与生成RNN的预测 c c c。
这么说可能有些难懂,看公式就好了。
a t , i , j = V a T t a n h ( W s s t + W f f i , j , ⋅ ) a t = s o f t m a x i , j ( a t , i , j ) a_{t,i,j}=V_a^T tanh(W_s s_t + W_f f_{i,j,\cdot})\\ a_t=softmax_{i,j}(a_{t,i,j}) at,i,j=VaTtanh(Wsst+Wffi,j,⋅)at=softmaxi,j(at,i,j)
u t , c = ∑ i ∑ j a t , i , j f i , j , c u_{t,c}=\sum_i \sum_j a_{t,i,j}f_{i,j,c} ut,c=i∑j∑at,i,jfi,j,c
x t = W c c t − 1 + W u 1 u t − 1 ( o t , s t ) = R N N ( x t , s t − 1 ) o t ^ = s o f t m a x ( W o o t + W u 2 u t ) x_t=W_c c_{t-1}+W_{u_1}u_{t-1}\\ (o_t, s_t)=RNN(x_t,s_{t-1})\\ \hat{o_t}=softmax(W_o o_t+W_{u_2}u_t) xt=Wcct−1+Wu1ut−1(ot,st)=RNN(xt,st−1)ot^=softmax(Woot+Wu2ut)
c t = a r g max c o t ^ ( c ) c_t=arg \max_c \hat{o_t}(c) ct=argcmaxot^(c)
此外,文章指出计算 a t , i , j a_{t,i,j} at,i,j时对位置不敏感,需要引入位置编码,于是分别引入了两个轴的编码 e i e_i ei 和 e j e_j ej,详情请参考论文。作者表示引入了Attention之后在FSNS数据库(French Street Name Signs)上的正确率达到了84.2%,之前最好的只有72.46%(2016年)。此外,在将 a t , i , j a_{t,i,j} at,i,j 可视化之后,可以明显地看出在生成输出序列中不同的字母时,网络关注着输入图像的不同部位。
a t , i , j = V a T t a n h ( W s s t + W f 1 f i , j , ⋅ + W f 2 e i + W f 3 e j ) a_{t,i,j}=V_a^T tanh(W_s s_t + W_{f_1} f_{i,j,\cdot} + W_{f_2}e_i + W_{f_3}e_j) at,i,j=VaTtanh(Wsst+Wf1fi,j,⋅+Wf2ei+Wf3ej)

推荐系统中的 Attention
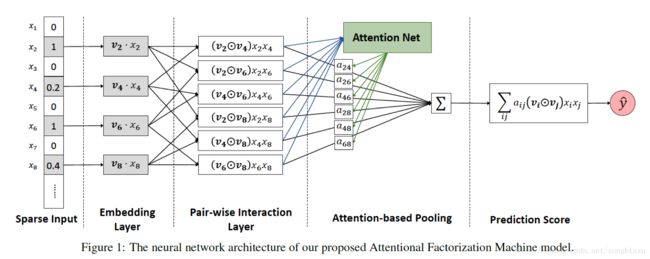
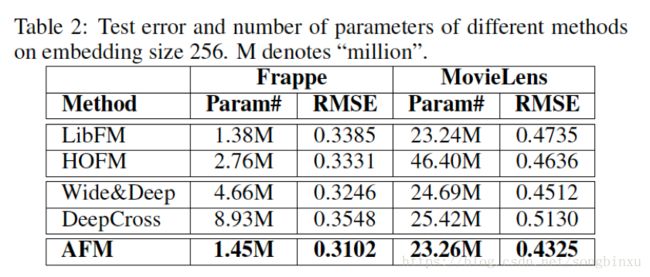
因子分解机(Factorization Machines, FM)是CTR预估中常用的模型,它相当于在LR的基础上引入了Embedding以及Embedding之间的两两内积(Pair-wise Production)。从每一个特征的角度看,它与任意其他特征做配对内积时,参与计算的都是同一个Embedding向量,这是高效的但可能是不够合理,为了解决这个问题,文献提出了AFM(Attentional FM),给每一个Pair-wise Production乘上一个权重,然后再加起来。这个乘上权重的操作就是Attention,具体地,它是一个类MLP结构,内置一系列权重,由Pair-wise Production作为Query查询返回对应的比例参数。
对一个特定的特征来说,Attention的作用是为不同的配对对象分配不同的Embedding,打个比方就像是一个管家,大小姐要与不同的人会晤时,给她搭配不一样的衣服。实际上,“Field-aware FM”(FFM)本质上实现的也是这样的功能,它在与不同的field的特征做内积时使用的是不同的参数,可以估计AFM最多能达到FFM的性能,但是FFM的参数比AFM要多得多。
AFM在实现上类似NFM(Neural FM),区别在于Embedding送入MLP之前需要Reshape,这里不做赘述,有兴趣可以去github找代码,这里是传送门。
最近广告算法似乎都偏向于使用 Embedding+MLP 类方法,即首先将高维极其稀疏的输入特征Embedding到低维稠密特征,然后拼起来输入到MLP结构,好处是可以节省大量人工特征工程的步骤,同时大幅度提升模型性能。然而,这类方法需要将用户兴趣编码成定长向量,这可能会损失信息。什么意思呢?我们的输入特征一般有三种,数值连续型、单值离散型和多值离散型,比如年龄段或性别就是单值离散型特征,它们的特点是只能同时取一个值(例如不可能同时处于两个年龄段),做Embedding之后就是定长向量。多值离散型特征就有些特殊了,用户的兴趣和行为特征是“diverse”的,每个人可能有多个兴趣、多个购买历史,因此该类特征一般不等长。为了构造等长向量(否则无法送入MLP),一般的做法是将每个兴趣、行为的Embedding做一个Pooling。
然而用户的兴趣是“locally activated”的,即用户虽然兴趣有多样性,但特定的广告会激活用户的一个或几个兴趣。例如某肥宅(我)的兴趣包括游戏和垃圾食品,这些兴趣可以从我的历史购买记录中发掘出来,然后当我被展示一款新手游的广告时,我关于游戏的兴趣会被激活,但我关于垃圾食品的兴趣则不会,反之,当我被展示麦当劳一款新汉堡的广告时,我关于垃圾食品的兴趣就会被激活。Embedding&MLP类方法限制了模型的表达能力。
因此论文的作者提出了Deep Interest Network,结构如右下图,在多值离散型特征的Embedding进入Pooling之前,先引入一个Attention,乘上权重。论文将Attention定义为“Local Activation Unit”,它接受两个输入:广告的Embedding,用户特定兴趣或行为的Embedding。Attention的作用、权重的物理意义是特定的广告对用户的某个或某几个兴趣产生的特定的激活。
值得一提的是,该网络是由阿里妈妈盖坤团队于2017年提出的。

Attention is all you need
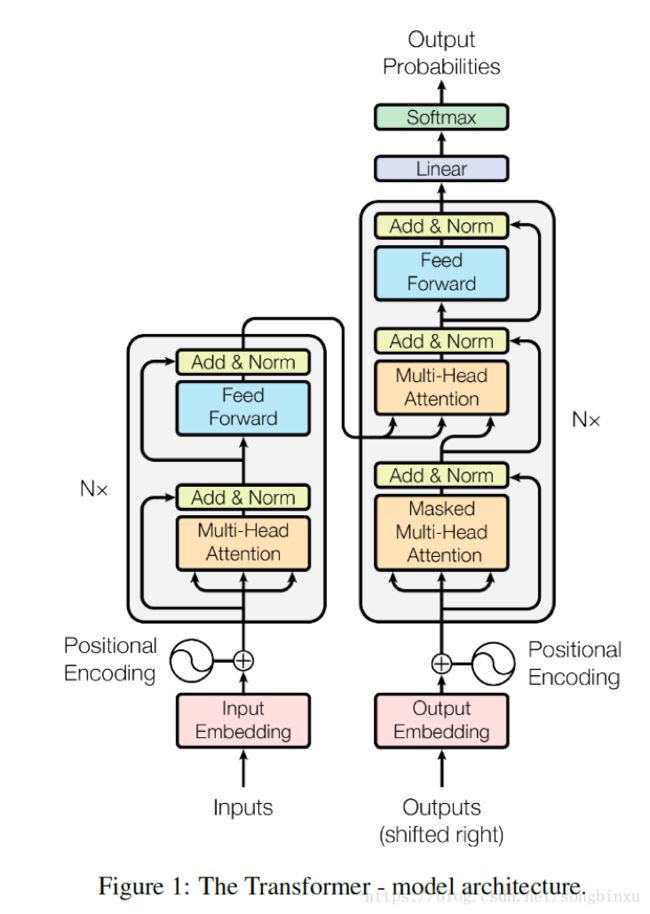
Attention is all you need. 这句话听上去是不是特别霸气?没错,它是由 Google Brain 提出的“大招”,最重大的贡献在于提出一个由纯粹的Attention+MLP结构组成的网络,完全抛弃了CNN和RNN结构,用于机器翻译任务。该结构被称为 transformer (变形金刚?),仍然是一个 Encoder-Decoder 结构,Encoder与Decoder都由多个基本模块堆叠而成。Encoder的基本模块有两个子层:一个多抽头自注意力模块(Multi-head Self-Attention)和一个前向神经网络(FN),Decoder的基本模块有三个子层:一个多抽头自注意力模块、一个多抽头注意力模块(非Self)和一个前向神经网络。
从功能上讲,我认为Encoder的Self-Attention是用来提取输入序列(在翻译问题中是源语种句子)中的长短期依赖的,然后输入到FN提取更高层次的响应,同时Decoder的Self-Attention提取目标语种句子中的长短期依赖,作为Query与Encoder提供Key和Value共同输入另一个Attention模块进行对齐,再进入Decoder的FN并产生最终的概率输出。整个流程从功能上完整地复现了之前的基于RNN的Encoder-Decoder经典结构,而且可并行性很高,没有RNN中的时间依赖。

所谓多抽头Attention,实际上是由多个普通的Attention拼起来的。基本的Attention形式即 Scaled Dot-Product,类似于余弦相似度,作者认为将输入的Q、K和V分别进行多次( h h h次)的线性变换然后拼起来能获得更好的效果,于是产生了这种新颖的Attention结构。Attention可变的地方还很多,预计今后(可能已经)还会出现更多灵活的Attention变体。

Attention 的用途与缺陷
Attention的用武之地,我感觉是几乎万能的。
- 多任务:分类、预测、强化学习、聚类…
- 多领域:机器翻译、推荐系统、图像处理、语音识别…
- 多结构:几乎任何包含“求和”或“局部贡献总体”的结构都可以用
Attention的局限性和缺陷:
- 引入新参数来弥补某方面的拟合能力,可能比不上原有的方法,例如AFM比不上FFM
- 引入新参数,可能造成过拟合
- 引入新参数,带来计算复杂度的增加
最后一点话
Attention在某些论文中说的玄之又玄,其实他解决的问题正是加权求和中权重的合理性配置,之前不乏有相似的想法,只不过做法不同罢了。Attention之所以这么火,我认为一方面跟Google的应用离不开,另一方面也因为它实在太万能了。最近一段时间看了不少有关Attention的博客和文献资料,非常有幸能学到这么有趣的东西,由于毕设应该也会用到,所以我以后也会继续关注Attention的。
参考文献
【博客】深度学习中的注意力机制
【博客】深度学习中的注意力机制(2017版)
【博客】深度学习中的Attention模型介绍及其进展
【博客】注意力机制(Attention Mechanism)在自然语言处理中的应用
【博客】深度学习和自然语言处理中的attention和memory机制
【博客】Attention Networks with Keras
【博客】The fall of RNN / LSTM
【博客】从2017年顶会论文看 Attention Model
【博客】Attention Model(mechanism)的 套路
【博客】DIN(Deep Interest Network of CTR) [Paper笔记]
【博客】自然语言处理中的自注意力机制(Self-Attention Mechanism)
【博客】一文读懂「Attention is All You Need」| 附代码实现
【博客】计算广告CTR预估系列(五)–阿里Deep Interest Network理论
【博客】机器翻译模型Transformer代码详细解析
【知乎】模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
【论文】Recurrent Models of Visual Attention
【论文】Neural Machine Translation by Jointly Learning to Align and Translate
【论文】Effective Approaches to Attention-based Neural Machine Translation
【论文】ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs
【论文】TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering
【论文】Attention Is All You Need
【论文】Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation(谷歌机器翻译系统框架)
【论文】Dynamic Attention Deep Model for Article Recommendation by Learning Human Editors Demonstration(新闻推荐)
【论文】Dipole: Diagnosis Prediction in Healthcare via Attention-based Bidirectional Recurrent Neural Networks(医疗诊断预测)
【论文】A Context-aware Attention Network for Interactive Question Answering(问答系统)
【论文】Multiple Object Recognition with Visual Attention
【论文】Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks(AFM,推荐系统)
【论文】Deep Interest Network for Click-Through Rate Prediction(DIN,推荐系统)
【论文】Attention-based Extraction of Structured Information from Street View Imagery(文字识别)
【github】attention_tf
【github】attention_keras
【github】transformer
【github】attentional_factorization_machine