机器学习与应用—学习笔记
文章目录
- 机器学习简介
- 数学知识
- 微积分和线性代数
- 导数
- 向量与矩阵
- 偏导数与梯度
- 雅克比矩阵
- Hessian矩阵
- 行列式
- 特征值和特征向量
- 二次型
- 向量与矩阵求导
- 最优化方法
- 梯度下降法
- 牛顿法
- 坐标下降法
- 拉格朗日乘数法
- 凸优化
- 拉格朗日对偶
- KKT条件
- 概率论
- 随机事件与概率
- 条件概率
- 随机变量
- 数学期望与方差
- 随机向量
- 最大似然估计
- 机器学习基本概念
- 算法分类
- 模型评价指标
- 准确率
- 精准率
- 召回率
- 真正(阳)率 假正(阳)率
- ROC 曲线
- 混淆矩阵
- 交叉验证
- 模型选择
- 过拟合与欠拟合
- 偏差与方差分解
- 正则化
- 贝叶斯分类器
- 决策树
- K近邻算法
- 参考资料
机器学习简介
机器学习的训练过程是通过训练样本寻找分类函数或模型的过程。有监督(聚类和数据降维没有训练过程)的机器学习的一般流程如下图所示,机器学习算法与其它算法的一个显著的区别是需要样本数据,是一种数据驱动的方法。
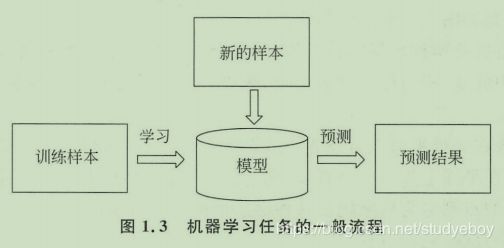
机器学习(Machine Learning)是人工智能的分支和一种实现方法,根据样本数据学习模型,用模型对数据进行预测与决策,也称为推理(inference)。机器学习是让计算机算法具有类似人的学习能力,像人一样能够从实例中学习到经验和知识,从而具备判断和预测的能力。机器学习的本质是模型的选择以及模型参数的确定。机器学习与之前基于人工规则的模型(逻辑推理、知识库、专家系统)相比,无需人工给出规则,而让程序自动从大量的样本中抽象、归纳出知识与规则。因此,它具有更好的通用性,采用这种统一的处理框架,可以将机器学习算法用于各种不同的领域。
数学知识
微积分和线性代数
导数
导数定义为函数的自变量变化值趋向于0时,函数值的变化量与自变量的变化量比值的极限,即:

如果上面的极限存在,则称函数在该点处可导。导数的几何意义是函数在某一点处的切线的斜率,典型的物理意义是瞬时速度。

导数和函数的单调性密切相关。导数大于0时函数单调增,导数小于0时函数单调减,在极值处导数必为0。导数为0的点称为函数的驻点。
二阶导数决定函数的凹凸性。如果二阶导数大于0,则函数为凸函数;如果二阶导数小于0,则为凹函数。二阶导数等于0的点称为函数的拐点。
根据一阶导数和二阶导数,可以得到一元函数的极值判别法:在驻点处,如果二阶导数大于0,则为函数的极小值点,如果二阶导数小于0,则为极大值点。如果二阶导数等于0,则情况不定。
向量与矩阵
向量是有大小和方向的量,由多个数构成一维数组,每个数称为它的分量。分量的数量称为向量的维数。物理中的力,速度是典型的向量。

如果两个向量的内积为0,则称它们正交,这是几何中垂直这个概念在高维空间的推广。







偏导数与梯度


梯度和 函数的单调性、极值有关 根据Fermat 定理,可导函数在某一 点处取得极值的必要条件是梯度为 0,梯度为0 的点称为函数的驻点 。需要 注意的是,梯度为0 只是函数取极值的必要条件而不是充分条件。

雅克比矩阵

雅克比矩阵可以简化多元复合函数求导的公式。
Hessian矩阵




其中,o表示高阶无穷小。H是Hessian矩阵。它和一元函数的泰勒展开在形式上是统一的。
行列式



特征值和特征向量




二次型

向量与矩阵求导


最优化方法
最优化即寻找函数极值点的数值方法。将最优化问题统一表述为求解函数的极小值问题(极大值问题通过目标函数加负号的方式转换为极小值问题)。对优化变量有约束(等式约束和不等式约束),定义了优化变量的可行域,即满足约束条件的点构成的集合。
梯度下降法
梯度下降法沿梯度向量的反方向进行迭代以达到函数的极值点。
牛顿法
坐标下降法
坐标下降法每次迭代时在当前点处沿一个坐标轴方向进行一维搜索,固定其他的坐标方向,找到一个一元函数的极小值。在整个过程中依次循环使用不同的坐标方向进行迭代,一个周期的一维搜索迭代过程相当于一个梯度迭代。
拉格朗日乘数法

凸优化
求解一般函数的全局极小值是非常困难的,如果目标函数限制为凸函数、优化变量的可行域限定为凸集,同时满足这两个限定条件的最优化问题称为凸优化问题。
拉格朗日对偶
对偶是求解最优化问题的一种手段,它将一个最优化问题转化为另外一个更容易求解的问题。这两个问题是等价的。
KKT条件

概率论
随机事件与概率

条件概率


随机变量



数学期望与方差



随机向量
随机向量是一个向量,它的每个分量都是随机变量。随机向量也有离散型和连续型两种情况。


最大似然估计
已知样本服从的分布,要估计分布函数的参数,确定这些参数常用的一种方法是最大似然估计。
最大似然估计(Maximum Likelihood Estimate,MLE)构造一个似然函数,通过让似然函数最大化,求解出参数。最大似然估计的直观解释是。寻求一组参数,使得给定的样本集出现的概率最大。这样做的依据是这组样本数据已经发生了,因此,应该最大化它们发生的概率,即似然函数。

机器学习基本概念
算法分类
模型评价指标
准确率
准确率的定义是预测正确的结果占总样本的百分比,其公式如下:
准 确 率 = ( T P + T N ) / ( T P + T N + F P + F N ) 准确率=(TP+TN)/(TP+TN+FP+FN) 准确率=(TP+TN)/(TP+TN+FP+FN)

虽然准确率可以判断总的正确率,但是在样本不平衡的情况下,并不能作为很好的指标来衡量结果。举个简单的例子,比如在一个总样本中,正样本占90%,负样本占10%,样本是严重不平衡的。对于这种情况,我们只需要将全部样本预测为正样本即可得到90%的高准确率。由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
精准率
精准率(Precision) 又叫查准率,它是针对预测结果而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,其公式如下:
精 准 率 = T P / ( T P + F P ) 精准率=TP/(TP+FP) 精准率=TP/(TP+FP)

精准率和准确率看上去有些类似,但是完全不同的两个概念。精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
召回率
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率,其公式如下:
精 准 率 = T P / ( T P + F N ) 精准率=TP/(TP+FN) 精准率=TP/(TP+FN)

真正(阳)率 假正(阳)率
真 正 率 ( T P R ) = T P / ( T P + F N ) 真正率(TPR)= TP/(TP+FN) 真正率(TPR)=TP/(TP+FN)
假 正 率 ( F P R ) = F P / ( F P + T N ) 假正率(FPR)= FP/(FP+TN) 假正率(FPR)=FP/(FP+TN)

真正率的公式和召回率的公式相同。
真正率和假正率分别在实际的正样本和负样本中来观察相关概率问题。正因为如此,所以无论样本是否平衡,都不会被影响。例如总样本中,90%是正样本,10%是负样本。用准确率是有水分的,但是用TPR和FPR不一样。TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系,所以可以看出:如果从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了。
ROC 曲线
ROC曲线中的主要两个指标就是真正率和假正率,其中横坐标为假正率(FPR),纵坐标为真正率(TPR),下面就是一个标准的ROC曲线图。
混淆矩阵

交叉验证
对于精度指标的计算,最简单的做法是选择一部分样本作为训练集,用另一部分样本作为测试集来统计算法的准确率。交叉验证(Cross Validation)是一种更复杂的统计准确率的技术。k折交叉验证将样本随机、均匀的分成k份,轮流用其中的k-1份训练模型,1份用于测试模型的准确率,用k个准确率的均值作为最终的准确率。
模型选择
过拟合与欠拟合
欠拟合(Under-Fitting)也称欠学习,其直观表现是训练得到的模型在训练集上表现查,没有学到数据的规律。引起欠拟合的原因有:
- 模型本身过于简单,例如,数据本身是非线性的但是使用了线性模型;
- 特征数太少无法正确建立映射关系。
过拟合(Over-Fitting)也称过学习,它的直观表现是在训练集上表现好,在测试集上表现不好,推广泛化性能差。过拟合的根本原因是训练数据包含抽样误差,在训练时模型将抽样误差进行了拟合。抽样误差是指抽样得到的样本集和整体数据集之间的偏差。引起过拟合的可能原因有: - 模型本身过于复杂,拟合了训练样本集中的噪声。此时需要选用更简单的模型,或者对模型进行裁剪。
- 训练样本太少或者缺乏代表性。此时需要增加样本数,或者增加样本的多样性。
- 训练样本噪声的干扰,导致模型拟合了这些噪声,这时需要剔除噪声数据或者改用对噪声不敏感的模型。

偏差与方差分解
模型的泛化误差可以分解成偏差和方差。偏差是模型本身导致的误差,即错误的模型假设所导致的误差,它是模型的预测值的数学期望和真实值之间的差距。高偏差意味这模型本身的输出值与期望值差距很大,因此会导致欠拟合问题。
方差是由于对训练样本集的小波动敏感而导致的误差。可以理解为模型预测值的变化范围,即模预测值的波动程度。高方差意味着算法对训练样本集中的随机噪声进行建模,从而出现过拟合问题。
模型的总体误差可以分解为偏差的平方与方差之和。如果模型过于简单,一般会有大的偏差和小的方差;反之,如果模型复杂则会有大的方差但偏差很小。这是一对矛盾,因此,需要在偏差和方差之间做一个折中。
正则化
有监督机器学习算法训练的目标是最小化误差函数。在预测函数的类型选定之后,人们能控制的只有函数的参数。为了防止过拟合,可以在损失函数加上一个惩罚项,对复杂的模型进行惩罚,强制让模型的参数值尽可能小以使得模型更简单,加入的惩罚项称为正则项。
贝叶斯分类器
贝叶斯分类器是一种概率模型,它用贝叶斯公式解决分类问题。如果样本的特征向量服从某种概率分布,则可以计算特征向量属于一个类的条件概率,条件概率最大的类为分类结果。如果假设特征向量各个分量之间相互独立,则为朴素贝叶斯分类器;如果假设特征向量服从多维正态分布,则为正态贝叶斯分类器。
决策树
决策树是一种基于规则的方法,它用一组嵌套的规则进行预测。在树的每个决策结点处,根据判断结果进入一个分支,反复执行这种操作直到到达叶子节点,得到预测结果。这些规则是通过训练得到的,而不是人工制定的。
K近邻算法
k近邻算法(KNN算法)的核心思想是:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计这些样本的类别进行投票,投票最多的那个类就是分类结果。因为直接比较待预测样本和训练样本的距离,KNN算法也称为基于实例的算法。
参考资料
- 【机器学习笔记】:一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC