Stream进阶篇-消息分区实现验证&源码简析
前言
在《消费组实现验证》章节,已经介绍了如何通过消费组避免单个消息被多个实例重复消费。但还有一些场景需要满足,同一个特征的数据被同一个实例消费,比如同一个id的传感器监测数据必须被同一个实例统计计算分析,否则可能无法获取全部的数据。又比如部分异步任务,首次请求启动task,二次请求取消task,此场景就必须保证两次请求至同一实例。本章将介绍如何通过消息分区实现上述场景应用。
本章概要
1、消费者Receiver工程改造;
2、生产者Sender工程改造;
3、消息分区验证;
4、自定义消息分区策略;
消费者Receiver工程改造
1、在MySink中添加分区测试通道
partition-channel:
package com.cloud.shf.stream.sink;
public interface MySink {
/*********************************分区示例通道******************************/
String PARTITION_CHANNEL = "partition-channel";
@Input(PARTITION_CHANNEL)
SubscribableChannel partitionInput();
}
2、添加对
partition-channel通道的监听,如下打印接收到的用户age信息:
/********************************分区示例******************************/
@StreamListener(value = MySink.PARTITION_CHANNEL)
public void partitionReceiver(@Payload User user) {
LOGGER.info("Received-{} from {} channel age: {}", active, MySink.PARTITION_CHANNEL, user.getAge());
}
3、在
application.properties中添加如下配置:
spring.cloud.stream.bindings.partition-channel.group=receiver-partition
spring.cloud.stream.bindings.partition-channel.consumer.partitioned=true
spring.cloud.stream.instanceCount=4
NOTE:
- 分区特性建立在消费组的基础上,故必须配置spring.cloud.stream.bindings.partition-channel.group属性;
- spring.cloud.stream.bindings.partition-channel.consumer.partitioned配置是否启用分区;
- 本次累计共启动4个实例,故定义spring.cloud.stream.instanceCount为4
4、步骤3中的配置为通用型配置,下面将对每个通过profile启动的实例添加配置:
- application-1.properties配置如下:
spring.cloud.stream.instanceIndex
=
0
- application-2.properties配置如下:
spring.cloud.stream.instanceIndex
=
1
- application-3.properties配置如下:
spring.cloud.stream.instanceIndex
=2
- application-4.properties配置如下:
spring.cloud.stream.instanceIndex
=
3
NOTE:对应每个实例设定一个索引值,不能重复,如果重复将会出现同
instanceCount值实例轮询接收消息;
小节:自此,receiver工程改造完成。
生产者Sender工程改造
1、同receiver工程,在MySink中添加分区测试通道
partition-channel:
package com.cloud.shf.stream.sink;
public interface MySink {
/*********************************分区示例通道******************************/
String PARTITION_CHANNEL = "partition-channel";
@Output(PARTITION_CHANNEL)
MessageChannel partitionInput();
}
2、添加
PartitionSource进行消息的轮询生成发送:
package com.cloud.shf.stream.source;
@EnableBinding(value = MySink.class)
public class PartitionSource {
private static final Logger LOGGER = LoggerFactory.getLogger(PartitionSource.class);
@Bean
@InboundChannelAdapter(value = MySink.PARTITION_CHANNEL, poller = @Poller(fixedRate = "5000", maxMessagesPerPoll = "1"))
public MessageSource partitionMessageSource() {
return () -> {
Double value = Math.random() * 10 % 5;
int age = value.intValue();
LOGGER.info("current age : {}", age);
Map headers = new HashMap<>();
headers.put("router", age);
return new GenericMessage<>(new User().setUsername("shuaishuai").setAge(age), headers);
};
}
}
NOTE:
- 其消息体仍然为User用户,并设定年龄为0~4的随机数,此值将作为后续分区的标识;
- 在消息中添加Header消息头,并设定router属性为age值,作为后续自定义分区Class实现的分区标识;
3、在application.properties中添加如下配置:
spring.cloud.stream.bindings.partition-channel.producer.partitionKeyExpression=payload.age
spring.cloud.stream.bindings.partition-channel.producer.partitionCount=4- spring.cloud.stream.bindings.partition-channel.producer.partitionKeyExpression:标识分区key表达式,其支持SpEL表达式;由于我们采用的是User对象作为消息体,故可以采用payload.age获取其age属性值;
- spring.cloud.stream.bindings.partition-channel.producer.partitionCount:此属性表示将会有几个消费者实例,其值将作为后续分区的重要计算参数;
小节:自此,sender工程改造完成。
消息分区验证
1、通过
--spring.profiles.active=1|2|3|4依次启动4个
receiver实例,并启动
sender服务,此时观察各服务的控制台log如下:
- sender工程如下:
- 8001服务

- 8002服务

- 8003服务

- 8004服务

通过日志分析,可以看到4个不同索引的receiver服务实例,接收的age属性都一致。age属性即为消息的关键特征,其很好的验证了相同的关键特征将被同一实例接收处理。
2、再来看看rabbitmq控制台
Exchange看板信息,可以看到
partition-channel通道的Bindings如下:
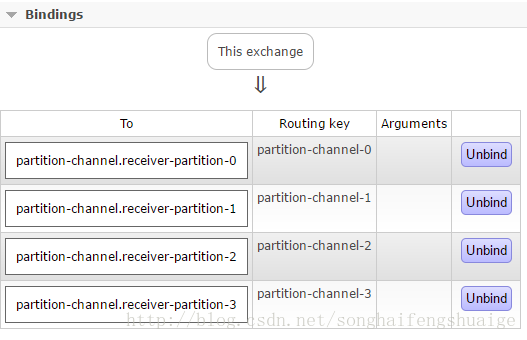
其相比消费者时多了Routing key列值,并且QueueName的规则也发生了变化,这正式为何能够实现消息分区的原理,具体的代码实现可以参看源码:
- org.springframework.cloud.stream.binding. MessageConverterConfigurer
- org.springframework.cloud.stream.binder.rabbit.provisioning.RabbitExchangeQueueProvisioner
3、源码简要剖析:
在
org.springframework.cloud.stream.binding. MessageConverterConfigurer中可以看到如下

其主要配置定义生产和消费通道,继续往下跟看看
configureMessageChannel的定义
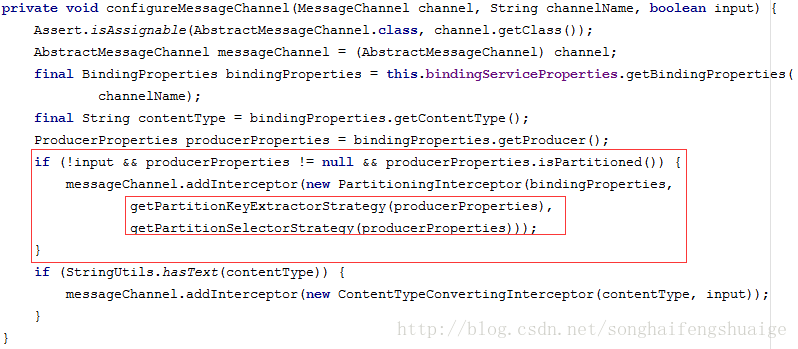
红色框部分即对应了
application.properties中配置,满足条件就会配置对应的分区实现,其中一个参数为关键特征提取策略、实现一个为分区选择策略,继续来看看两个方法的定义
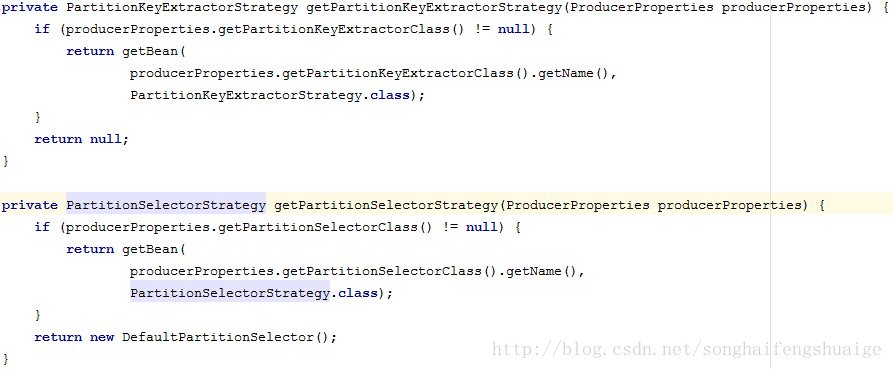
其均会判断在
application.properties中是否自定义了配置相关实现,如果没有将采用默认定义。从Bean的获取逻辑可以看到,两个策略的定义分别实现
PartitionKeyExtractorStrategy、
PartitionSelectorStrategy两个接口即可,并配置于
application.properties中。先来看看默认分区选择策略的定义

其采用发送对象的
hashCode作为了关键词分区选择策略。通过getBean方法可以发现,我们也可以在通过
@Bean注册对应的bean实例,通过
beanFactory获取对应的bean实例,此方式还能够通过实现
ApplicationContextAware获取
ApplicationContext等类似其他更多扩展性。
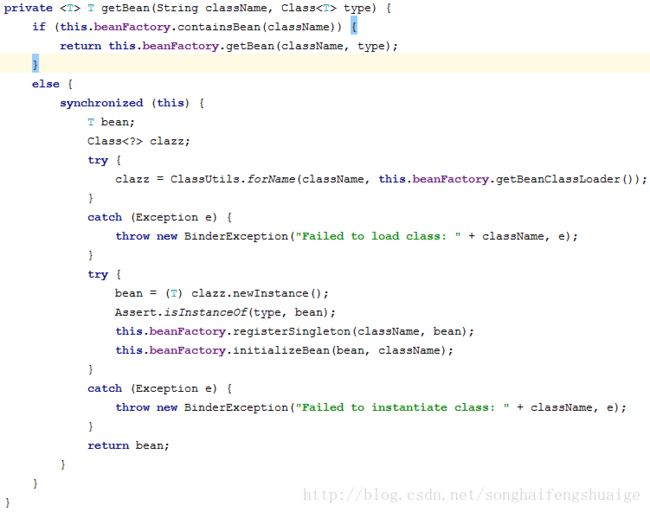
小节:在源码分析中已经发现,可以通过自定义分区策略来实现更加复杂的场景处理,下面一小节将来模拟验证其使用方式。
自定义消息分区策略
1、定义MyPartitionKeyExtractor,其实现
PartitionKeyExtractorStrategy、
PartitionSelectorStrategy接口:
package com.cloud.shf.stream.partition.extractor;
public class MyPartitionKeyExtractor implements PartitionKeyExtractorStrategy, PartitionSelectorStrategy {
@Override
public int selectPartition(Object key, int divisor) {
return ((Map) key).get("router");
}
@Override
public Object extractKey(Message message) {
return message.getHeaders();
}
}
NOTE:
- 采用header头信息作为关键特征;
- 根据头信息中的router值作为分区选择值;
2、修改
application.properties中添加如下配置:
#spring.cloud.stream.bindings.partition-channel.producer.partitionKeyExpression=payload.age
spring.cloud.stream.bindings.partition-channel.producer.partitionCount=4
spring.cloud.stream.bindings.partition-channel.producer.partitionKeyExtractorClass=com.cloud.shf.stream.partition.extractor.MyPartitionKeyExtractor
spring.cloud.stream.bindings.partition-channel.producer.partitionSelectorClass=com.cloud.shf.stream.partition.extractor.MyPartitionKeyExtractor
NOTE:
- 取消partitionKeyExpression配置,采用partitionKeyExtractorClass来替换;
- 配置partitionSelectorClass作为分区选择值策略;
3、通过
--spring.profiles.active=1|2|3|4依次启动4个
receiver实例,并启动
sender服务,通过控制台可以发现与上述消息分区验证一样的结果;
总结
消息分区是建立在消息组的基础上更高阶的一个应用特性,对于应用来说需要我们进行的配置比较少,很容易上手应用,并且可以通过实现
PartitionKeyExtractorStrategy、
PartitionSelectorStrategy接口自定义分区策略。
思考
在单服务多实例运行过程中,很难保证所有的节点均能够永不出现宕机状态,一旦出现某个index节点宕机,则其对应的Routing key值的Queue中的消息将无法被正常消费,所有的消息会被持久化在队列中,等待服务再次启动,然后被正常消费,但这里存在一定的时间差,一旦修复宕机时间比较久将会必然会带来一定的负面影响。如何解决呢?
目前的解决思路:在sender实例中定义一个定时任务,能够一个可以接受的时间内轮询查看所有receiver节点的健康状态(可以结合服务注册中心和配置中心获取对应的服务信息),并获取对应的
instanceIndex值,然后结合
PartitionSelectorStrategy自定义的策略,使其返回值仅仅能够被分配至存活的节点
Routing key下。
当然该方式还没有具体验证,仅仅是一个思路。