第一篇 从PyTorch到FastAI
一、使用PyTorch的ResNet18网络,在MNIST数据集上实现手写数字的分类
MNIST数据集下载地址。数据读取代码如下:
import pickle, gzip
import numpy as np
def load_data(data_pkl):
with gzip.open(data_pkl, "rb") as fp:
training_data, valid_data, test_data = pickle.load(fp, encoding="latin-1")
return training_data, valid_data, test_data
training_data, valid_data, test_data = load_data(data_pkl)
x_train, y_train = training_data
x_valid, y_valid = valid_data
x_test, y_test = test_data
所得到的数据为numpy的数组格式。其中每张图像为28x28大小的单通道数据,被扯成了一维向量。训练集、验证集、测试集各有50000、10000、10000条数据。

1. 定义数据集(Dataset)及数据加载器(Dataloader)
对于MNIST数据,PyTorch库中有两种方式比较适合将之整理为网络所需形式,一种是直接继承Dataset对象,并实现__len__()(返回数据集大小)和__getitem__()(实现数据集索引功能)函数;另一种是将数据整理为TensorDataset的形式。
(1) Dataset
from torch.utils.data import Dataset
import torch
# ImageNet的图像统计参数(RGB三通道的均值和方差)
stats = [np.array([0.485, 0.456, 0.406]).reshape(3,1,1),
np.array([0.229, 0.224, 0.225]).reshape(3,1,1)]
class MnistDataset(Dataset):
def __init__(self, x, y):
super().__init__()
x_temp = x.reshape(-1, 28, 28)
self.x = (np.stack((x_temp,)*3, 1)-stats[0])/stats[1]
self.x = self.x.astype("float32")
self.y = y
def __len__(self):
return len(self.y)
def __getitem__(self, index):
return self.x[index, :], self.y[index]
train_ds = MnistDataset(x_train, y_train)
valid_ds = MnistDataset(x_valid, y_valid)
test_ds = MnistDataset(x_test, y_test)
对于图像数据而言,__getitem__()返回的x需要为C x H x W的形式。
(2) TensorDataset
from torch.utils.data import TensorDataset
def get_tensor_ds(ds):
temp = np.stack((ds,)*3, 1)
temp = temp.reshape(-1,3,28,28)
temp = (temp - stats[0])/stats[1]
return torch.from_numpy( temp )
train_ds = TensorDataset(get_tensor_ds(x_train), torch.from_numpy(y_train))
valid_ds = TensorDataset(get_tensor_ds(x_valid), torch.from_numpy(y_valid))
test_ds = TensorDataset(get_tensor_ds(x_test), torch.from_numpy(y_test))
对图像数据而言,TensorDataset所需的图像数据为NxCxHxW的形式。
数据迭代器
from torch.utils.data import DataLoader
train_dl = DataLoader(train_ds, batch_size=64, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size=64, shuffle=False)
test_dl = DataLoader(valid_ds, batch_size=32)
2. 使用预训练的ResNet18网络
from torch import nn
from torchvision import models
net = models.resnet18(pretrained=True)
def set_parameter_requires_grad(model, feature_extrating):
if feature_extrating:
for param in model.parameters():
param.requires_grad = False
# 冻结预训练模型的参数
set_parameter_requires_grad(net, True)
# ResNet会降采样32倍,对于28x28的网络,经过卷积层后的特征图就变成1x1大小的,因此不需要使用池化层进行进一步的下采样了。
class Identy(nn.Module):
def forward(self, input):
return input
net.avgpool = Identy()
# 输出类别为10类
prev_fc = net.fc
net.fc = nn.Linear(in_features=prev_fc.in_features, out_features=10)
3. 损失函数和优化器
对于多分类问题,选择交叉熵损失函数
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
4. 训练流程控制
可参考PyTorch Tutorial中的迁移学习的训练过程train_model()(链接)。
如果仅更新最后一层全连接层的参数,则在测试集上可得到约72%的准确率。若使用迁移学习方法,在进行微调参数后,可得到约99%的准确率。
二、使用Fast.AI
1. 定义数据集(DataBunch)
首先下载数据
from fastai.vision import *
mnist = untar_data(URLs.MNIST)
其中所需要的函数untar_data定义如下:
untar_data(url, fname=None, dest=None, data=True, force_download=False) -> pathlib.Path
该函数从url指示的网址下载数据,并解压文件。可通过可选参数fname和dest指定保存路径。
下载的数据的目录结构如下:
~/.fastai/data/mnist_png/
training/
0/ 1/ ... 9/
总计60000张单通道图片
test/
0/ 1/ ... 9/
总计10000张单通道图片
然后将之整理为Fast AI的学习器所需的DataBunch对象(其实就是封装了训练集、验证集、测试集的数据迭代器):
tfms = get_transforms(do_flip=False)
data = (
ImageList.from_folder(mnist/"training") # 指定训练集的文件路径
.split_by_rand_pct(0.2) # 按比例分割训练集和验证集
.label_from_folder() # 指定类别标签
.add_test_folder(mnist/"testing") # 添加测试集
.transform(tfms, size=32) # 对图像的变换,并指定图像尺寸
.databunch() # 生成databunch
.normalize(imagenet_stats) # 数据归一化
)
其中get_transforms()、imagenet_stats都是在fastai.vision中定义的。
2. 构建ResNet18网络
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
cnn_learner将DataBunch数据对象,以及网络模型进一步封装,并可自动完成模型与实际问题的适配(如在ImageNet上预训练的模型是1000类,而MNIST数据仅需定义10类),并设置优化算法、进行网络训练的过程控制、设置模型指标评估等。
上述语句中models模块来源于torchvision,其实也是在fastai.vision中引入的。cnn_learner默认使用预训练的模型。
3. 进行迁移学习
先进行一轮的学习:
learn.fit_one_cycle(3, 1e-2)
可得准确率为98.9%。
然后解冻预训练的模型,以较小的学习速率再进行训练。
learn.unfreeze()
learn.lr_find()
learn.fit_one_cycle(3, max_lr=slice(1e-6, 1e-4))
可得约99.17%的准确率。
4. 一些辅助功能
-
显示数据
data.show_batch(rows=3, figsize=(4,4))结果如下图:
 图 2. learn.show_batch( )绘图
图 2. learn.show_batch( )绘图 -
学习速率查找
learn.lr_find() learn.recorder.plot()结果如下图:
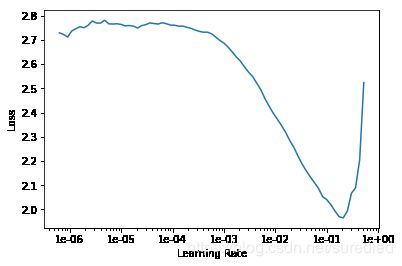 图 3. learn.recorder.plot( )绘图
图 3. learn.recorder.plot( )绘图 -
最错误的样本
interp = ClassificationInterpretation.from_learner(learn) interp.plot_top_losses(9, figsize=(7,7))结果如下图:
 图 4. interp.plot_top_loss( )绘图
图 4. interp.plot_top_loss( )绘图 -
混淆矩阵
interp.plot_confusion_matrix(figsize=(9,9), dpi=60)结果如下图:
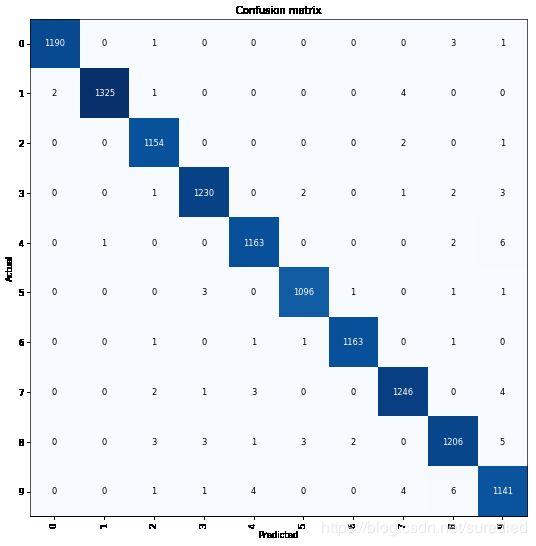 图 5. interp.plot_confusion_matrix( )绘图
图 5. interp.plot_confusion_matrix( )绘图
由上,使用Fast AI的API,将极大减少准备数据集、以及训练流程控制方面的代码。此外,Fast AI还提供了许多可用于模型性能分析的工具。本系列的后续博文将结合Fast AI的文档进行更深入的介绍。