| 这个作业属于哪个课程 | 2020春S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业——某次疫情统计可视化的实现 |
| 这个作业的目标 | 采用web技术实现原型设计的部分功能 |
| 作业正文 | 作业链接 |
| 其他参考文献 | 博客园、CSDN |
一、Github仓库地址和代码规范链接
新仓库地址
原仓库地址
代码规范
二、成品展示
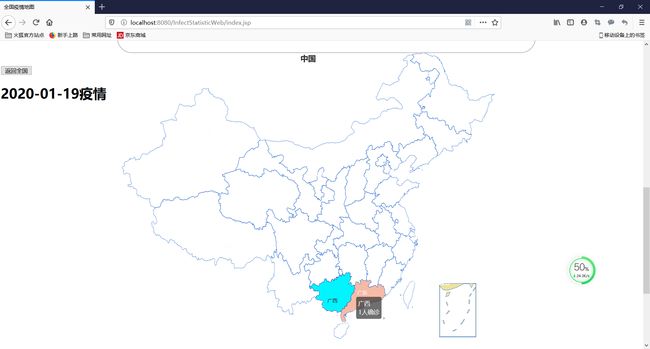
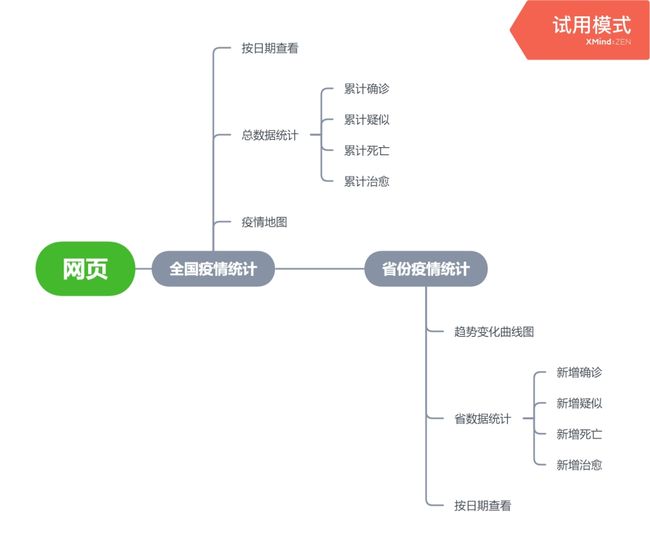
全国疫情统计情况
日期选择,下拉框显示日期列表,按日期查询
全国疫情统计总数据

疫情分布地图
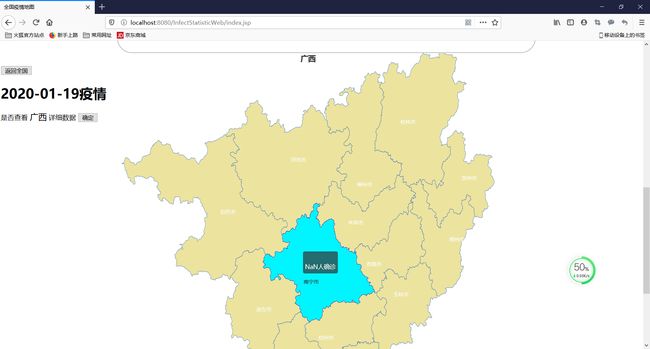
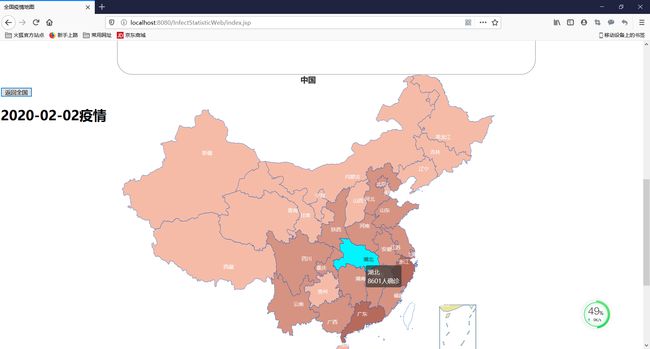
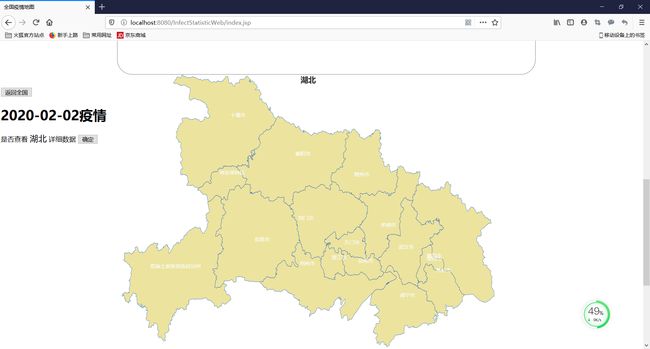
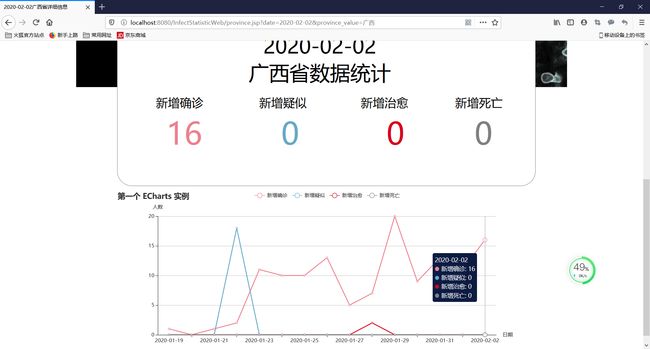
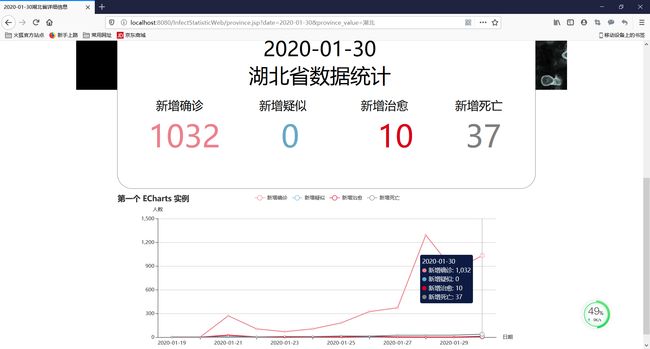
省疫情统计情况
日期选择,下拉框显示日期列表,按日期查询
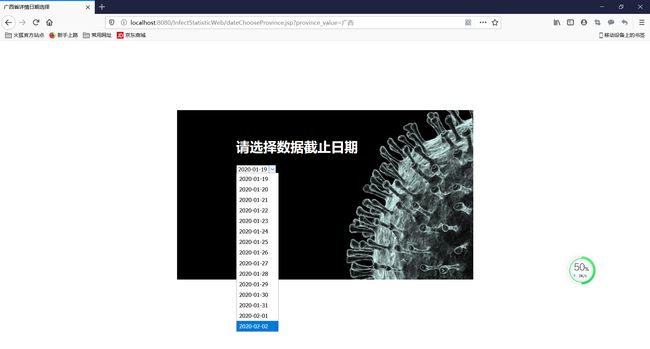
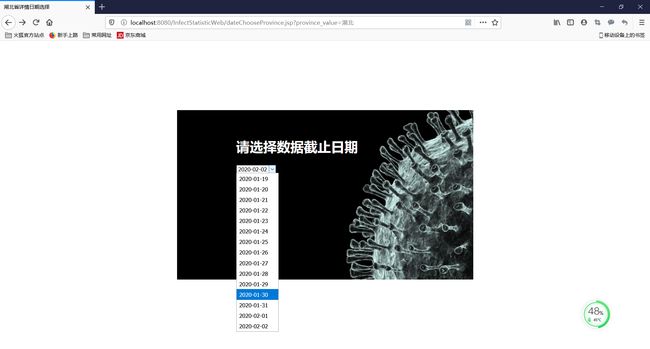
省疫情数据以及疫情趋势曲线图
三、结对过程
本次结对过程经历了一小点坎坷,由于一些些失误我们建了第二个仓库 TT
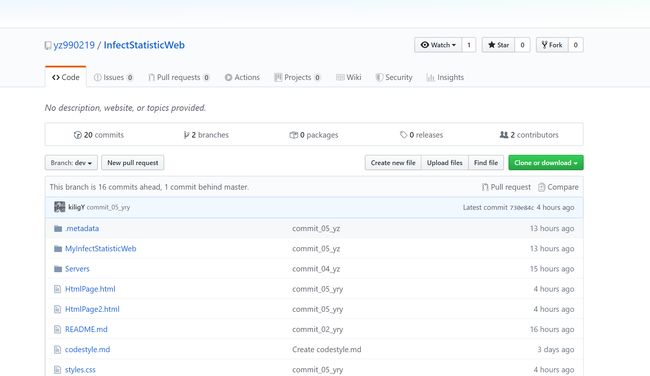
这是原仓库的commit记录
结对过程关于设计细节的一些讨论

四、设计实现过程
实现过程
-
写 html 和 css
- 作业发布之后,首先根据原型实现了前台的静态页面
-
修改后端代码
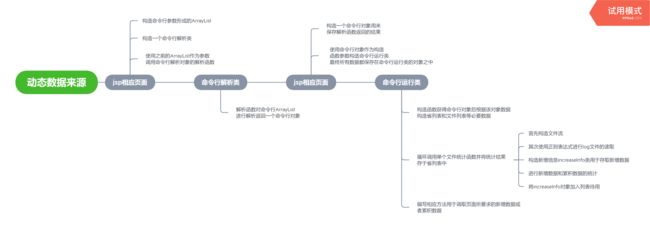
- 将之前的第二次寒假作业的多个内部类进行拆分整合成多个文件,用于数据处理,作为动态数据的来源。增加了一个IncreaseInfo类用于保存某天的全国各省新增数据并编写根据省名获取省对象的方法,在CommandLineRun类中增加一个IncreaseInfo的ArrayList用于存取每天的新增数据,编写了一个通过日期从这个ArrayList中获取对应IncreaseInfo对象的方法,最终在单个文件处理方法中构造IncreaseInfo类并加入ArrayList,至此数据的处理已经完成,只需要通过jsp的java脚本部分按照要求日期构造一个CommandLineRun对象即可从该对象获取目标数据并使用jsp的脚本将动态数据显示在网页之上
-
添加 echarts
- 使用echarts制作地图和折线图,地图参考了网上的资料,而折线图是在网上学习了简单的echarts折线图后自主完成,最终可以通过jsp脚本构造相关数据数组从而构成图表
-
最终整合
- 选择jsp作为本次作业的实现技术,将静态数据的网页作为jsp主体,使用java代码的脚本获取动态数据并显示在对应位置或者构成对应数组构成图表,页面与页面之间的数据传输则是使用表单提交相应数据,之后再于跳转页面使用jsp的java代码脚本提取则可以的到比如前一个页面选择的日期或者省份名字
功能结构图
五、代码说明
数据来源
1.首先是对之前第二次寒假作业的拆分形成了多个Java类文件此次为了每日新增信息的显示增加了一个IncreaseInfo类,包含一个全国各省列表provinceList和时间date
package hw2;
import java.util.ArrayList;
import hw2.Province;
public class IncreaseInfo {
public ArrayList provinceList ;
public String date;
public IncreaseInfo() {
String[] provinces = { "全国", "安徽", "澳门", "北京", "重庆", "福建", "甘肃", "广东", "广西", "贵州", "海南", "河北", "河南", "黑龙江",
"湖北", "湖南", "吉林", "江苏", "江西", "辽宁", "内蒙古", "宁夏", "青海", "山东", "山西", "陕西", "上海", "四川", "台湾", "天津", "西藏",
"香港", "新疆", "云南", "浙江" };
provinceList = new ArrayList();
for (int i = 0; i < provinces.length; i++) {
Province province = new Province();
province.name = provinces[i];
province.ip = 0;
province.sp = 0;
province.cure = 0;
province.dead = 0;
provinceList.add(province);
}
date = "";
}
public Province getProvince(String pname) {
for (int i = 0; i < provinceList.size(); i++) {
if (pname.equals(provinceList.get(i).name)) {
return provinceList.get(i);
}
}
System.out.println("该省不存在");
return null;
}
}
2.之后就是对单一文件的处理,使用正则表达式进行文本匹配,由于本次助教提供的TXT文档为ANSI且有空行所以使用GBK作为文件流编码并进行空行跳过判定,在正则表达式成功匹配后进行数据处理,并将处理好的新增信息对象incInfo加入ArrayList中供之后调用
public void process_data(File f) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(f), "GBK"));
String temp;
IncreaseInfo incInfo = new IncreaseInfo();
incInfo.date = f.getName().substring(0, f.getName().length()-8);
// 用于正则表达式匹配
String type_1 = "(\\W+) (新增 感染患者) (\\d+)(人)";
String type_2 = "(\\W+) (新增 疑似患者) (\\d+)(人)";
String type_3 = "(\\W+) (感染患者 流入) (\\W+) (\\d+)(人)";
String type_4 = "(\\W+) (疑似患者 流入) (\\W+) (\\d+)(人)";
String type_5 = "(\\W+) (死亡) (\\d+)(人)";
String type_6 = "(\\W+) (治愈) (\\d+)(人)";
String type_7 = "(\\W+) (疑似患者 确诊感染) (\\d+)(人)";
String type_8 = "(\\W+) (排除 疑似患者) (\\d+)(人)";
ArrayList type_list = new ArrayList();
type_list.add(type_1);
type_list.add(type_2);
type_list.add(type_3);
type_list.add(type_4);
type_list.add(type_5);
type_list.add(type_6);
type_list.add(type_7);
type_list.add(type_8);
// 进行数据读取并匹配,最后进行统计
while ((temp = reader.readLine()) != null) {
//空行判定
if (temp.isEmpty()) {
continue;
}
//注释信息判定
if (temp.charAt(0) == '/') {
continue;
}
// 用于记录文件某行匹配的是哪一模式
char flag = '0';
Pattern pattern;
Matcher matcher;
//System.out.println(temp);
// 数据匹配,该循环之后flag值为1-8其中一个数字代表着该行文件文本匹配哪一模式
for (int i = 0; i < 8; i++) {
pattern = Pattern.compile(type_list.get(i));
matcher = pattern.matcher(temp);
if (matcher.find()) {
flag = (char) (48 + (i + 1));
break;
} else {
continue;
}
}
// 测试用++++++++++++++++++++++++++++++++++++++++++++++++++
// System.out.println(temp);
// 数据处理
pattern = Pattern.compile(type_list.get((int) (flag - 48) - 1));
matcher = pattern.matcher(temp);
Province p, p1, p2;
Province pi;
if (matcher.find()) {
switch (flag) {
// (\\W+) (新增 感染患者) (\\d+)(人)
case '1':
//累积数据
p = get_province(matcher.group(1));
p.ip += Integer.parseInt(matcher.group(3));
//新增数据
pi = incInfo.getProvince(matcher.group(1));
pi.ip = Integer.parseInt(matcher.group(3));
break;
// (\\W+) (新增 疑似患者) (\\d+)(人)
case '2':
//累积数据
p = get_province(matcher.group(1));
p.sp += Integer.parseInt(matcher.group(3));
//新增数据
pi = incInfo.getProvince(matcher.group(1));
pi.sp = Integer.parseInt(matcher.group(3));
break;
// (\\W+) (感染患者 流入) (\\W+) (\\d+)(人)
case '3':
p1 = get_province(matcher.group(1));
p2 = get_province(matcher.group(3));
p1.ip -= Integer.parseInt(matcher.group(4));
p2.ip += Integer.parseInt(matcher.group(4));
break;
// (\\W+) (疑似患者 流入) (\\W+) (\\d+)(人)
case '4':
p1 = get_province(matcher.group(1));
p2 = get_province(matcher.group(3));
p1.sp -= Integer.parseInt(matcher.group(4));
p2.sp += Integer.parseInt(matcher.group(4));
break;
// (\\W+) (死亡) (\\d+)(人)
case '5':
//累积数据
p = get_province(matcher.group(1));
p.dead += Integer.parseInt(matcher.group(3));
p.ip -= Integer.parseInt(matcher.group(3));
//新增数据
pi = incInfo.getProvince(matcher.group(1));
pi.dead = Integer.parseInt(matcher.group(3));
break;
// (\\W+) (治愈) (\\d+)(人)
case '6':
//累积数据
p = get_province(matcher.group(1));
p.cure += Integer.parseInt(matcher.group(3));
p.ip -= Integer.parseInt(matcher.group(3));
//新增数据
pi = incInfo.getProvince(matcher.group(1));
pi.cure = Integer.parseInt(matcher.group(3));
break;
// (\\W+) (疑似患者 确诊感染) (\\d+)(人)
case '7':
p = get_province(matcher.group(1));
p.ip += Integer.parseInt(matcher.group(3));
p.sp -= Integer.parseInt(matcher.group(3));
break;
// (\\W+) (排除 疑似患者) (\\d+)(人)
case '8':
p = get_province(matcher.group(1));
p.sp -= Integer.parseInt(matcher.group(3));
break;
default:
break;
}
} else {
System.out.println("NO MATCH");
}
}
// System.out.println("正在处理文件:" + f.getName()+"以下为该日期各省份新增ip数据:");
// System.out.println("该日期为:" + incInfo.date);
// for(int i = 0;i < incInfo.provinceList.size();i++) {
// System.out.println("name:" + incInfo.provinceList.get(i).name +
// " ip:" + incInfo.provinceList.get(i).ip +
// " sp:" + incInfo.provinceList.get(i).sp);
// }
//将处理好的信息加入表中
increaseList.add(incInfo);
}
网页显示
1.首先是数据统计部分,使用jsp的Java脚本部分展示动态数据

疫情统计
累计疑似
累计确诊
累计死亡
累计治愈
<%=cmd_run.get_province("全国").ip %>
<%=cmd_run.get_province("全国").dead %>
<%=cmd_run.get_province("全国").cure %>
<%=cmd_run.get_province("全国").sp %>
更新至<%=date%>
总数据统计
2.本次的关键,也就是图表部分,使用echarts,以下是折线图部分代码,使用jsp的Java脚本获取相关数据形成JavaScript的数组用于折线图的构造
六、心路历程与收获及对队友的评价
心路历程与收获
-
221701405
- 看到作业的时候感觉任务很艰巨,因为实现地图的工作量感觉很大的样子,时间又有限,而且自己没有接触过这种合作开发的情况,对于github的使用及分支也不了解。在协作的过程中,因为我对于git使用不够熟悉出了很多问题,但是在队友的帮助下都解决了。因为自己的能力不足,在开发过程中也查找了很多学习资料。通过本次作业,更好的掌握了前端的相关知识,提升了个人能力,也锻炼了我们合作开发的能力。
-
221701430
- 看到作业推荐的参考技术上只有JSP和servlet认识,而且才学不到一周,然后作业期限只有一周就很慌。还好数据的获取在第二次寒假作业时基本已经做完,在拆分整合代码的时候发现了之前的文件读取没有写跳过空行而且上次的文件编码是utf-8这次助教给的是ANSI,所以一开始代码报错还是很懵的,还好还是很快的发现了改正方法并加入了新增数据的获取功能,由于JSP刚学中途还是遇到许多困难,比如数据的传输问题,不过又时候IDE也不是特别友好的有两个页面明明用的是和其他页面一模一样的数据传输方法但在原页面显示是中文传过去就是乱码,传输数字倒是没有问题,最后干脆直接用其他页面的代码框架,虽然遇到种种挫折,但是在队友写完网页部分加上我的动态数据最终形成成品的时候还是很开心的。
对队友的评价
-
221701405
- 在两次结对作业中,由于对git使用不够熟悉以及自己开发能力的不足,出现了很多问题,说实话,我都被自己蠢哭了,但是我的队友很耐心的帮助我解决了这些问题。他是一名学习能力强、认真负责、开发思路清晰的优秀软工学子,简直太赞了。
-
221701430
- 我的队友真的是任劳任怨,非常优秀,经常做一些比较繁琐的工作,在两次作业中发挥了十分关键的作用,第二次作业时我们俩正好同时都出现了失误,加上我对git使用的不够熟练,看到项目崩了心态有点裂开,后来不知道可以revert就remove了仓库后,结果clone不了还是很慌的,不过还好队友很有耐心,我们也想了很多方法终于还是解决了问题,完成了作业,还是很有成就感的。总之,还是很幸运能够她当初找我合作,说实话我表达能力不好有的时候很啰嗦,还是感谢她的耐心和配合。