SPFA 算法详解( 强大图解,不会都难!)&&spfa优化——深度优先搜索dfs
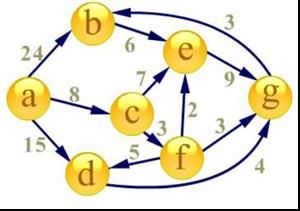

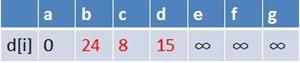

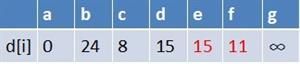
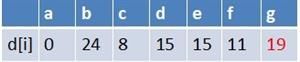

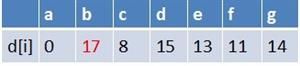

最终a到g的最短路径为14
SPFA(Shortest Path Faster Algorithm) [图的存储方式为邻接表]
是Bellman-Ford算法的一种队列实现,减少了不必要的冗余计算。
算法大致流程是用一个队列来进行维护。 初始时将源加入队列。 每次从队列中取出一个元素,
并对所有与他相邻的点进行松弛,若某个相邻的点松弛成功,则将其入队。 直到队列为空时算法结束。
它可以在O(kE)的时间复杂度内求出源点到其他所有点的最短路径,可以处理负边。
SPFA 在形式上和BFS非常类似,不同的是BFS中一个点出了队列就不可能重新进入队列,但是SPFA中
一个点可能在出队列之后再次被放入队列,也就是一个点改进过其它的点之后,过了一段时间可能本
身被改进,于是再次用来改进其它的点,这样反复迭代下去。
判断有无负环:如果某个点进入队列的次数超过V次则存在负环(SPFA无法处理带负环的图)。
SPFA算法有两个优化算法 SLF 和 LLL:
SLF:Small Label First 策略,设要加入的节点是j,队首元素为i,若dist(j) 否则插入队尾。 LLL:Large Label Last 策略,设队首元素为i,队列中所有dist值的平均值为x,若dist(i)>x则将i插入 到队尾,查找下一元素,直到找到某一i使得dist(i)<=x,则将i出对进行松弛操作。 引用网上资料,SLF 可使速度提高 15 ~ 20%;SLF + LLL 可提高约 50%。 在实际的应用中SPFA的算法时间效率不是很稳定,为了避免最坏情况的出现,通常使用效率更加稳定的Dijkstra算法。 求单源最短路的SPFA算法的全称是:Shortest Path Faster Algorithm。 下面举一个实例来说明SFFA算法是怎样进行的: SPFA 在形式上和广度(宽度)优先搜索非常类似,不同的是bfs中一个点出了队列就不可能重新进入队列,但是SPFA中一个点可能在出队列之后再次被放入队列,也就是一个点改进过其它的点之后,过了一段时间可能本身被改进(重新入队),于是再次用来改进其它的点,这样反复迭代下去。
如何输出呢?我们记录的是每个点前面的点是什么,输出却要从最前面到后面输出,这很好办,递归就可以了:
SPFA算法是西南交通大学段凡丁于1994年发表的。
从名字我们就可以看出,这种算法在效率上一定有过人之处。
很多时候,给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便派上用场了。有人称spfa算法是最短路的万能算法。
简洁起见,我们约定有向加权图G不存在负权回路,即最短路径一定存在。当然,我们可以在执行该算法前做一次拓扑排序,以判断是否存在负权回路。
我们用数组dis记录每个结点的最短路径估计值,可以用邻接矩阵或邻接表来存储图G,推荐使用邻接表。
spfa的算法思想(动态逼近法):
设立一个先进先出的队列q用来保存待优化的结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止。
松弛操作的原理是著名的定理:“三角形两边之和大于第三边”,在信息学中我们叫它三角不等式。所谓对结点i,j进行松弛,就是判定是否dis[j]>dis[i]+w[i,j],如果该式成立则将dis[j]减小到dis[i]+w[i,j],否则不动。
和广搜bfs的区别:
void spfa(s); //求单源点s到其它各顶点的最短距离
for i=1 to n do { dis[i]=∞; vis[i]=false; } //初始化每点到s的距离,不在队列
dis[s]=0; //将dis[源点]设为0
vis[s]=true; //源点s入队列
head=0; tail=1; q[tail]=s; //源点s入队, 头尾指针赋初值
while head
最短路径本身怎么输出?
在一个图中,我们仅仅知道结点A到结点E的最短路径长度,有时候意义不大。这个图如果是地图的模型的话,在算出最短路径长度后,我们总要说明“怎么走”才算真正解决了问题。如何在计算过程中记录下来最短路径是怎么走的,并在最后将它输出呢?
我们定义一个path[]数组,path[i]表示源点s到i的最短路程中,结点i之前的结点的编号(父结点),我们在借助结点u对结点v松弛的同时,标记下path[v]=u,记录的工作就完成了。
c++ code:
void printpath(int k){
if (path[k]!=0) printpath(path[k]);
cout << k << ' ';
}
pascal code:
procedure printpath(k:longint);
begin
if path[k]<>0 then printpath(path[k]);
write(k,' ');
end;
spfa算法模板(邻接矩阵):
c++ code:
void spfa(int s){
for(int i=0; i<=n; i++) dis[i]=99999999; //初始化每点i到s的距离
dis[s]=0; vis[s]=1; q[1]=s; 队列初始化,s为起点
int i, v, head=0, tail=1;
while (headpascal code(邻接矩阵):
var i,n,m,s,t,x,y,z:longint; s:起点;t:终点
a,b:array[0..201,0..201] of longint; b[x,c]存与x相连的第c个边的另一个结点y
q:array[0..10001] of integer; 队列
vis:array[0..201] of boolean; 是否入队的标记
dis:array[0..201] of longint; 到起点的最短路
procedure spfa(s:longint);
var i,j,v,head,tail:longint;
begin
fillchar(q,sizeof(q),0);
fillchar(vis,sizeof(vis),false);
for i:=0 to n do dis[i]:=99999999;
dis[s]:=0; vis[s]:=true; q[1]:=s; 队列的初始状态,s为起点
head:=0;tail:= 1;
while head
spfa优化——深度优先搜索dfs
但是有负环时,上述算法的时间复杂度退化为O(nm)。能不能改进呢?
那我们试着使用深搜,核心思想为
每次从更新一个结点u时,从该结点开始递归进行下一次迭代。
使用dfs优化spfa算法:
pascal code:
procedure spfa(s:longint);
var i:longint;
begin
for i:=1 to b[s,0] do //b[s,0]是从顶点s发出的边的条数
if dis[b[s,i]]>dis[s]+a[s,b[s,i]] then //b[s,i]是从s发出的第i条边的另一个顶点
begin
dis[b[s,i]]:=dis[s]+a[s,b[s,i]];
spfa(b[s,i]);
end;
end;
C++ code:
void spfa(int s){
for(int i=1; i<=b[s][0]; i++) //b[s,0]是从顶点s发出的边的条数
if (dis[b[s][i]>dis[s]+a[s][b[s][i]]){ //b[s,i]是从s发出的第i条边的另一个顶点
dis[b[s][i]=dis[s]+a[s][b[s][i]];
spfa(b[s][i]);
}
}
那我们试着使用深搜,核心思想为
每次从更新一个结点u时,从该结点开始递归进行下一次迭代。
对于WorldRings(ACM-ICPC Centrual European 2005)这道题,676个点,100000条边,查找负环dfs仅仅需219ms。
一个简洁的数据结构和算法在一定程度上解决了大问题。
【程序1】畅通工程 laoj1138 spfa算法(dfs):
pascal code:
var i,n,m,s,t,x,y,z:longint;
a,b:array[0..201,0..201] of longint;
q:array[0..10001] of integer;
vis:array[0..201] of boolean;
dis:array[0..201] of longint;
procedure spfa(s:longint);
var i:longint;
begin
for i:=1 to b[s,0] do
if dis[b[s,i]]>dis[s]+a[s,b[s,i]] then
begin
dis[b[s,i]]:=dis[s]+a[s,b[s,i]];
spfa(b[s,i]);
end;
end;
begin
read(n, m);
fillchar(a,sizeof(a),0);
for i:=1 to m do
begin
readln(x,y,z);
if (a[x,y]<>0)and(z>a[x,y]) then continue;
inc(b[x,0]);b[x,b[x,0]]:=y;a[x,y]:=z;
inc(b[y,0]);b[y,b[y,0]]:=x;a[y,x]:=z;
end;
readln(s,t);
for i:=0 to n do dis[i]:=99999999;
dis[s]:=0;
spfa(s);
if dis[t]<>99999999 then writeln(dis[t]) else writeln(-1);
end.
C++ code:
#include
例如,在下图中,仍然假设弧(1,2),(l,3),(2,4),(3,2),(4,3),(4,5),(5,3)和(5,4)上的权分别为8,9,6,4,0,7,6和3。此时该网络图可以用前向星形表示法表示如下:
前向星存储图:
#include