Python的垃圾回收机制(三)之回收机制
0. 背景
之前介绍了Python垃圾回收的简介和内存模型,这里会对前几篇提到的回收机制进行代码剖析。注意这里用到的术语,如有疑问移步(一)简介查看。
1. 标记清除中的GC
Python使用引用计数来管理对象的生命周期。但是问题来了,如何解决循环引用的问题?
循环引用计数也好办,使用标记清除(Mark-and-Sweep)就可以解决。
标记清除方法遵循垃圾检测和垃圾回收两个阶段,其简要工程如下:
1). 寻找根集(root object set),所谓的根集即是一些全局引用和函数栈中的引用。这些引用所用的对象时不可被删除的,而这个根集也是垃圾检测动作的起点。
2). 从根集出发,沿着根集中的每一个引用,如果能到达某个对象A,则称A为可达对象,可达对象时不可被删除的。这个阶段就是垃圾检测的阶段。
3). 当垃圾检测阶段结束后,所有的对象分可达对(reachable object)象和不可达对象(unreachable object)两部分,所有的可达对象都必须予以保留,而所有的不可达对象所占用的内存将被回收,这就是垃圾回收阶段。
但是使用标记清除需要明确几个问题:
a). 如何确定根集(root object set)?
这个问题我们会在系列四-回收流程中详述。
b). 标记清除是释放那些不可达对象的内存,而这些不可达对象是通过可达对象在全集(universal set)中的补集确定的,那全集又如何确定?
这个问题我们会在下一节详述。
c). 由于标记清除回收算法是一个深度搜索遍历的一个过程,那这个回收过程会花费很长时间吗?
答案是不会的,因为绝大部分的对象已经通过引用计数回收掉了。所有没有被引用计数回收而进入Mark-and-Sweep环节的对象,基本都是循环引用的对象。
2. 全集(Universal Set)
a). 全集的数据结构应该是什么?
会不会是数组?
应该不会是数组,因为全集包括可达对象和不可达对象,最后会把不可达对象进行回收,所以如果是数组来存储全集,那么会出现内存碎片,如果你想化零为整,数组的移动效率也是比较慢的。
b). 那会不会是链表?
链表相对于数组,在回收不可达对象时,删除效率很高:只需要调整若干指针(prev, next),就可以在O(1)的时间内完成。但是遗憾的是我们需要额外的指针的内存。
那Python语言使用哪种数据结构作为全集?
是后一种。每一个PyObject中在GC的时候,头部会添加一个叫做PyGC_Head的结构代码1:
/* GC information is stored BEFORE the object structure. */
typedef union _gc_head {
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;gc_next和gc_prev是上面说的指针,gc_refs的值则会初始化GC_UNTRACED,并在系列四-回收流程中讲述它的作用。
此时PyObject的内存模型如下图:
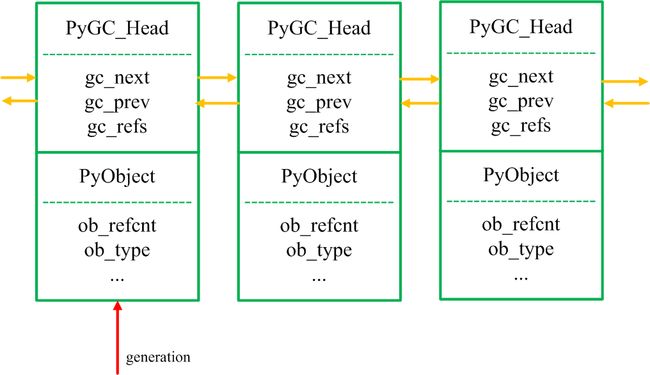
而下面的generation指针是遍历这个链表的指针,其实这也是世代回收器的体现。
我们来看一下在C中_Python_GC_New的代码2:
PyObject *
_PyObject_GC_New(PyTypeObject *tp)
{
PyObject *op = _PyObject_GC_Malloc(_PyObject_SIZE(tp));
if (op != NULL)
op = PyObject_INIT(op, tp);
return op;
}
PyObject *
_PyObject_GC_Malloc(size_t basicsize)
{
PyObject *op;
PyGC_Head *g;
if (basicsize > PY_SSIZE_T_MAX - sizeof(PyGC_Head))
return PyErr_NoMemory();
//[1]:为对象本身及PyGC_Head申请内存
g = (PyGC_Head *)PyObject_MALLOC(
sizeof(PyGC_Head) + basicsize);
if (g == NULL)
return PyErr_NoMemory();
g->gc.gc_refs = GC_UNTRACKED; //[2]
generations[0].count++; /* [3] number of allocated GC objects */
if (generations[0].count > generations[0].threshold &&
enabled &&
generations[0].threshold &&
!collecting &&
!PyErr_Occurred()) {
collecting = 1;
collect_generations(); //[4] 进行一次世代回收
collecting = 0;
}
op = FROM_GC(g);
return op;
}从代码中可以看到[1]处可以清楚的看到,当Python为可收集的PyObject申请内存空间时,为PyGC_Head也申请了内存空间,并且其位置在PyObject对象之前。
在Py_GC_HEAD部分,除了两个用于建立链表结构的向前和向后指针外,还有一个gc_ref,在代码[2]处,这个值被初始化为GC_UNTRACED。
3. 回收触发(collect_generations())
在代码2的[3]处,对于新申请的PyObject_GC的对象内存后,就对世代0的数量自增1,当generation 0的对象个数大于一定阈值时,就需要进行一次世代回收collect_generations([4]处)。如下代码3所示:
static Py_ssize_t
collect_generations(void)
{
int i;
Py_ssize_t n = 0;
/* Find the oldest generation (highest numbered) where the count
* exceeds the threshold. Objects in the that generation and
* generations younger than it will be collected. */
for (i = NUM_GENERATIONS-1; i >= 0; i--) {
if (generations[i].count > generations[i].threshold) {
/* Avoid quadratic performance degradation in number
of tracked objects. See comments at the beginning
of this file, and issue #4074.
*/
if (i == NUM_GENERATIONS - 1
&& long_lived_pending < long_lived_total / 4)
continue;
n = collect(i); //[2] 回收第i代及比它年轻的代内存
break;
}
}
return n;
}在collect_generations函数中,Python会借第0代内存链表的越界触发了垃圾收集的机会,函数会调用collect(int generation)([2]处),回收这“代”对应的内存和所有比它年轻的“代”对应的内存。
4. 回收流程( collect(int generation))
输入参数generation表示函数必须指定某一代,在这里我们成为”当代“;返回不可达对象的个数。
/* This is the main function. Read this to understand how the
* collection process works. */
static Py_ssize_t
collect(int generation)
{
//[1]: 初始化定义
//[2]: 将比当代处理的“代”更年轻的“代”的链表合并到当前“代”中
//[3]: 将当代对象中的引用计数抄一份到对象的Py_GC_Head中(gc_refs = ob_refcnt)
//[4]: 通过traverse机制更新对象中的引用计数,最终不可达对象的引用计数会被减为0,不为0即是root object
//[5]: 初始化一个链表叫unreachable,把不可达的对象(引用计数为0)移到该链表中
//[6]: 又初始化一个链表叫finalizers, 把链表unreachable中带有__del__的对象进一步分离到finalizers
//[7]: 将finalizers中的对象又设置为可达对象(gc_refs=GC_REACHABLE)
//[8]: debug信息,可以打印可回收对象
//[9]: 通知所有弱引用到unreachable对象的对象,如果若引用对象仍然生存则放回
//[10]: 删除unreachable链表中的对象(垃圾),这会打破对象的循环引用
//[11]: debug信息,可以打印不可回收对象
//[12]: 把所有finalizers对象放到gc.garbage中
//[13]: 返回不可达对象个数
}如上代码所示,我已经用步骤实现的功能描述代替了原代码,共分为13个步骤,系列四会详细讲述这个回收流程中每个步骤具体的代码和内部实现。
5. 总结
本文讲述了标记清除的简要工作流程,垃圾回收的触发点以及回收流程。下个系列会讲述Python的垃圾回收机制(四)之回收流程。