oracle分区表中本地索引和全局索引的适用场景
oracle分区表中本地索引和全局索引的适用场景
转自:本地索引和全局索引的适用场景
背景
分区表创建好了之后,如果需要最大化分区表的性能就需要结合索引的使用,分区表有两种索引:本地索引和全局索引。既然存在着两种的索引类型,相信存在即合理。既然存在就会有存在的原因,也就是在特定的场景中就更能发挥出索引的性能的;
本文档通过测试,总结出两种索引的适合的场景;
测试环境
数据库版本:11.2.0.3
分区表的创建脚本:
CREATE TABLE SCOTT.PTB
(
GG1DM VARCHAR2(9 BYTE),
SL NUMBER(18,4) ,
DJBH VARCHAR2(20 BYTE)
)
NOCOMPRESS
PARTITION BY LIST (GG1DM)
(
PARTITION PTABLE_P1 VALUES ('07'),
PARTITION PTABLE_P2 VALUES ('08'),
PARTITION PTABLE_P3 VALUES ('09')
)然后插入大量的数据,再进行统计信息的更新;
select t3.table_name,
t3.partition_name,
t3.high_value,
t3.num_rows,
t3.blocks,
t3.empty_blocks,
t3.last_analyzed
from dba_tab_partitions t3
where t3.table_name='PTABLE'
order by t3.num_rows desc;开始测试
测试一、跨分区的数据查询
1.1 创建本地索引(注意:该列不是分区的列)
SQL> CREATE INDEX SCOTT.IN_PTB ON SCOTT.PTB
(DJBH)
LOGGING
LOCAL (
PARTITION PTABLE_P1
LOGGING
NOCOMPRESS ,
PARTITION PTABLE_P2
LOGGING
NOCOMPRESS ,
PARTITION PTABLE_P3
LOGGING
NOCOMPRESS
)
SQL> select Segment_NAME,PARTITION_NAME,SEGMENT_TYPE from dba_segments a where a.segment_name='IN_PTB';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
---------------- --------------------- ------------------
IN_PTB PTABLE_P1 INDEX PARTITION
IN_PTB PTABLE_P2 INDEX PARTITION
IN_PTB PTABLE_P3 INDEX PARTITIONLOCAL索引会在每个分区上面单独创建INDEX PARTITION,类似于三个子索引;
进行执行计划的查看
SQL> select count(1) from scott.ptb where djbh='R23NAA002138250';
COUNT(1)
----------
512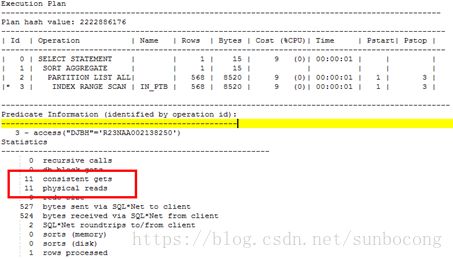
1.2 创建全局索引,原先的索引先drop(注意:该列不是分区的列)
SQL> CREATE INDEX SCOTT.IN_PTB_L ON SCOTT.PTB
(DJBH)
NOLOGGING
STORAGE (
BUFFER_POOL DEFAULT
FLASH_CACHE DEFAULT
CELL_FLASH_CACHE DEFAULT
)
NOPARALLEL;
SQL> select Segment_NAME,PARTITION_NAME,SEGMENT_TYPE from dba_segments a where a.segment_name='IN_PTB_L';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------- --------------------- --------------------
IN_PTB_L INDEX进行执行计划的查看
需要先刷新buffer:
alter system flush buffer_cache;
select count(1) from scott.ptb where djbh='R23NAA002138250';
测试一总结:
以上那种情况因为djbh这一列是需要跨分区的,当查询的条件是需要跨分区查询内容的时候,LOCAL INDEX的效率比GLOBAL INDEX的效率要低,通过consistent gets和db block gets的对比可以看出来;
测试二、分区内部的查询
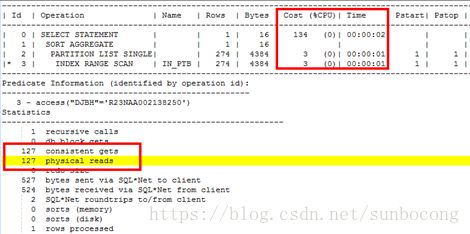
2.1 分区内使用本地索引
alter system flush buffer_cache;
select count(1) from scott.ptb where djbh='R23NAA002138250' and GG1DM='07'; #该条件可以确定在单个分区里面
2.2 分区内使用全局索引
alter system flush buffer_cache;
select /*+ index(PTB IN_PTB_L) */ count(1) from scott.ptb where djbh='R23NAA002138250' and GG1DM='07';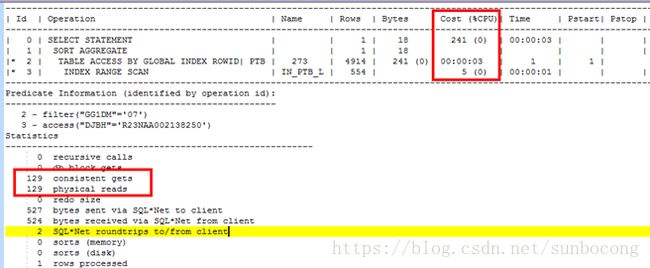
测试二总结:
通过这组实验可以看出来如果查询的条件是在单个分区里面查询的时候,那么LOCAL INDEX的效率比GLOBAL INDEX的效率要高。
总结
经过以上的测试可以发现全局索引和本地索引的使用效率跟查询条件有直接的影响,创建索引的时候需要根据业务的使用场景进行创建;
而分区表的创建也是受使用场景所影响的,所以在创建分区表和分区索引的时候都需要事先了解业务的需求,尽量把业务需要统计的信息放在一个同一个分区。这样使分区表的性能实现最大化;