《High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs》论文笔记
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
解决问题:用CGAN合成分辨率为2048*1024的高分辨率且纹理逼真的图像。
方法:1、coarse-to-fine 生成器(G1(全局生成器)![]() 、G2(局部增强生成器)
、G2(局部增强生成器)![]() )
)
2、multi-scale 判别器(![]() 、
、![]() 、
、![]() )
)
3、除了对抗损失和感知损失加入了feature matching loss
4、除了segmantic label map 加入了instance map(相同类的不同对象相邻时无法区分)
结果:1、分辨率为2048*1024
2、可在原始标签map中改变标签(如将建筑替换成树木)
3、允许用户编辑单个对象的外观(如:汽车外观和路面纹理)
4、更为逼真的纹理和细节
5、同样的label map输入可以得到多样性的结果
概念:1、使用语义分割方法,可以将图像转换到语义标签域,在标签域中编辑对象,然后转换回图像域。
方法:
- 网络结构和目标函数:
Coarse-to-fine generator:
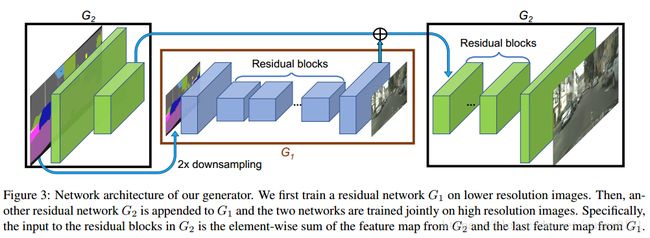
![]() 网络执行的分辨率为1024*512,
网络执行的分辨率为1024*512,![]() 执行的分辨率是
执行的分辨率是![]() 的4倍,若要得到更高的分辨率可以额外增加一个局部增强生成器,同样是之前的4倍(纹理特征是否跟上?)。
的4倍,若要得到更高的分辨率可以额外增加一个局部增强生成器,同样是之前的4倍(纹理特征是否跟上?)。
![]() 的输入是1024*512的语义标签map,通过
的输入是1024*512的语义标签map,通过![]() (包含:一个卷积front-end、一系列残差块和一个反卷积back-end)得到分辨率为1024*512的图像。
(包含:一个卷积front-end、一系列残差块和一个反卷积back-end)得到分辨率为1024*512的图像。
G2的输入为两个特征maps的元素级和:![]() 的输出特征map、G1
的输出特征map、G1![]() 网络中back-end的最后一个特征map。这有助于整合
网络中back-end的最后一个特征map。这有助于整合![]() 到
到![]() 的全局信息。
的全局信息。
Multi-scale discriminator
由![]() 三个判别器组成。具体来说,就是对真实和合成的高分辨率图片执行2和4倍下采样得到一个3scales的图像金字塔。在coarset scale的图像有最大的接受域,能知道生成器生成全局一致的内容。在finest scale的图像激励生成器产生finer细节。
三个判别器组成。具体来说,就是对真实和合成的高分辨率图片执行2和4倍下采样得到一个3scales的图像金字塔。在coarset scale的图像有最大的接受域,能知道生成器生成全局一致的内容。在finest scale的图像激励生成器产生finer细节。
Improved adversarial loss
GAN loss中加入了feature matching loss,可以稳定训练。
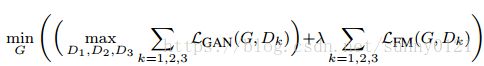 ,其中
,其中 ,λ
,λ![]() 控制两项的重要程度。而最终的损失函数中还加入了感知损失。
控制两项的重要程度。而最终的损失函数中还加入了感知损失。
- Instance Maps
为了进一步提升生成图像的质量,首先计算了instance boundary map,然后和语义标签map的one-hot向量表示进行级联输入到生成器中。效果如下:

- Learing an Instance-level Feature embedding
为了生成多样性的图片并且允许实例级控制,论文提出了在生成器的输入中添加一个低维度的特征通道。
为生成低维特征,用一个编码器E找到一个和图片中每个instance相关的ground truth 特征向量。为了保证特征和每个instance一致,对E的输出添加了一个instance-wise 平均池化层。然后将平均特征广播到实例的所有像素位置(什么意思?)。

实验结果分析:
4.1 定量结果比较
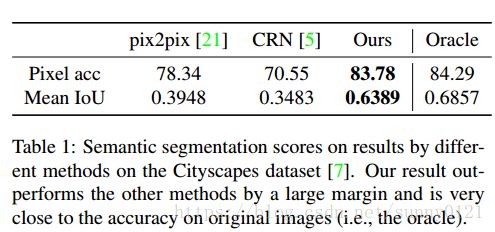
论文在这节的实验当中比较的是对预测的模型和输入图像进行语义分割,分析其分割匹配度。(IoU:这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高)
4.2 human perceptual study
论文在这节实验中论证了所提出的新的网络结构和新的对抗损失要明显优于当前最优的网络模型,并验证了提出方案中的组成部分(coarse-to-fine G、multi-scale D、feature matching loss and instance map)的不可或缺性,以及在加入了感知损失函数后进一步提升了图像的质量。在除了城市街景数据上的实验,还在NYU数据集上进行了对比实验,结果也很明显的要好,证明了所提出的方案的泛化性能。

4.3 交互式对象编辑
论文中实验了特征编码器,从而允许用户在结果图像中执行交互式instance 编辑。比如说改变图像中的对象标签(如用树代替建筑)从而快速改变场景,也可以改变单独汽车的颜色或者路面的纹理。除此之外,类似的操作同样适用于人脸。以及对于同样的语义标签map输入,可以得到不同的多样化结果

