Python编程-使用爬虫程序爬取肺炎疫情数据-2 爬取给定国家的历史疫情信息
文字懒得写了,下面是代码
import json
import easygui
import xlwt
import requests
import datetime
def getDateList():
# 创建从2020-1-20到目前位置的日期序列
start_date = datetime.datetime(2020, 1, 20)
end_date = datetime.datetime.now()
date_list_all = []
for i in range((end_date.date() - start_date.date()).days + 1):
date_list_all.append(start_date + datetime.timedelta(days=i))
return date_list_all, start_date
def getChinaDataAndSave(workbook, china_day_list, daily_new_add_history, date_list_all, start_date, sheet_name = "中国"):
print("开始爬取 %s 的疫情数据... ... " % sheet_name)
# 创建一个worksheet
worksheet = workbook.add_sheet(sheet_name)
# 将列标题写入excel
current_row_index = 0 # 记录当前所写入数据的行号
for i, str_col in enumerate(['date', 'confirm', 'suspect', 'dead', 'heal', 'nowConfirm', 'nowSevere', "importedCase", 'deadRate', 'healRate', "全国新增", '湖北新增', "全国(除湖北)新增"]):
worksheet.write(current_row_index, i, str_col) # 参数对应 行, 列, 值
worksheet.col(i).width = 150 * 20 # 设置excel中第A列的宽度(方便日期数据展示)
current_row_index += 1
# 往excel中写入日期
style = xlwt.XFStyle()
style.num_format_str = 'YYYY/MM/DD'
first_data_date = datetime.datetime.strptime('2020.' + daily_new_add_history[0]['date'], "%Y.%m.%d") # 爬取到疫情数据的最早日期
delta_time = (first_data_date - start_date).days
# 2020-1-20 到 first_data_date(不含后者) 之间未爬取到疫情数据,下面将这些时间数据写入excel
for i in range(delta_time):
worksheet.write(current_row_index, 0, date_list_all[current_row_index - 1], style)
current_row_index += 1
# china_day_list 和 daily_new_add_history中的数据开始日期不一致,通过断点调试可知china_day_list是从2020.1.13开始的, daily_new_add_history是从2020.1.20开始的
china_day_list = [i for i in china_day_list if (datetime.datetime.strptime('2020.' + i['date'], "%Y.%m.%d") - start_date).days >= 0]
# 提取海外数据信息,并写入excel
for china_day_i, daily_new_add_history_i in zip(china_day_list, daily_new_add_history):
worksheet.write(current_row_index, 0, datetime.datetime.strptime('2020.' + china_day_i["date"], "%Y.%m.%d"), style)
worksheet.write(current_row_index, 1, china_day_i['confirm'])
worksheet.write(current_row_index, 2, china_day_i['suspect'])
worksheet.write(current_row_index, 3, china_day_i['dead'])
worksheet.write(current_row_index, 4, china_day_i['heal'])
worksheet.write(current_row_index, 5, china_day_i['nowConfirm'])
worksheet.write(current_row_index, 6, china_day_i['nowSevere'])
worksheet.write(current_row_index, 7, china_day_i['importedCase'])
worksheet.write(current_row_index, 8, china_day_i['deadRate'])
worksheet.write(current_row_index, 9, china_day_i['healRate'])
worksheet.write(current_row_index, 10, daily_new_add_history_i['country'])
worksheet.write(current_row_index, 11, daily_new_add_history_i['hubei'])
worksheet.write(current_row_index, 12, daily_new_add_history_i['notHubei'])
current_row_index += 1
print("%s 的疫情数据爬取完毕" % sheet_name)
def getURLContentGet(url):
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
response = requests.get(url, headers=headers)
return response.status_code, response
def getForeignCountryList(foreign_all_data_info):
'''
:param foreign_all_data_info: dict对象,foreign_all_data_info['foreignList']是一个list对象,每一个对象是一个国家的疫情信息
:return:
'''
foreignCountryList = []
foreignList = foreign_all_data_info['foreignList']
for country in foreignList:
foreignCountryList.append(country['name'])
return foreignCountryList
def getCountryEpidemiSituationInfo(workbook, country_list):
date_list_all, start_date = getDateList()
for index, country_i in enumerate(country_list):
print("开始爬取 %s 的疫情数据... ... " % country_i)
url = 'https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?country=%s' % country_i
status_code, data = getURLContentGet(url)
if status_code != 200:
print("%s数据爬取失败,状态码%d" % (country_i, status_code))
sys.exit()
data = data.json()["data"]
if data == None:
print("\n\n%s数据爬取数据为空\n\n" % country_i)
break
# 创建一个worksheet
worksheet = workbook.add_sheet(country_i)
worksheet.col(0).width = 128 * 20 # 设置excel中第A列的宽度(方便日期数据展示)
current_row_index = 0 # 记录当前所写入数据的行号
# 将列标题写入excel
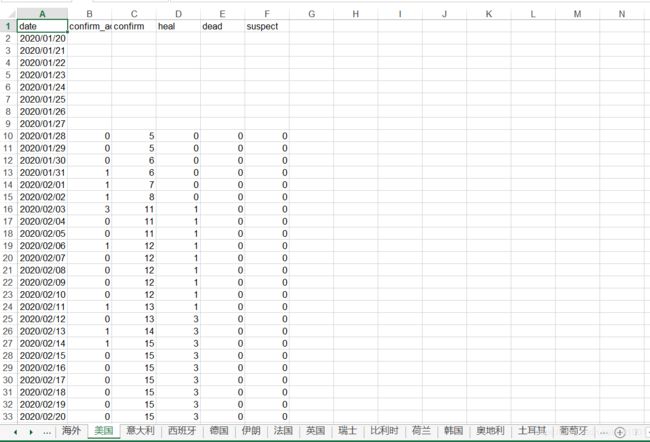
for i, str_col in enumerate(['date', 'confirm_add', 'confirm', 'heal', 'dead', 'suspect']):
worksheet.write(current_row_index, i, str_col) # 参数对应 行, 列, 值
current_row_index += 1
# 往excel中写入日期
style = xlwt.XFStyle()
style.num_format_str = 'YYYY/MM/DD'
first_data_date = datetime.datetime.strptime('2020.' + data[0]['date'], "%Y.%m.%d") # 爬取到疫情数据的最早日期
delta_time = (first_data_date - start_date).days
# 2020-1-20 到 first_data_date(不含后者) 之间未爬取到疫情数据,下面将这些时间数据写入excel
for i in range(delta_time):
worksheet.write(current_row_index, 0, date_list_all[current_row_index - 1], style)
current_row_index += 1
# 将抓取到的疫情数据写入excel
for data_i in data:
worksheet.write(current_row_index, 0, datetime.datetime.strptime('2020.' + data_i['date'], "%Y.%m.%d"), style)
worksheet.write(current_row_index, 1, data_i['confirm_add'])
worksheet.write(current_row_index, 2, data_i['confirm'])
worksheet.write(current_row_index, 3, data_i['heal'])
worksheet.write(current_row_index, 4, data_i['dead'])
worksheet.write(current_row_index, 5, data_i['suspect'])
current_row_index += 1
def getGlobalDataAndSave(workbook, all_history, date_list_all, start_date, sheet_name = '海外'):
print("开始爬取 %s 的疫情数据... ... " % sheet_name)
# 创建一个worksheet
worksheet = workbook.add_sheet(sheet_name)
worksheet.col(0).width = 128 * 20 # 设置excel中第A列的宽度(方便日期数据展示)
# 将列标题写入excel
current_row_index = 0 # 记录当前所写入数据的行号
for i, str_col in enumerate(['date', 'confirm', 'dead', 'heal', 'newAddConfirm', 'deadRate', 'healRate']):
worksheet.write(current_row_index, i, str_col) # 参数对应 行, 列, 值
current_row_index += 1
# 往excel中写入日期
style = xlwt.XFStyle()
style.num_format_str = 'YYYY/MM/DD'
first_data_date = datetime.datetime.strptime('2020.' + all_history[0]['date'], "%Y.%m.%d") # 爬取到疫情数据的最早日期
delta_time = (first_data_date - start_date).days
# 2020-1-20 到 first_data_date(不含后者) 之间未爬取到疫情数据,下面将这些时间数据写入excel
for i in range(delta_time):
worksheet.write(current_row_index, 0, date_list_all[current_row_index - 1], style)
current_row_index += 1
# 提取海外数据信息,并写入excel
for daily_history_i in all_history:
worksheet.write(current_row_index, 0, datetime.datetime.strptime('2020.' + daily_history_i["date"], "%Y.%m.%d"),
style)
worksheet.write(current_row_index, 1, daily_history_i["all"]['confirm'])
worksheet.write(current_row_index, 2, daily_history_i["all"]['dead'])
worksheet.write(current_row_index, 3, daily_history_i["all"]['heal'])
worksheet.write(current_row_index, 4, daily_history_i["all"]['newAddConfirm'])
worksheet.write(current_row_index, 5, daily_history_i["all"]['deadRate'])
worksheet.write(current_row_index, 6, daily_history_i["all"]['healRate'])
current_row_index += 1
print("%s 的疫情数据爬取完毕" % sheet_name)
def getArticleInfoFromGivedList(workbook, article_list, sheet_name):
# 创建一个worksheet
worksheet = workbook.add_sheet(sheet_name)
if len(article_list) > 0:
current_row_index = 0
#设置列宽
worksheet.col(0).width = 256 * 20
worksheet.col(1).width = 128 * 20
worksheet.col(2).width = 512 * 20
worksheet.col(3).width = 512 * 20
worksheet.col(4).width = 2048 * 20
# 将列标题写入excel
for i, str_col in enumerate(['publish_time', 'media', 'title', 'url', 'desc']):
worksheet.write(current_row_index, i, str_col) # 参数对应 行, 列, 值
current_row_index += 1
for article_i in article_list[-1:- len(article_list) - 1 : -1]:
worksheet.write(current_row_index, 0, article_i["publish_time"])
worksheet.write(current_row_index, 1, article_i["media"])
worksheet.write(current_row_index, 2, article_i["title"])
worksheet.write(current_row_index, 3, article_i["url"])
worksheet.write(current_row_index, 4, article_i["desc"])
current_row_index += 1
if __name__ == "__main__":
foreign_url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_foreign'
_, foreign_response = getURLContentGet(foreign_url)
foreign_json_data = json.loads(foreign_response.text)
foreign_all_data = json.loads(foreign_json_data['data'])
foreign_country_list = getForeignCountryList(foreign_all_data)
#foreign_country_list = ["美国", '意大利','丹麦', '日本本土', '韩国', '加拿大', '德国', '英国']
countries_and_regions = ['中国', "海外"]
countries_and_regions.extend(foreign_country_list)
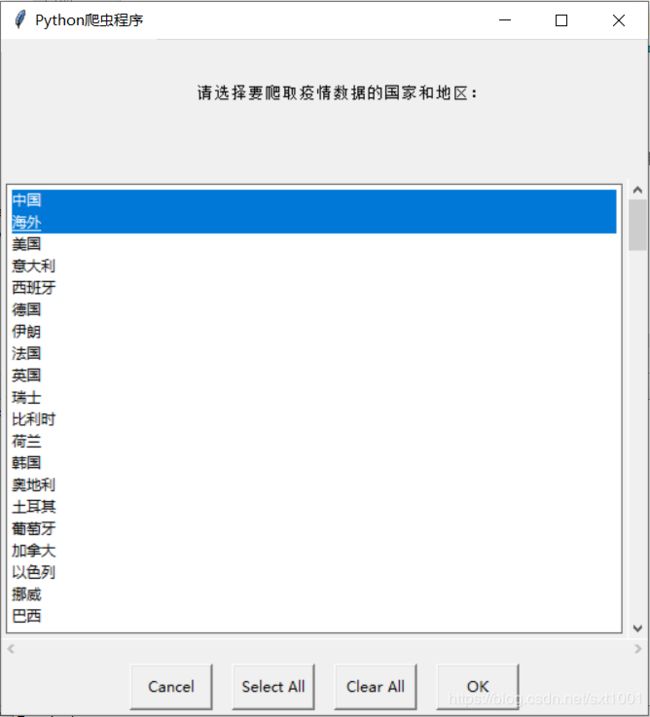
choice = easygui.multchoicebox("\n\t\t请选择要爬取疫情数据的国家和地区:\t\t\n", title="Python爬虫程序", choices=countries_and_regions,
preselect=[0, 1])
# 获取日期列表
date_list_all, start_date = getDateList()
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
if "中国" in choice:
del choice[choice.index("中国")]
china_url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
other_url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_other'
_, china_response = getURLContentGet(china_url)
_, other_response = getURLContentGet(other_url)
china_json_data = json.loads(china_response.text)
other_json_data = json.loads(other_response.text)
china_all_data = json.loads(china_json_data['data'])
other_all_data = json.loads(other_json_data['data'])
china_all_data_area_tree = china_all_data['areaTree'][0] # china_all_data['areaTree']是list对象,只有一个元素
china_all_data_article_list = china_all_data['articleList']
china_all_data_china_day_list = china_all_data['chinaDayList']
china_all_data_china_day_add_list = china_all_data['chinaDayAddList']
china_all_data_daily_new_add_history = china_all_data['dailyNewAddHistory']
china_all_data_daily_history = china_all_data['dailyHistory']
# 下面的后四项和上面的后四项都代表相同的数据,但是,不一定是同时有数据,有一方可能是空列表(目前是上方的后四项为[]) --怀疑原因:2020.3.23-24 在other_all_data有globalDailyHistory元素,但是2020.3.25晚上就找不到该元素了,导致重写程序。
other_all_data_article_list = other_all_data['articleList']
other_all_data_china_day_list = other_all_data['chinaDayList']
other_all_data_china_day_add_list = other_all_data['chinaDayAddList']
other_all_data_daily_new_add_history = other_all_data['dailyNewAddHistory']
other_all_data_daily_history = other_all_data['dailyHistory']
china_day_list = [other_all_data_china_day_list if len(other_all_data_china_day_list) > len(
china_all_data_china_day_list) else china_all_data_china_day_list][0]
daily_new_add_history = \
[other_all_data_daily_new_add_history if len(other_all_data_daily_new_add_history) > len(
china_all_data_daily_new_add_history) else china_all_data_daily_new_add_history][0]
getChinaDataAndSave(workbook, china_day_list, daily_new_add_history, date_list_all, start_date, sheet_name="中国")
if "海外" in choice:
del choice[choice.index("海外")]
foreign_all_data_global_daily_history = foreign_all_data['globalDailyHistory']
foreign_all_data_foreign_list = foreign_all_data['foreignList']
foreign_all_data_global_statis = foreign_all_data['globalStatis']
global_daily_history = foreign_all_data_global_daily_history
getGlobalDataAndSave(workbook, global_daily_history, date_list_all, start_date, sheet_name="海外")
if len(choice) > 0:
getCountryEpidemiSituationInfo(workbook, choice)
# 保存
workbook.save('./疫情原始数据.xls')效果如下: