python 正则表达式基础实战
python正则表达式的过程大致如下图:
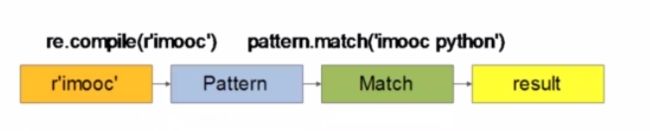
首先,通过re.compile()函数,生成pattern对象,该对象可以多次使用。
然后调用pattern对象的match(string)方法,在string中进行匹配,匹配成功后,返回 一个match对象,
通过调用match对象的group()方法,可以查看匹配到的信息。。。。
下面,我们简单示例一下:
>>> p=re.compile(r'imooc')#生成pattern对象,该对象可以多次使用
>>> p
<_sre.SRE_Pattern object at 0x7f121d1a2418>
>>> type(p)
>>> m=p.match('imoocabc')#生成match对象
>>> m
<_sre.SRE_Match object at 0x7f121d194238>
>>> type(m)
>>> m.group()#匹配到的子串
'imooc'
>>> m.string #被匹配的字符串
'imoocabc'
>>> m.span() #匹配到的子串在原字符串中的索引位置
(0, 5)
>>> m.re #pattern实例
<_sre.SRE_Pattern object at 0x7f121d1a2418>
>>>
>>> p=re.compile(r'imooc')
>>> m=p.match('IMOOcjfjd')#匹配失败,因为区分大小写
>>> type(m)
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> p=re.compile(r'imooc',re.I)#re.I表示忽略(ignore)大小写
>>> p
<_sre.SRE_Pattern object at 0x7f121d1b71f8>
>>> type(p)
>>> m=p.match('imoocjdf')
>>> m.group()
'imooc'
>>> m=p.match('IMOOcjdf')
>>> m.group()
'IMOOc'
>>>
>>> p=re.compile(r'(imooc)',re.I)#将imooc放到圆括号中
>>> p
<_sre.SRE_Pattern object at 0x7f121f265f48>
>>> m=p.match('iMOOCidf')
>>> m
<_sre.SRE_Match object at 0x7f121d1d9198>
>>> m.group()
'iMOOC'
>>> m.groups()#将imooc放到圆括号中,m.groups()会返回一个元组
('iMOOC',)
>>> >>> m=re.match(r'imooc','imoocjdf')#先生成pattern对象,再生成match对象,缺点:生成的pattern对象只使用了一次!
>>> m
<_sre.SRE_Match object at 0x7f121f2c2ac0>
>>> type(m)
>>> m.group()
'imooc' 【1】匹配单个字符
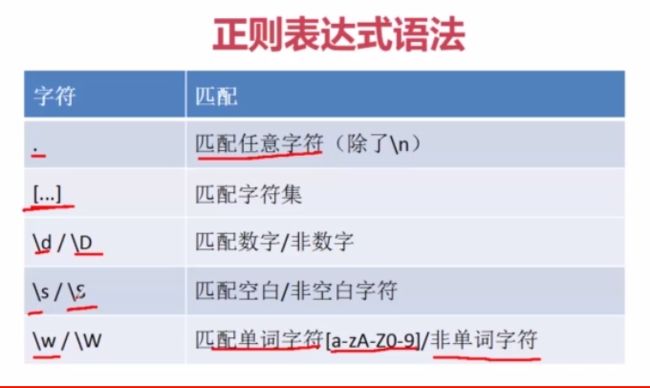
1》
.:用来匹配任意一个字符(不包含'\n')
>>> m=re.match(r'.','adg')
>>> m.group()
'a'
>>> m=re.match(r'.','123adg')
>>> m.group()
'1'
>>> m=re.match(r'.','@123adg')
>>> m.group()
'@'
>>> m=re.match(r'.','%@123adg')
>>> m.group()
'%'
>>> m=re.match(r'.','\n%@123adg')# .无法匹配'\n'
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> type(m)
>>> m=re.match(r'{.}','{a}\n%@123adg')
>>> m.group()
'{a}'
>>> m=re.match(r'{.}','{8}\n%@123adg')
>>> m.group()
'{8}'
>>> m=re.match(r'{.}','{8ab}\n%@123adg')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> type(m)
>>> m=re.match(r'{...}','{8ab}\n%@123adg')
>>> m.group()
'{8ab}' [a-z]匹配a-z中的任意一个字符 [0-9]匹配0-9中的任意一个字符
>>> m=re.match(r'{[abc]}','{b}\n%@123adg')
>>> m.group()
'{b}'
>>> m=re.match(r'{[abc]}','{g}\n%@123adg')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> type(m)
>>> m=re.match(r'{[a-z]}','{g}\n%@123adg')
>>> m.group()
'{g}'
>>> m=re.match(r'{[a-zA-Z]}','{H}\n%@123adg')
>>> m.group()
'{H}'
>>> m=re.match(r'[[a-z]]','[d]g%@123adg')#匹配失败,应用'\['来匹配'['
>>> m=re.match(r'([a-z])','(d)kdjkf') #匹配失败,应用'\('来匹配'('
\W代表一个非单词字符(\w的对立面)
>>> m=re.match(r'{[\w]}','{H}\n%@123adg')
>>> m.group()
'{H}'
>>> m=re.match(r'{[\w]}','{h}\n%@123adg')
>>> m.group()
'{h}'
>>> m=re.match(r'{[\w]}','{9}\n%@123adg')
>>> m.group()
'{9}'
>>> m=re.match(r'{[\w]}','{&}\n%@123adg')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> type(m)
>>> m=re.match(r'{[\W]}','{&}\n%@123adg')
>>> m.group()
'{&}' \D匹配一个非数字
>>> m=re.match(r'\d','9agd')
>>> m.group()
'9'
>>> m=re.match(r'\d','0agd')
>>> m.group()
'0'
>>> m=re.match(r'\d','ghh0agd')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> m=re.match(r'\D','ghh0agd')
>>> m.group()
'g'
>>> m=re.match(r'\D','Aghh0agd')
>>> m.group()
'A'
>>> m=re.match(r'\D','+Aghh0agd')
>>> m.group()
'+'
>>> m=re.match(r'\D','*+Aghh0agd')
>>> m.group()
'*' \S匹配非空白字符
>>> m=re.match(r'\s',' *+Aghh0agd')
>>> m.group()
' '
>>> m=re.match(r'\S','*+Aghh0agd')
>>> m.group()
'*'
>>> m=re.match(r'\S','$Aghh0agd')
>>> m.group()
'$'
>>> m=re.match(r'\S','h$Aghh0agd')
>>> m.group()
'h'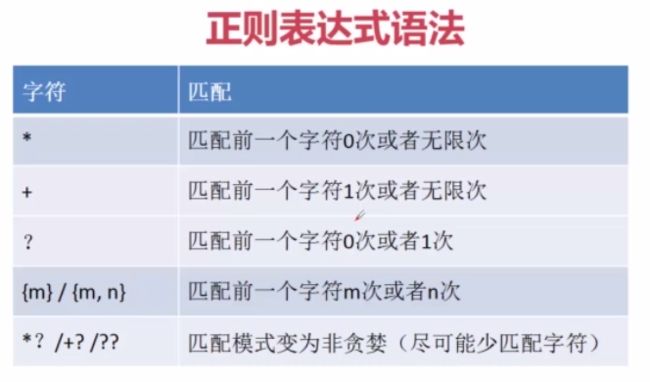
1》* 匹配前一个字符0次或者无限次(任意次)
>>> m=re.match(r'[A-Z][a-z]*','H')
>>> m.group()
'H'
>>> m=re.match(r'[A-Z][a-z]*','Hjdkjfksdjkff')
>>> m.group()
'Hjdkjfksdjkff'
>>> m=re.match(r'[A-Z][a-z]*','Hjdkjf98ksdjkff')
>>> m.group()
'Hjdkjf'
>>> m=re.match(r'[_a-zA-Z][\w]*','_this')
>>> m.group()
'_this'
>>> m=re.match(r'[_a-zA-Z][\w]*','_')
>>> m.group()
'_'
>>> m=re.match(r'[_a-zA-Z][\w]*','3abc')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group' >>> m=re.match(r'A[0-9]+','A')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> m=re.match(r'A[0-9]+','A8')
>>> m.group()
'A8'
>>> m=re.match(r'A[0-9]+','A88787gg')
>>> m.group()
'A88787' >>> m=re.match(r'[1-9]?[0-9]','100')
>>> m.group()
'10'
>>> m=re.match(r'[1-9]?[0-9]','990')
>>> m.group()
'99'
>>> m=re.match(r'[1-9]?[0-9]','0990')
>>> m.group()
'0'4》{m}/{m,n}匹配起一个字符m次或者m到n次
>>> m=re.match(r'[a-z0-9]{6}','123abckkk')
>>> m.group()
'123abc'
>>> m=re.match(r'[a-z0-9]{6}','123ab')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> m=re.match(r'[a-z0-9]{6}@163.com','[email protected]')
>>> m.group()
'[email protected]'
>>> m=re.match(r'[a-z0-9]{6,10}@163.com','[email protected]')
>>> m.group()
'[email protected]'
>>> m=re.match(r'[a-z0-9]{6,10}@163.com','[email protected]')
>>> m.group()
'[email protected]'
>>> m=re.match(r'[a-z0-9]{6,10}@163.com','[email protected]')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> m=re.match(r'[a-z0-9]{6,10}@163.com','[email protected]')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group' 5》*? +? ??匹配模式变为非贪婪(尽可能少的匹配字符)
>>> m=re.match(r'a[0-9]*','a90987abc')
>>> m.group()
'a90987'
>>> m=re.match(r'a[0-9]*?','a90987abc')
>>> m.group()
'a'
>>> m=re.match(r'a[0-9]+','a90987abc')
>>> m.group()
'a90987'
>>> m=re.match(r'a[0-9]+?','a90987abc')
>>> m.group()
'a9'
>>> m=re.match(r'a[0-9]?','a90987abc')
>>> m.group()
'a9'
>>> m=re.match(r'a[0-9]??','a90987abc')
>>> m.group()
'a'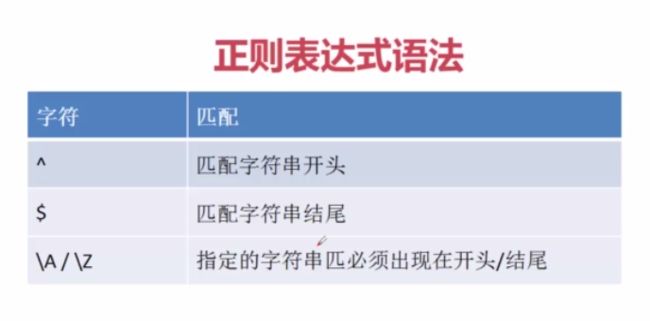
1》^ 匹配字符串的开头(match默认就是从头开始匹配)
2》$ 匹配字符串的结尾
>>> m=re.match(r'[\w]{6,10}@163.com','[email protected]') #match默认就是从头开始匹配
>>> m.group()
'[email protected]'
>>> m=re.match(r'^[\w]{6,10}@163.com','[email protected]') #显式指定从头开始匹配
>>> m.group()
'[email protected]'
>>> m=re.match(r'^[\w]{6,10}@163.com$','[email protected]') #指定必须以@163.com结尾
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> m=re.match(r'^[\w]{6,10}@163.com$','[email protected]') #指定必须以@163.com结尾
>>> m.group()
'[email protected]' 3》\A \Z 指定的字符串必须出现在开头/结尾
>>> m=re.match(r'\Aimooc[0-9]+','imooc123')
>>> m.group()
'imooc123'
>>> m=re.match(r'\Aimooc[0-9]+','iimooc123')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> m=re.match(r'[0-9]+imooc\Z','123imooc')
>>> m.group()
'123imooc'
>>> m=re.match(r'[0-9]+imooc\Z','123imoocbook')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group' 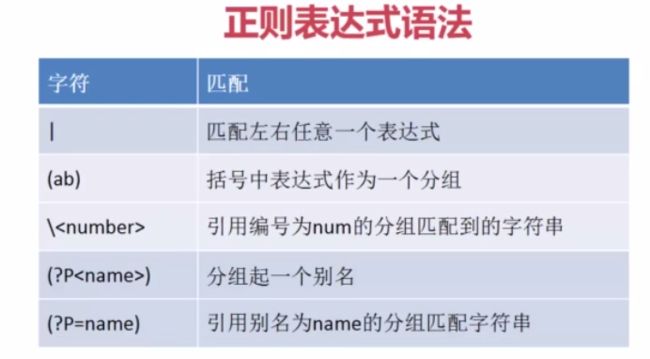
1》 | 匹配左右任意一个表达式
>>> m=re.match(r'abc|d','abckkk')
>>> m.group()
'abc'
>>> m=re.match(r'abc|d','dabckkk')
>>> m.group()
'd'
>>> m=re.match(r'[1-9]?[0-9]|100','0')
>>> m.group()
'0'
>>> m=re.match(r'[1-9]?[0-9]|100','59')
>>> m.group()
'59'
>>> m=re.match(r'[1-9]?[0-9]|100','100')
>>> m.group()
'10'
>>> m=re.match(r'[1-9]?[0-9]$|100','100')
>>> m.group()
'100'2》(163|126|qq)括号中的表达式作为一个分组,任选其中一个
>>> m=re.match(r'[\w]{4,6}@(163|126|qq).com','[email protected]')
>>> m.group()
'[email protected]'
>>> m=re.match(r'[\w]{4,6}@(163|126|qq).com','[email protected]')
>>> m.group()
'[email protected]'
>>> m=re.match(r'[\w]{4,6}@(163|126|qq).com','[email protected]')
>>> m.group()
'[email protected]'
>>> m=re.match(r'[\w]{4,6}@(163|126|qq).com','[email protected]')
>>> m.group()
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'group' 3》\number 引用编号为number的分组所匹配到字符串
>>> m=re.match(r'<([\w]+>)\1\1','book>book>')
>>> m.group()
'book>book>'
>>> m.groups()
('book>',)
>>> m=re.match(r'<([\w]+>)[\w]+python ')
>>> m.groups()
('book>',)
>>> m.group()
'python ' >>> m=re.match(r'<(?P[\w]+>)[\w]+python') #通过编号引用
>>> m.group()
'python '
>>> m=re.match(r'<(?P[\w]+>)[\w]+python')#通过别名引用
>>> m.group()
'python '上面我们学习了,正则表达式的基础语法,接着,我们简单学习一下python中的正则表达式模块-----re模块
使用该模块,首先要导入:import re
1》search(pattern,string,flags=0) 在一个字符串中查找匹配,返回第一个匹配
>>> s='imooc hours=1000'
>>> m=re.search(r'\d+',s)
>>> m
<_sre.SRE_Match object at 0x7fb4ae3da4a8>
>>> m.group()
'1000'
>>> s='imooc c++=1230,python=1200'
>>> m=re.search(r'\d+',s)
>>> m
<_sre.SRE_Match object at 0x7fb4ae3da4a8>
>>> m.group()
'1230'>>> s='c++=100,java=200,python=300'
>>> m=re.search(r'\d+',s)#返回第一个匹配
>>> m
<_sre.SRE_Match object at 0x7fb4ae3da578>
>>> m.group()
'100'
>>> info=re.findall(r'\d+',s) #返回所有匹配部分的列表
>>> info
['100', '200', '300']将字符串中匹配正则表达式的部分替换为其他值
3.1>repl是字符串
>>> s='imooc c++=1000'
>>> info=re.sub(r'\d+','1001',s)
>>> info
'imooc c++=1001'
>>> s='imooc c++=1000,python=2000'
>>> info=re.sub(r'\d+','1001',s)
>>> info
'imooc c++=1001,python=1001'sub(pattern,repl,string,count=0,flags=0) 若果repl是函数对象,则该函数接收的参数是一个match对象,
首先,对正则表达式pattern进行编译,生成一个pattern对象,
然后,使用该pattern对象,在字符串string中进行匹配,匹配成功,返回一个match对象,
最后,将该match对象,传递给repl函数!!!
【该部分代码可以帮助理解上述说明!!
>>> p=re.compile(r'\d+')
>>> p
<_sre.SRE_Pattern object at 0x7fb4ae486a48>
>>> m=p.match('123sdjf')
>>> m
<_sre.SRE_Match object at 0x7fb4ae3da4a8>
>>> m.group()
'123'
】
>>> def add1(match):
... s=match.group()
... value=int(s)+1
... return str(value)
...
>>> s='imooc c++=1000,java=2000,python=3000'
>>> re.sub(r'\d+',add1,s)
'imooc c++=1001,java=2001,python=3001'>>> s='imooc:c c++ python java'
>>> re.split(r':| ',s) #指定 ':'或' '作为分隔符(可以指定多个分隔符!!!)
['imooc', 'c', 'c++', 'python', 'java']
>>> s='imooc:c c++ python java,c#'
>>> re.split(r':| |,',s) #指定 ':'或' '或','作为分隔符
['imooc', 'c', 'c++', 'python', 'java', 'c#']最后,我们通过一个简单实例,来抓取网上的图片:
import urllib2,re
req=urllib2.urlopen('http://www.imooc.com/course/list')
buf=req.read()
urllist=re.findall(r'http:.+\.jpg',buf)
print urllist
i=0
for url in urllist:
request=urllib2.urlopen(url)
buffer=request.read()
f=open('C:\\Users\\91135\\Desktop\\image\\'+str(i)+'.jpg','w')
f.write(buffer)
f.close()
i+=1至此,我们对python中的正则表达式有了一个基本的了解,另外两篇介绍正则表达式的文章,推荐学习:
1》点击打开链接
2》点击打开链接