Python爬虫-Scrapy框架(四)- 内置爬虫文件 - 4.3 使用正则表达式提取链接
Python爬虫-Scrapy框架(四)- 内置爬虫文件 - 4.3 使用正则表达式提取链接
- 写在前面
- 使用正则表达式提取链接
- 筛选链接
- 设置Rules匹配规则
- 完成回调函数
- 当前项目存档
写在前面
之前提到Crawl Spider适用于爬取路由有规则的网站,并且大致了解了Crawl Spider的运行机制,在这里通过实例学习Rules的匹配机制以及回调函数的设置方法。
使用正则表达式提取链接
筛选链接
为何刻意说明Crawl Spider适用于爬取路由有规则的网站呢?这是因为在Rules规则中我们可以很方便的使用正则表达式匹配获取到的路由,也就是链接,如果匹配成功了,就去调用设置的函数。
首先我们尝试从start_urls中提取想要的所有链接。
回到我的CSDN主页,https://blog.csdn.net/sunzhihao_future ,现在一共发布了六篇博客文章,现在想要做的事情就是从主页中提取出这六篇文章的链接。
毫无疑问,我们将项目中的start_urls设置为“ https://blog.csdn.net/sunzhihao_future ”。
接下来打开任意一篇文章,观察其地址。

不难发现,整个地址由“ https://blog.csdn.net/sunzhihao_future/article/details/ ”前半部分以及一串数字组成,打开另一篇文章,同样如此。结合正则表达式的内容,我们编写如下正则表达式来表示这一类引向文章的链接。
https://blog.csdn.net/sunzhihao_future/article/details/\d+
在正则表达式中,\d+表示一串数字,其中数字的位数不限。
现在打开Terminal终端,来测试此正则表达式是否能匹配出所有我们需要的链接。
C:\Users\Lenovo\Desktop\search_scrapy>scrapy shell https://blog.csdn.net/sunzhihao_future
In [1]: from scrapy.linkextractors import LinkExtractorIn [2]: get_links = LinkExtractor(r’https://blog.csdn.net/sunzhihao_future/article/details/\d+’)
In [3]: get_links.extract_links(response)
Out[3]:
[Link(url=‘https://blog.csdn.net/sunzhihao_future/article/details/89363076’, text=’\n \n 原 \n Python爬虫-Scrapy框架(四)- 内置爬虫文件 - 4.2 初探Crawl Spider ‘, fragment=’’, nofollow=False),
Link(url=‘https://blog.csdn.net/sunzhihao_future/article/details/89313034’, text=’\n \n 原 \n Python爬虫-Scrapy框架(四)- 内置爬虫文件 - 4.1 访问二级链接 ‘, fragment=’’, nofollow=False),
Link(url=‘https://blog.csdn.net/sunzhihao_future/article/details/88699878’, text=’\n \n 原 \n Python爬虫-Scrapy框架(三)- 爬虫数据入库 ‘, fragment=’’, nofollow=False),
Link(url=‘https://blog.csdn.net/sunzhihao_future/article/details/88643984’, text=’\n \n 原 \n Python爬虫-Scrapy框架(二)- 交互式命令模式 ‘, fragment=’’, nofollow=False),
Link(url=‘https://blog.csdn.net/sunzhihao_future/article/details/88594715’, text=’\n \n 原 \n Python爬虫-Scrapy框架(一)- Scrapy环境安装 ‘, fragment=’’, nofollow=False),
Link(url=‘https://blog.csdn.net/sunzhihao_future/article/details/88587220’, text=’\n \n 原 \n Python爬虫-Scrapy框架(序篇) ‘, fragment=’’, nofollow=False)]
首先利用shell命令进入到交互模式,然后引入LinkExtractor,通过正则表达式对response中的所有链接进行匹配,最终发现成功提取到了我们需要的这六篇文章的链接,这证明之前编写的正则表达式是有效的。
设置Rules匹配规则
关闭终端,进入到search_crawl.py文件中,设置rules规则,将正则表达式填入。
rules = (
Rule(LinkExtractor(allow=r'https://blog.csdn.net/sunzhihao_future/article/details/\d+'), callback='parse_item', follow=False),
)
这里将follow的值改为了False,暂时不做解释。
完成回调函数
通过正则表达式匹配的链接将会扔回回调函数,也就是parse_item中,进行下一步的操作处理。
这里我们提取每篇文章的标题以及发布时间。
想要提取元素,当然是使用其XPath来搜索,最一开始我们只是很机械的复制了某一个元素的XPath路径,然后再去搜索它,现在我们运用标签加类名的办法去确定某一类元素的XPath,之所以可以采用这种方法,是因为在一个网站中,同一类页面的架构是大致相同的,同一类元素所处的标签和类名也应该是相同的。
打开开发者模式,运用之前介绍的选择工具,定位到标题以及发布时间,获得其所在的位置。
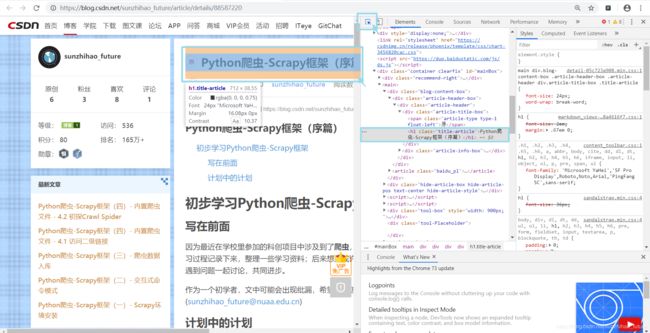
这里显示文章的标题位于h1标签下,类名为title-article,则我们可以采用如下XPath搜索到这个元素。
//h1[@class=“title-article”]
h1的位置为标签名,title_article的位置为类名
同样的方法获得发布时间所处的标签和类名,并且确定其XPath。
回到parse_item函数中,结合我们之前获取元素的方法,代码如下。
def parse_item(self, response):
i = {}
i['title'] = response.xpath('//h1[@class="title-article"]/text()').extract()
i['time'] = response.xpath('//span[@class="time"]/text()').extract()
print(i)
打开Terminal终端,执行该爬虫。这里追加 “–log” 命令,表示不打印日志。
C:\Users\Lenovo\Desktop\search_scrapy>scrapy crawl search_crawl --nolog
{‘title’: [‘Python爬虫-Scrapy框架(序篇)’], ‘time’: [‘2019年03月16日 11:27:00’]}
{‘title’: [‘Python爬虫-Scrapy框架(一)- Scrapy环境安装’], ‘time’: [‘2019年03月17日 23:15:02’]}
{‘title’: [‘Python爬虫-Scrapy框架(二)- 交互式命令模式’], ‘time’: [‘2019年03月20日 20:13:30’]}
{‘title’: [‘Python爬虫-Scrapy框架(三)- 爬虫数据入库’], ‘time’: [‘2019年04月15日 12:20:24’]}
{‘title’: [‘Python爬虫-Scrapy框架(四)- 内置爬虫文件 - 4.1 访问二级链接’], ‘time’: [‘2019年04月17日 19:10:15’]}
{‘title’: [‘Python爬虫-Scrapy框架(四)- 内置爬虫文件 - 4.2 初探Crawl Spider’], ‘time’: [‘2019年04月22日 12:40:03’]}
数据提取成功,到这里,我们完成了通过正则表达式筛选链接,并且进入各个筛选到的链接提取数据的任务。
当前项目存档
进行到这里的整个项目文件已经上传至我的百度网盘,如有需要可以自行下载。
版本:search_scrapy_v4.3
链接:https://pan.baidu.com/s/1RJmx-2LoOrRwP7Ptep2xcQ
提取码:ms4v