linux内核netfilter模块分析之:HOOKs点的注册及调用
-1: 为什么要写这个东西?
最近在找工作,之前netfilter 这一块的代码也认真地研究过,应该每个人都是这样的你懂 不一定你能很准确的表达出来。 故一定要化些时间把这相关的东西总结一下。
0:相关文档
linux 下 nf_conntrack_tuple 跟踪记录 其中可以根据内核提供的数据结构获取连接跟踪记录。
iptables 中的NAT使用总结 iptable的在防火墙上面的应用。
1:iptable中三个tables所挂接的HOOKs
其实这个问题很简单的运行iptables打开看看就知道,此处的hook与内核的hook是对应起来的。
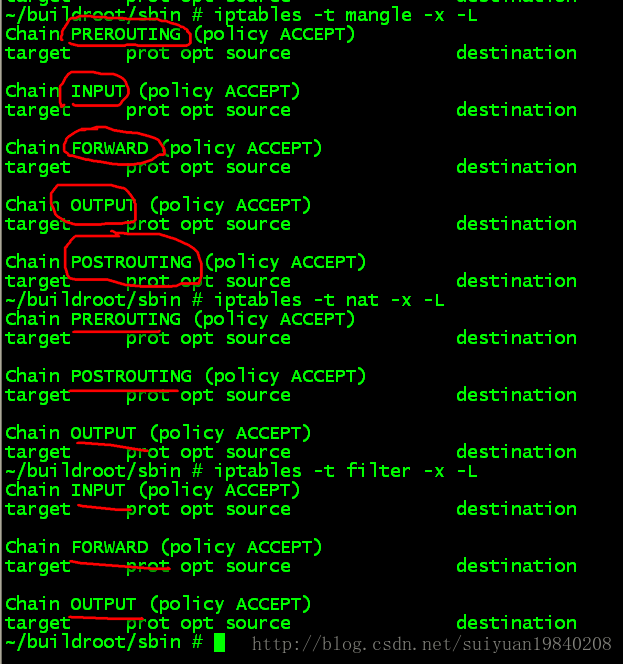
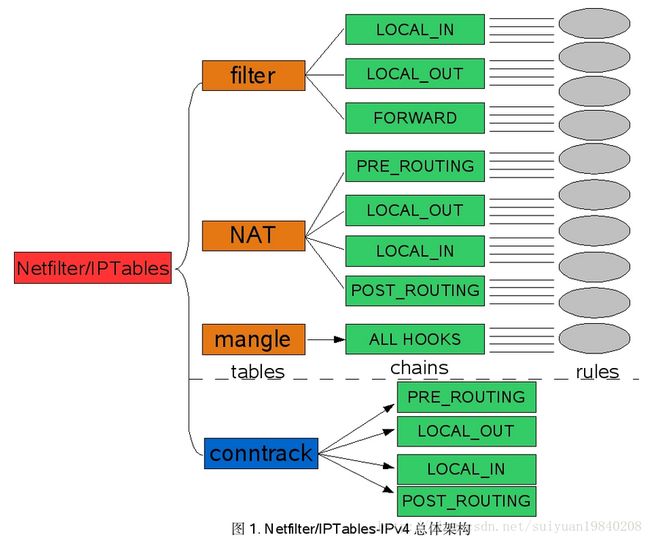
因此在内核中注册的5个HOOK点如下:
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS
};
在向下看linux内核中的实现之前在看看一个数据包在进过linux内核中neitfilter的处理过程。
其中这5个HOOK点的执行点说明如下:
数据报从进入系统,进行IP校验以后,首先经过第一个HOOK函数NF_IP_PRE_ROUTING进行处理;
然后就进入路由代码,其决定该数据报是需要转发还是发给本机的;
若该数据报是发被本机的,则该数据经过HOOK函数NF_IP_LOCAL_IN处理以后然后传递给上层协议;
若该数据报应该被转发则它被NF_IP_FORWARD处理;
经过转发的数据报经过最后一个HOOK函数NF_IP_POST_ROUTING处理以后,再传输到网络上。
本地产生的数据经过HOOK函数NF_IP_LOCAL_OUT 处理后,进行路由选择处理,然后经过NF_IP_POST_ROUTING处理后发送出去。
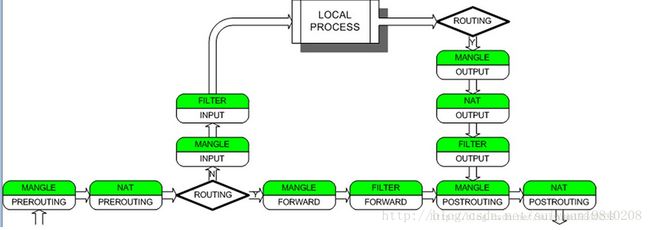
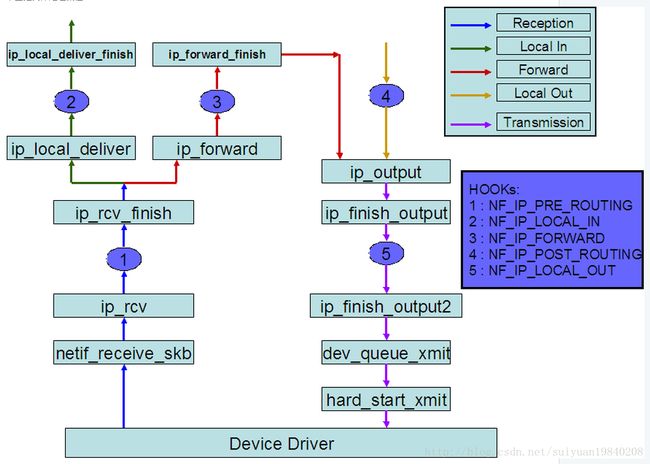
上面的图可以知道,一个数据包在内核中进行的hook的处理点。
2 :proc文件下的跟踪记录
上面的就是连接跟踪记录,其中记录linux系统建立的每一条连接,其中包括源IP,目的IP,源port,目的port,协议ID,其这些可以称为5元组。有关这个在linux内含中的定义是的结构体 struct nf_conn 中的变量
/* Connection tracking(链接跟踪)用来跟踪、记录每个链接的信息(目前仅支持IP协议的连接跟踪)。
每个链接由“tuple”来唯一标识,这里的“tuple”对不同的协议会有不同的含义,例如对tcp,udp
来说就是五元组: (源IP,源端口,目的IP, 目的端口,协议号),对ICMP协议来说是: (源IP, 目
的IP, id, type, code), 其中id,type与code都是icmp协议的信息。链接跟踪是防火墙实现状态检
测的基础,很多功能都需要借助链接跟踪才能实现,例如NAT、快速转发、等等。*/
/* XXX should I move this to the tail ? - Y.K */
/* These are my tuples; original and reply */
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX]; 此变量就保存着上面的跟踪记录,
3:hooks点的定义及注册
其中每个不同协议的不同HOOK点最终都会注册到全局的nf_hooks链表变量之中:同时注册到同一个HOOK的处理函数会根据优先级的不同的进行先后处理。
extern struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS];
其中定义的协议如下:
enum {
NFPROTO_UNSPEC = 0,
NFPROTO_IPV4 = 2, //ipV4
NFPROTO_ARP = 3, //ARP
NFPROTO_BRIDGE = 7, //brigde
NFPROTO_IPV6 = 10,
NFPROTO_DECNET = 12,
NFPROTO_NUMPROTO,
};
NF_MAX_HOOKS 宏的定义已经在前面说明。HOOK点的定义。

与下面的HOOK的struct nf_hook_ops对比一下就可以看到差异:变量pf的值不同,优先级不同,即内核中根据不同的协议类型可以注册不同的挂载点进行不同的优先级数据包的处理。

其注册使用函数为:nf_register_hooks()函数在内核中多个地方出现,因为用户可以根据自己的需要对特定的协议在特定的位置添加HOOK出现函数。
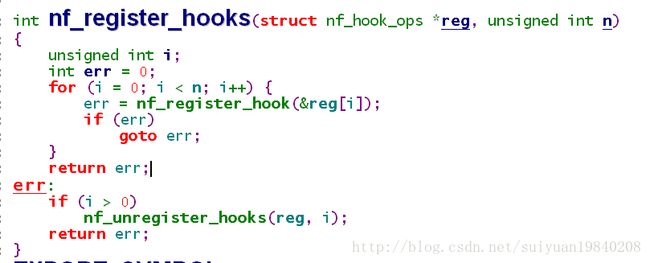
nf_register_hook()函数的实现就是:
int nf_register_hook(struct nf_hook_ops *reg)
{
struct nf_hook_ops *elem;
int err;
err = mutex_lock_interruptible(&nf_hook_mutex);
if (err < 0)
return err;////遍历已经注册的的HOOK,OPS,将新加入的根据优先级添加到链表最后
list_for_each_entry(elem, &nf_hooks[reg->pf][reg->hooknum], list) {
if (reg->priority < elem->priority)
break;
}
list_add_rcu(®->list, elem->list.prev);
mutex_unlock(&nf_hook_mutex);
return 0;
}上面就是HOOK点的注册函数,即根据协议类型和HOOK点注册到全局数组中nf_hooks[][]中。
4:注册的HOOK点何时被使用?
在linux内核中当需要使用注册的HOOK点时,使用函数:
#define NF_HOOK(pf, hook, skb, indev, outdev, okfn) \
NF_HOOK_THRESH(pf, hook, skb, indev, outdev, okfn, INT_MIN)
NF_HOOK->NF_HOOK_THRESH->nf_hook_thresh->nf_hook_slow——这个是最终的执行函数。
先看看下面函数都返回值:
/* Responses from hook functions. */
#define NF_DROP 0
#define NF_ACCEPT 1
#define NF_STOLEN 2
#define NF_QUEUE 3
#define NF_REPEAT 4
#define NF_STOP 5
#define NF_MAX_VERDICT NF_STOP
int nf_hook_slow(u_int8_t pf, unsigned int hook, struct sk_buff *skb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
struct list_head *elem;
unsigned int verdict;
int ret = 0;
/* We may already have this, but read-locks nest anyway */
rcu_read_lock();
elem = &nf_hooks[pf][hook];//是不是很熟悉就是上面的全局变量专门用来注册全局HOOK点的变量。
next_hook:/* 开始遍历对应的netfilter的规则,即对应的proto和hook挂载点 */
verdict = nf_iterate(&nf_hooks[pf][hook], skb, hook, indev,outdev, &elem, okfn, hook_thresh);
if (verdict == NF_ACCEPT || verdict == NF_STOP) {
ret = 1;
} else if (verdict == NF_DROP) {
kfree_skb(skb);
ret = -EPERM;
} else if ((verdict & NF_VERDICT_MASK) == NF_QUEUE) {
if (!nf_queue(skb, elem, pf, hook, indev, outdev, okfn,
verdict >> NF_VERDICT_BITS))
goto next_hook;
}
rcu_read_unlock();
return ret;
}现在来看看nf_iterate()函数:
unsigned int nf_iterate(struct list_head *head,
struct sk_buff *skb,
unsigned int hook,
const struct net_device *indev,
const struct net_device *outdev,
struct list_head **i,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
unsigned int verdict;
//其中head就是全局的2维数组nf_hooks,
/*
* The caller must not block between calls to this
* function because of risk of continuing from deleted element.
*/
list_for_each_continue_rcu(*i, head) {
struct nf_hook_ops *elem = (struct nf_hook_ops *)*i;
if (hook_thresh > elem->priority)
continue;
/* Optimization: we don't need to hold module
reference here, since function can't sleep. --RR */
verdict = elem->hook(hook, skb, indev, outdev, okfn);//根据协议和HOOK点执行挂在的处理函数
if (verdict != NF_ACCEPT) {//返回结果进行判断。
#ifdef CONFIG_NETFILTER_DEBUG
if (unlikely((verdict & NF_VERDICT_MASK)
> NF_MAX_VERDICT)) {
NFDEBUG("Evil return from %p(%u).\n",
elem->hook, hook);
continue;
}
#endif
if (verdict != NF_REPEAT)
return verdict;
*i = (*i)->prev;
}
}
return NF_ACCEPT;
}对各个返回值的解释如下:
在数据包流经内核协议栈的整个过程中,在内中定义的HOOK中的如:PRE_ROUTING、LOCAL_IN、FORWARD、LOCAL_OUT和POST_ROUTING会根据数据包的协议簇PF_INET到这些关键点去查找是否注册有钩子函数。如果没有,则直接返回okfn函数指针所指向的函数继续走协议栈;如果有,则调用nf_hook_slow函数,从而进入到Netfilter框架中去进一步调用已注册在该过滤点下的钩子函数,再根据其返回值来确定是否继续执行由函数指针okfn所指向的函数
