目标检测算法
目标检测算法
文章目录
- 目标检测算法
- 全卷积神经网络(FCN)
- 非极大值抑制(Non-max suppression)
- R-CNN
- 算法流程
- SPP-Net(Spatial Pyramid Pooling Net)
- Fast-RCNN
- Faster-RCNN
- Faster-RCNN-RPN的损失函数
- Faster-RCNN的训练流程
- 目标检测的one-stage & two-stage
- SSD(Single shot multibox detector)
- 特征金字塔
- YOLO (You Only Look Once)
- YOLO V1
- YOLO-V1预测工作流程
- YOLO-V1的代价函数
- YOLO-V1的缺点
- YOLO-V2
- YOLO-V3
- YOLO-V3先验框
全卷积神经网络(FCN)
对于一个各层参数结构都设计好的神经网络来说,输入的图片大小需要是固定的,如AlexNet,VGGNet等都需要输入固定大小的图片才能正常工作
FCN的精髓是让一个已经设计好的网络可以输入任意大小的图片

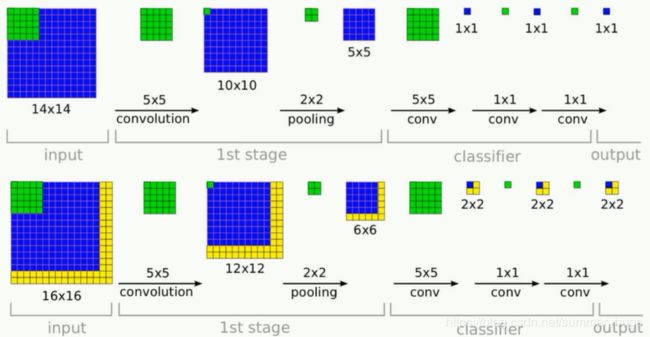
Q:为什么FCN的速度比普通的滑动窗口快?
A:普通的滑动窗口方法是对每次窗口内的图像进行判断(判断是前景还是背景,如果是前景则需要判断是哪种物体),相当于每次判断都是对图像进行识别(分类);而FCN则使用卷积操作,将图像“缩小”,缩小后的图像上的每个点都对应原图像上的一个区域,这样就只用判断缩小后图像上的每个点是否是目标区域即可,大大减少了计算量
mAP(mean average precision)平均准确率均值
每个类别都可以根据recall和precision绘制一条曲线,那么AP就是该曲线下的面积,而mAP是多个类别AP的平均值,这个值介于[0,1],且越大越好,该指标是目标检测算法中最重要的一个
非极大值抑制(Non-max suppression)
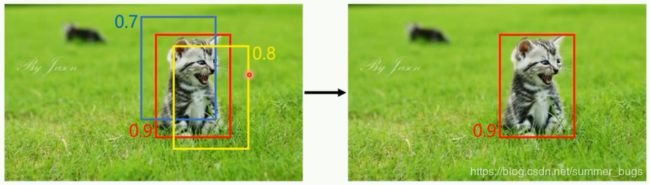
选出置信度最高的候选框,如果和当前最高分的候选框重叠面积IoU大于一定阈值,则将其删除(如上图,红色框是置信度最高的候选框,如果黄色,蓝色候选框和红色框的IoU大于一定阈值,则将其去掉)
当存在多预测目标时,先选取置信度最大的候选框b1,然后根据IoU阈值来去除b1候选框周围的候选框,然后在选取置信度第二大的候选框b2,然后去除b2候选框周围的候选框
R-CNN
RCNN(Regions with CNN feature)是将CNN方法应用到目标检测问题上的一种算法,借助CNN良好的特征提取和分类性能,通过RegionProposal方法实现目标检测
前面提到滑动窗口法可以得到目标所在的区域,但是会产生大量的计算,除了滑动窗口法之外,还有另外一类基于区域(Region Proposal)的方法,selective search就是其中之一
selective search(该算法的作用就是用来生成候选区域!)
-
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
-
while S≠空集:
step2:找出相似度最高的两个区域,将其合并为芯级Rt,添加进R
step3:从S中移除所有与step2中有关的子集
step4:重新计算新集Rt与所有子集的相似度
(这里的相似度主要考虑颜色,纹理,尺寸,交叠四个方面)

算法流程
-
1.选择一个分类模型(如AlexNet,VGGNet等)
-
2-1 去掉最后一个全连接层
2-2 将分类数从1000改为N+1(对于VOC数据集N=20)
2-3 对该模型做fine-tuning(主要目的是优化卷积层和池化层的参数)
-
3.论文使用的分类器是VGG16,用到的网络Pool5后面的一层是fc6全连接层,对每一个候选区域进行特征提取:
Resize区域大小,然后做一次前向运算,将第五个池化层的输出(也就是候选框提取到的特征)保存到硬盘
-
4-1 训练阶段(分类):
使用pool5输出的图像特征训练SVM分类器,来判断这个候选框里的物体类别
4-2 测试阶段:
每个类别对应一个SVM,判断是不是属于这个类别
-
5-1 训练阶段(回归):
使用pool5输出的图像特征训练一个回归器(dx,dy,dw,dh),dx表示水平平移,dy表示竖直平移,dw表示宽度缩放,dh表示高度缩放
5-2 测试阶段:
使用回归器调整候选框位置
SPP-Net(Spatial Pyramid Pooling Net)
SPP-Net的思想对RCNN进化贡献很大
RCNN的最大瓶颈是生成的2k个候选区域都要经过一次CNN,速度非常慢,SPP-Net最大的改进是只需要将原图做一次卷积操作,就可以得到每个候选区域的特征
(下图的上面是RCNN,下面是SPP-Net)

SPP-Net的重点是金字塔池化层(Spatial Pyramid Pooling)
金字塔池化层可以将不同大小的特征同变成相同大小
下图表示任意一张特征图经过金字塔池化后都会得到21个值(16+4+1)

特征映射:对卷积层可视化可以发现,输入图片的某个位置的特征反应在特征图上也是在相同的位置
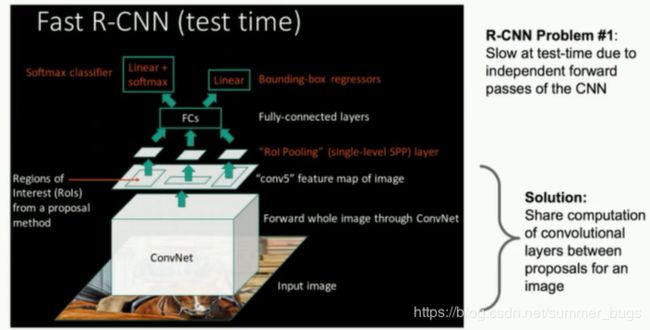
Fast-RCNN
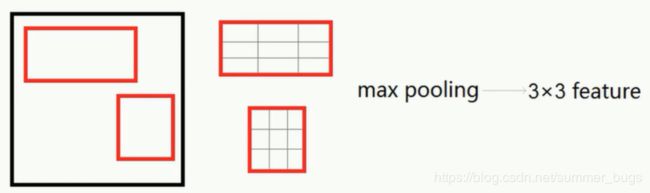
ROI Pooling
ROI-Pooling层其实是SPP-Net中金字塔池化层的一种简化形式,ROI-Pooling层只使用一种固定输出大小的max-pooling,将每个候选区域均匀分成 MxN块,对每块进行max-pooling,将特征图上大小不一的候选区域转变为统一大小的数据,送入下一层
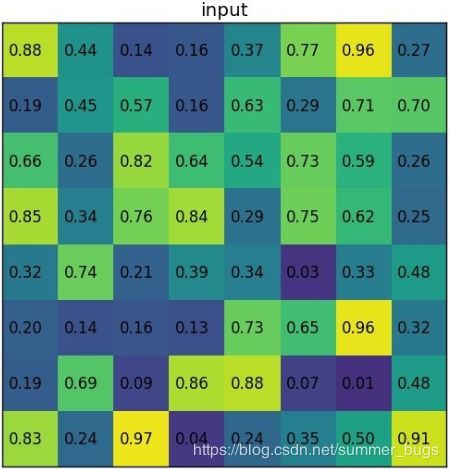
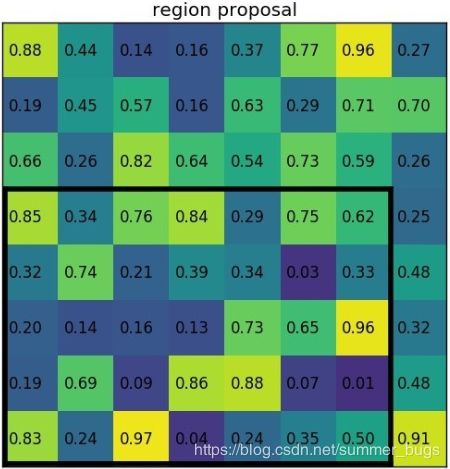
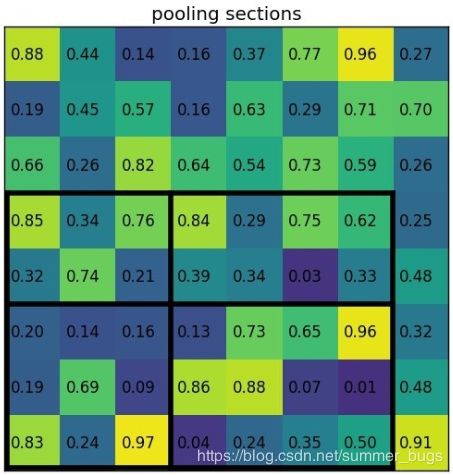
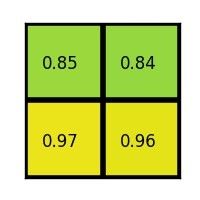
Fast-RCNN把bbox regression放进了神经网络内部,与Region分类合并成为了一个multi-task模型,这两个任务能够共享卷积特征,并相互促进,这个结构的优化极大提升了模型的训练和预测速度(下图是fast-RCNN的multi-task)
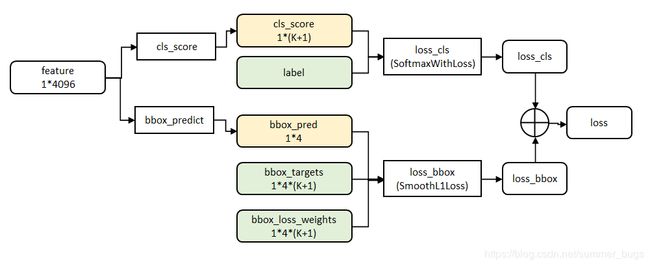
Faster-RCNN
Faster-RCNN加入了一个专门生成候选区域的神经网络,也就是说,找到候选框的工作也交给了神经网络来做了
Faster-RCNN可以简单看做“区域生成网络+Fast-RCNN”的系统,用区域生成网络代替fast-RCNN中的Selective Search方法

下图是Faster-RCNN结构图
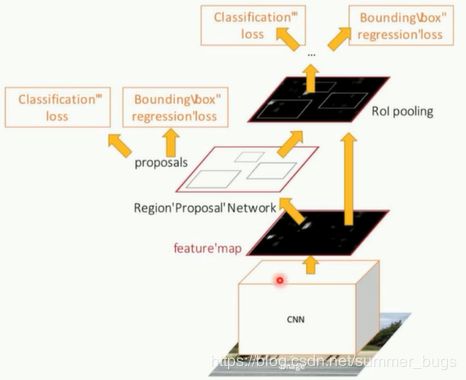
在Faster-RCNN中经过了两次分类算法,RPN中的分类算法是判断候选框内是否有物体(二分类),输出层的分类是对候选框内物体种类的分类(目标有多少类就分多少类+1)
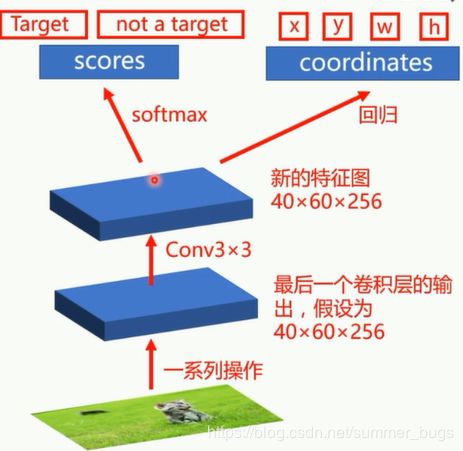
下图是Region Proposal Network(RPN)结构图
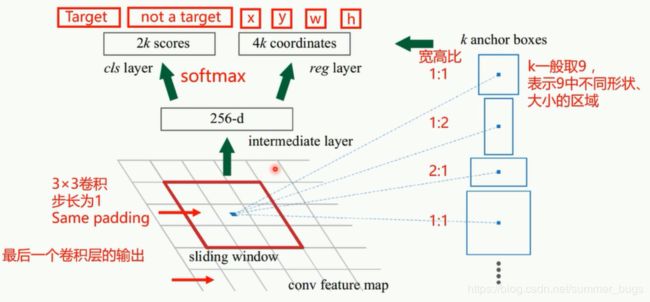
经过多次卷积-池化后的特征图上的每一点都可以映射到原图中的一片区域,然后以该区域的中点为中心生成9个候选框(大小分别是128x128 256x256 512x512)
RPN的计算流程:
- 1.最后一个卷积层输出的特征图再次进行一次卷积操作得到新的特征图
- 2.新的特征图的平面上有40x60共2400个点,每个点都可以对应到原始的图片上,得到9个候选框,所以一共可以得到40x60x9大约20000个候选区域
- 3.计算所有候选区域的scores
- 4.把所有超出图片的候选区域都限制在图片区域内,选scores最大的前12000个候选区域
Faster-RCNN-RPN的损失函数
L ( p i , t i ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L({p_i},{t_i})=\frac{1}{N_{cls}}\sum_iL_{cls}(p_i,p_i^*)+\lambda\frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^*) L(pi,ti)=Ncls1∑iLcls(pi,pi∗)+λNreg1∑ipi∗Lreg(ti,ti∗)
函数由两部分组成,一部分是目标预测的loss,一部分是回归预测的loss
考虑分类的loss:
p i p_i pi为anchor预测为目标的概率
GT标签: p i ∗ = { 0 negative label 1 positive label p_i^*=\begin{cases}0 &\text{negative label}\\1 &\text{positive label}\end{cases} pi∗={01negative labelpositive label
如果anchor为正,则GT标签 p i ∗ p_i^* pi∗为1;anchor为负,GT标签 p i ∗ p_i^* pi∗为0
L c l s ( p i , p I ∗ ) = − log [ p I ∗ p i + ( 1 − p i ∗ ) ( 1 − p i ) ] L_{cls}(p_i,p_I^*)=-\log[p_I^*p_i+(1-p_i^*)(1-p_i)] Lcls(pi,pI∗)=−log[pI∗pi+(1−pi∗)(1−pi)]
当 p i ∗ p_i^* pi∗为0时, L c l s ( p i , p i ∗ ) = − log ( 1 − p i ) L_{cls}(p_i,p_i^*)=-\log(1-p_i) Lcls(pi,pi∗)=−log(1−pi)
当 p i ∗ p_i^* pi∗为1时, L c l s ( p i , p i ∗ ) = − log ( p i ) L_{cls}(p_i,p_i^*)=-\log(p_i) Lcls(pi,pi∗)=−log(pi)
N c l s N_{cls} Ncls为Mini-Batch大小,为256
考虑回归的loss:
t i = t x , t y , t w , t h t_i={t_x,t_y,t_w,t_h} ti=tx,ty,tw,th,表示bounding box4个坐标参数
t i ∗ t_i^* ti∗是与positive anchor对应的ground truth的4个坐标参数
当 p i ∗ p_i^* pi∗为0时,回归的loss为0
当 p i ∗ p_i^* pi∗为1时,才需要考虑回归loss: L r e g ( t i , t i ∗ ) = R ( t i − t i ∗ ) L_{reg}(t_i,t_i^*)=R(t_i-t_i^*) Lreg(ti,ti∗)=R(ti−ti∗)
R为 s m o o t h L 1 ( x ) = { 0.5 x 2 if |x|<1 ∣ x ∣ − 0.5 otherwise smooth_{L_1}(x)=\begin{cases}0.5x^2& \text{if |x|<1}\\|x|-0.5& \text{otherwise}\end{cases} smoothL1(x)={0.5x2∣x∣−0.5if |x|<1otherwise
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a , t w = log ( w / w a ) , t h = log ( h / h a ) t_x=(x-x_a)/w_a,t_y=(y-y_a)/h_a,t_w=\log(w/w_a),t_h=\log(h/h_a) tx=(x−xa)/wa,ty=(y−ya)/ha,tw=log(w/wa),th=log(h/ha)
t x ∗ = ( x ∗ − x a ) / w a , t y ∗ = ( y ∗ − y a ) / h a , t w ∗ = log ( w ∗ / w a ) , t h ∗ = log ( h ∗ / h a ) t_x^*=(x^*-x_a)/w_a,t_y^*=(y^*-y_a)/h_a,t_w^*=\log(w^*/w_a),t_h^*=\log(h^*/h_a) tx∗=(x∗−xa)/wa,ty∗=(y∗−ya)/ha,tw∗=log(w∗/wa),th∗=log(h∗/ha)
x,y,w,h是预测框中心的(x,y)坐标,宽,高
x a , y a , w a , h a x_a,y_a,w_a,h_a xa,ya,wa,ha是anchor box中心的(x,y)坐标,宽,高
x ∗ , y ∗ , w ∗ , h ∗ x^*,y^*,w^*,h^* x∗,y∗,w∗,h∗是真实标注框中心的(x,y)坐标,宽,高
λ \lambda λ是回归权重,论文中设置为10, N r e g N_{reg} Nreg为anchor位置的数量,约等于40*60=2400
Faster-RCNN的训练流程
- 1.用ImageNet模型初始化,独立训练一个RPN网络
- 2.仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的Proposal作为输入,训练一个Faster-RCNN网络
- 3.使用第二步的Fast-RCNN网络参数初始化一个新的RPN2网络,但是把RPN2、Faster-RCNN共享的哪些卷积层的learning rate设置为0,也就是不断更新,仅仅更新RPN2特有的哪些网络层,重新训练
- 4.仍然固定RPN2、Faster-RCNN共享的那些网络层,把Faster-RCNN特有的网络层也加入进来,形成一个统一的网络,继续训练,fine tune Fast-RCNN特有的网络层
目标检测的one-stage & two-stage
Two-stage:Faster-RCNN
Two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(Region proposal),然后对候选区域分类(一般还需要精修)
特点是:错误率低,漏识别率也较低,但是速度较慢,不太能满足实时检测场景
One-stage:SSD,YOLO
One-stage不需要Region proposal阶段,可以直接产生物体的类别概率和位置坐标值,经过单词检测即可直接得到最终的检测结果
特点:速度更快
SSD(Single shot multibox detector)
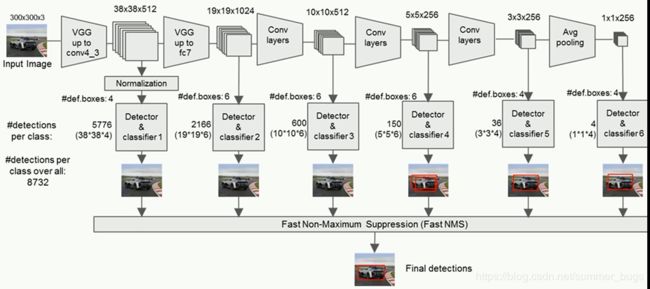
特征金字塔

上图左边的方法针对输入的图片获取不同尺度的特征映射,但是在预测阶段仅仅使用了最后一层的特征映射,而SSD不仅获得不同尺度的特征映射,同时在不同的特征映射上进行预测,它在增加运算量的同时可能会提高检测的精度,因为它考虑了更多尺度的特征
不同的卷积层会输出不同大小的特征图(这是由于Pooling层的存在,它会将图片尺寸变小)而不同的特征图中包含有不同的特征,而不同特征可能对我们的检测有不同的作用,总的来说,浅卷积层可以得到物体边缘的信息,而深层网络可以得到更抽象的特征
YOLO (You Only Look Once)
YOLO V1
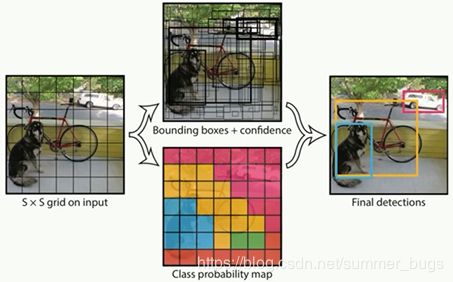
YOLO V1的核心思想就是利用整张图作为网络的输入,将目标检测作为回归问题解决,直接在输出层回归预选框的位置及其所属的类别
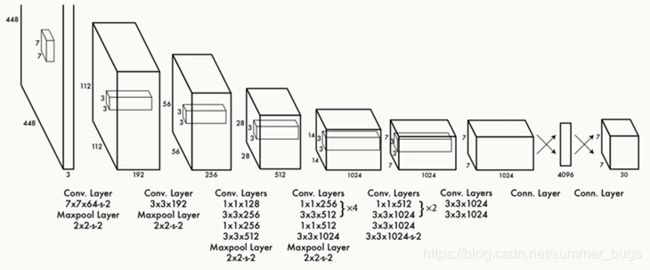
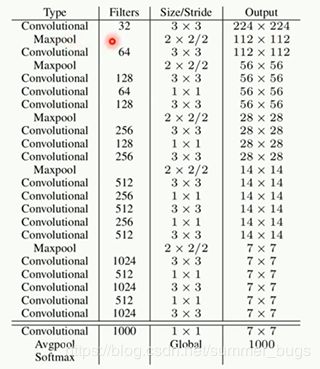
YOLO最左边是一个InceptionV1网络,共20层(作者做了相应改进,用一个1x1卷积并联一个3x3卷积来代替)
InceptionV1提取出的特征图再经过4个卷积层和2个全连接层,最后生成7x7x30的输出
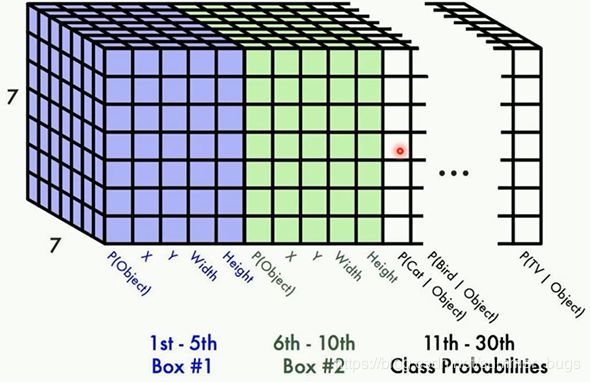
解释为什么是7x7x30的输出:
YOLO将一副448x448的原图分割成了7x7=49个网格,每个网格要预测两个bounding box的坐标(x,y,w,h)和box内是否包含物体的置信度confidence(每个bounding box有一个confidence),以及物体属于20类别(以VOC数据集为例)中每一类的概率,所以一个网格对应一个(4x2+2+20)=30维的向量(4x2表示两个bbox的参数,2表示2个置信度,20表示分类数量)
下图是输出的结构图
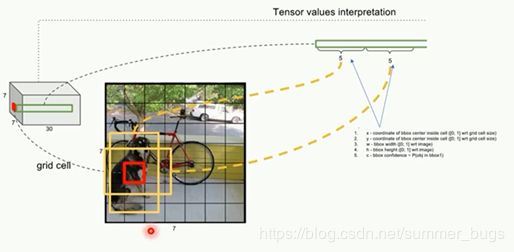
下图中,7x7网格内的每个小网格(红色网格),对应两个大小形状不同的bbox(黄色框),每个box的位置坐标为(x,y,w,h),x,y表示box中心点与该格子边界的相对值,w,h表示预测box的宽度和高度相对于整幅图像的宽度和高度的比例
(x,y,w,h)会限制在[0,1]之间,与训练数据集上标定的物体真实坐标(Gx,Gy,Gw,Gh)进行对比训练,每个小网格负责检查中心点落在该格子的物体
这个置信度只是为了表达box内有无物体的概率(类似于Faster RCNN中RPN层的softmax预测anchor是前景还是背景的概率),并不预测box内物体属于哪一类
confidence置信度
P r ( O b j e c t ) ∗ I o U p r e d t r u t h Pr(Object)*IoU_{pred}^{truth} Pr(Object)∗IoUpredtruth
其中前一项表示有无人工标记的物体落入了网格内,如果有则为1,否则为0,第二项表示bbox和真实标记的box之间的IoU,值越大,则box越接近真实位置
confidence是针对bounding box的,每个网格有两个bbox,所以每个网格会有两个置信度与之对应
YOLO-V1预测工作流程
-
1.每个格子得到两个bbox
-
2.每个网格预测的class信息和bbox预测的confidence信息相乘,得到了每个bbox预测具体物体的概率和位置重叠的概率PrIoU
P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I o U p r e d t r u t h = P r ( C l a s s i ) ∗ I o U p r e d t r u t h Pr(Class_i|Object)*Pr(Object)*IoU_{pred}^{truth}=Pr(Class_i)*IoU_{pred}^{truth} Pr(Classi∣Object)∗Pr(Object)∗IoUpredtruth=Pr(Classi)∗IoUpredtruth
-
3.对于每个类别,对PrIoU进行排序,去除小于与之的PrIoU,然后做非极大值抑制
YOLO-V1的代价函数
YOLOV1的代价函数包含三部分:位置误差,confidence误差,分类误差
YOLO-V1的缺点
- 1.每个网格只对应两个bbox,当物体的长宽比不常见(也就是训练数据覆盖不到时),效果较差
- 2.原始图片只划分为7x7的网格,当两个物体靠的很近时,效果较差
- 3.最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)
- 4.对于图片中比较小的物体,效果比较差(这其实是所有目标检测算法的通病,SSD对这个问题有一些优化)
YOLO-V2
DarkNet-19结构图
YOLO-V2的精确度优化:
-
1.High Resolution Classifier
YOLO-V2首先修改预训练分类网络的分别率为448x448,在ImageNet上训练10个周期,这个过程让网络有足够的时间去适应高分辨率的输入,然后在fine tune为检测网络
-
2.Convolutional With Anchor Boxes
YOLO-V1使用全连接层进行bbox预测,这会丢失较多的空间信息,导致定位不准
YOLO-V2借鉴了Faster RCNN中的anchor思想:卷积特征图上进行滑动窗口采样,每个中心预测9种不同大小和比例的anchor。总的来说,就是==移除全连接层(以获得更多的空间信息)使用anchor boxes去预测bbox,并且,YOLO-V2由anchor box同时预测类别和坐标==
Convolutional With Anchor Boxes的具体做法:
- 去掉最后的池化层确保输出的卷积特征图有更高的分辨率
- 缩减网络,让图片输入分辨率为416x416,目的是让后面产生的卷积特征图宽,高都为技术,这样就可以产生一个center cell(中心点),因为大物体通常占据了图像的中间位置,可以只用一个中心的cell来检测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可以稍微提升效率
- 使用卷积层降采样(factor=32),使得输入卷积网络的416x416图片最终得到13x13的卷积特征图(416/32=13)
- 由anchor box同时预测类别和坐标,因为YOLO是由每个cell来负责预测类别,每个cell对应的2个bounding box负责预测坐标,YOLO-V2中,不再让类别的预测与每个cell(空间位置)绑定一起,而是全部放到anchor box中
-
3.Dimension Clusters(维度聚类)
在使用anchor时,Faster-RCNN中的anchor boxes的个数和宽,高维度往往是手动精选的先验框(hand-picked priors),如果能够一开始就选择了更好的,更有代表性的先验框维度,那么网络就应该更容易学到准确的预测位置
YOLO-V2中利用K-means聚类方法,通过对数据几种的Ground Truth box做聚类,找到Ground Truth box的统计规律,以聚类个数k为anchor boxes个数,以聚类中心框的宽和高为anchor box的宽和高
-
4.Direct location prediction(直接位置预测)
使用anchor boxes的另一个问题是模型不稳定,尤其是在早期迭代的时候,大部分的不稳定现象出现在预测框的(x,y)坐标时,YOLO-V2没有用Faster-RCNN的预测方式
YOLO-V2位置预测值 t x , t y t_x,t_y tx,ty就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看作是1)
-
5.Fine-Grained Features(细粒度特征)
SSD通过不同大小的特征图结合预测框来实现多尺度,而YOLO-V2则采用了另一种思路,添加一个passthrough layer,来获取之前的26x26x512的特征图特征,对于26x26x512的特征图,经过pass through layer后就变成了13x13x2048的新特征图(新特征图大小降低4被,而通道数增加4被),这样就可以与后面的13x13x1024特征图连接在一起,形成13x13x3072大小的特征图,然后在此特征图基础上卷积做预测
YOLO-V2的检测器使用的就是经过扩展后的特征图,他可以使用细粒度特征

-
6.Multi-Scale Training(多尺度训练)
原始YOLO网络使用固定的448x448的图片作为输入,加入anchor boxes后输入变成416x416,由于网络只用刀了卷积层和池化层,就可以进行动态调整(检测任意大小的图片),为了让YOLO-V2对不同尺寸图片具有鲁棒性,不同于固定网络输入图片尺寸的方法,没经过10批次(10 batches)就会随机选择新的图片尺寸,网络使用的降采样参数为32,于是使用32的倍数,最小的尺寸为320x320,最大尺寸为608x608,调整网络到相应维度,然后继续进行训练,这种机制使得网络可以更好的预测不同尺寸的图片,同一个网络可以进行不同分辨率的检测任务
YOLO-V3
YOLO-V3的基础框架为DarkNet-53

YOLO-V3结构图如下

YOLO-V3先验框
YOLO-V3有3个不同特征尺度的输出,分别是13x13x255,26x26x255,52x52x255
YOLO-V2已经开始采用K-means聚类得到先验框的尺寸,YOLO-V3延续了这种方法,为每种下采样尺度设定3中先验框,总共聚类出9中尺寸的先验框
分配上,在最小的13x13特征图上(有最大的感受野)应用较大的先验框,是和检测较大的对象,中等的26x26特征图上(中等感受野),应用中等的先验框,较大的52x52特征图(较小感受野)应用较小的先验框,适合检测较小对象
| 特征图 | 13x13 | 26x26 | 52x52 |
|---|---|---|---|
| 感受野 | 大 | 中 | 小 |
| 先验框 | (116x90),(156x198),(373x326) | (30x61),(62x45),(59x119) | (10x13),(16x30),(33x23) |