成人数据集报告(kNN、决策树、朴素贝叶斯)
1.问题描述
根据人口普查数据预测某个人收入是否超过5万美元/年,借此可以用来进行一些产品的推广。
2.数据准备与处理
数据集包含14个属性,分别是:年龄、工作类别、final weight、教育、教育数量、婚姻状况、职业、关系、种族、性别、资本收益、资本损失、每周小时数、国籍。其中,年龄、final weight、教育数量、资本收益、资本损失和每周小时数是数值标签,其余是标称标签。

数据集的实例数量为500个,用来测试的数据实例数量为32个。
因为数据集的每一条数据属性太多,为了便于测试和增加准确度,将存在相关性的数据属性保留其中一个属性。例如,教育与教育数量存在正相关,将教育数量摒弃,工作类别与每周小时数存在相关性,将每周小时数舍弃。
该数据集中不存在缺失项,所以不需要进行数据的填充。为使kNN、决策树和朴素贝叶斯三种算法适用该数据集,选择“工作类别”、“教育”、“婚姻状况”、“职业”、“关系”、“种族”、“性别”和“国籍”8个属性的数据用于决策树和朴素贝叶斯的训练;选择“年龄”、“final weight”、“教育数量”、“资本收益”、“资本损失”和“每周小时数”6个属性数据用于kNN的训练。
进行kNN处理时,因为“final weight”的数值比其他属性数值大太多,所以对进行训练的6个属性进行归一化处理:
![]()
3.数据可视化
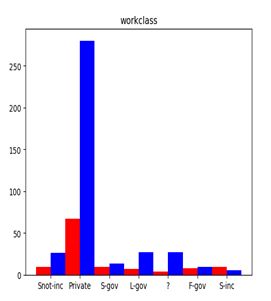
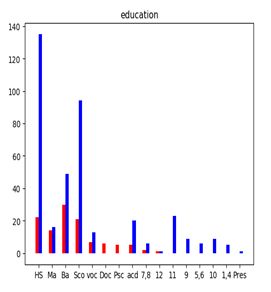

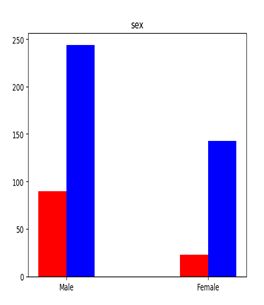
4.模型基本原理与算法实现
kNN:
记录训练样本集中每一数据与所属分类的对应关系,输入预测数据的新数据后,将新数据的每个特征与训练样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据的前k个分类标签,选择k个最相似数据中出现次数最多的分类,作为新数据分类。判断相似度采用欧式距离的计算方法,设数据有 ![]() 个标签,则欧式距离d:
个标签,则欧式距离d:
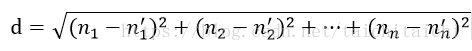
d越小,则两个数据的相似度越大。
决策树:
根据信息增益的大小,每次选择信息增益最大的特征对数据集进行划分。
设训练数据集位D,|D|表示其样本容量,即样本个数。设有K个类![]() ,k=1,2,…,K,
,k=1,2,…,K,![]() 为属于类
为属于类![]() 的样本个数,
的样本个数,![]() 。设特征A有n个不同的取值
。设特征A有n个不同的取值![]() ,根据特征A的取值将D划分为n个子集
,根据特征A的取值将D划分为n个子集 ![]() ,
,![]() 为
为 ![]() 的样本个数,
的样本个数,![]() 。记子集
。记子集![]() 中属于类
中属于类 ![]() 的样本的集合为
的样本的集合为 ![]() ,即
,即![]() ,
,![]() 为
为 ![]() 的样本个数。信息增益算法如下:
的样本个数。信息增益算法如下:
(1)计算数据集D的经验熵H(D)

(2)计算特征A对数据集D的经验条件熵H(D|A)

(3)计算信息增益
![]()
本次预测数据中每组包含4个特征,先选出4个特征中信息增益最大的特征作为第一个决策点,之后再从剩下的3个特征中选出信息增益最大的作为第二个决策点,直到每一个特征都作为决策点,算法结束。
朴素贝叶斯:
贝叶斯公式:

代入该数据集表示为:
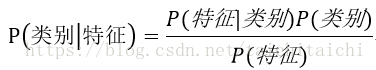
该数据集的特征为选取的8个属性值,类别为“>50K”和“<=50K”两类。
这里假设各个特征事件的发生彼此独立,则:


其中

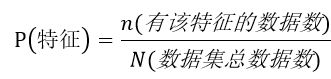

假设测试数据集中存在特征x不存在训练集中,则:


其中e的值等于在特征x所在此类别的属性的总种类数
最后比较 ![]() 和
和 ![]() 的大小:
的大小:
5.测试方法与结果
kNN结果:
测试数据为32组
k=3时:正确率为87.5%
k=4时:正确率为87.5%
…
k=19时:正确率为87.5%
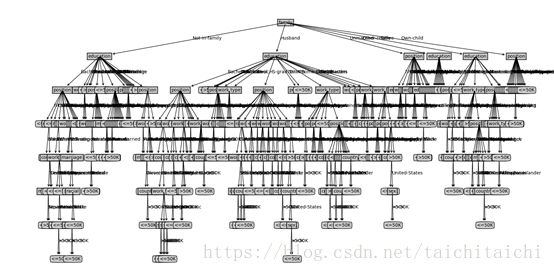
决策树结果:
测试数据为32组
正确率为96.875%
朴素贝叶斯结果:
测试数据为32组
正确率为93.75%
6.总结
在进行kNN训练时,k值的变化并没有引起正确率的变化。检查测试数据分类的结果,发现所有进行测试的数据全部分类到’<=50K’一类,所以不随k值变化。再去检验在进行判断分类依据的字典结果如下:
{'<=50K':3}
{'<=50K':4}
{'<=50K':5}
…
{'<=50K':7}
{'<=50K':7, '>50K': 1}
{'<=50K':7, '>50K': 2}
…
{'<=50K':7, '>50K': 5}
{'<=50K':8, '>50K': 5}
{'<=50K':9, '>50K': 5}
…
{'<=50K':13, '>50K': 6}
由此可判断分类效果不明显。
决策树和朴素贝叶斯都是使用同样的标称属性进行训练,根据结果反应决策树的正确率比朴素贝叶斯的正确率高。但在进行决策树训练时,产生分支太多没有进行处理,可以进行提前剪枝的处理。