自动可视化报表搭建项目
一、项目基本信息
目的:给某互联网客服中心搭建自动可视化报表供运营层使用;
使用对象:运营总监、经理、主管; 此使用对象决定底层表最小粒度;
该项目使用工具:Hive sql、MySQL、Python、power BI、Windows自带任务计划程序;
方案:
- 使用hive SQL从公司内部大数据平台或生产系统获取最新底层数据,存入不同文件夹;
- 使用Python将各文件夹中最新文件导入mysql对应表;
- 使用Windows自带任务计划程序实现2的每日定时执行;
- 使用power BI连接本地MySQL获取底层数据,通过power BI设计可视化报表;
- 使用Python及任务计划程序每日按时推送可视化报表,无需人工操作;
二、数据的获取、清洗、处理
结合使用对象,用SQL获取你想要的原始数据,比如使用对象决定表的最小粒度是员工层,但是向上钻需要到小组、大组、部门、整个客服中心,所以前面提到的这几个字段都是需要的;另外如果想展示sku的top咨询情况,那么就需要到sku粒度;一般情况下如果只是量与量直接做计算,不涉及具体的咨询id或者订单号,推荐先将各字段group by后再进行full join,这时候会得到一张大宽表,在这个宽表上再进行加减乘除的指标运算;
在这里我有用到只有工作量的表,同时也会有明细,因为对于待跟进case员工是需要one by one的跟进的;如:
- 1是最小粒度为员工,且只有工作量及总时长,这种情况可以通过工作量进行想要指标的运算,例如average response time= sum(response_time)/sum(case_resolved_quantity)

- 2是最小粒度到某个具体的服务单或者订单或者咨询ID,因为这个不仅要展示待跟进是多少,同时需要具体的单号;

三、自动导入文件夹中的最新文档至MySQL
- Python导入脚本:这里一共有两个文档需要导入,可以同时执行;
import pandas as pd
import os
from sqlalchemy import create_engine
file_dir=u'D:\\桌面\\印尼\\file from jbox\\for mysql\\pending_detail_for_mysql\\'
list1=os.listdir(file_dir)
list1.sort(key=lambda fn: os.path.getmtime(file_dir+fn) if not os.path.isdir(file_dir+fn) else 0)
a=file_dir+list1[-1]
op=open(a,'rb')
data=pd.read_csv(op,encoding='utf-8')
connerting=create_engine('mysql+pymysql://root:031710Trplb@@localhost:3306/idcs?charset=utf8')
pd.io.sql.to_sql(data,'afs_pending_audit_final', connerting, schema='idcs', if_exists='append',index=False)
op.close()
file_dir=u'D:\\桌面\\印尼\\file from jbox\\case_qty_daily\\'
list1=os.listdir(file_dir)
list1.sort(key=lambda fn: os.path.getmtime(file_dir+fn) if not os.path.isdir(file_dir+fn) else 0)
a=file_dir+list1[-1]
op=open(a,'rb')
data=pd.read_csv(op,encoding='utf-8')
connerting=create_engine('mysql+pymysql://root:031710Trplb@@localhost:3306/idcs?charset=utf8')
pd.io.sql.to_sql(data,'case_quantity', connerting, schema='idcs', if_exists='append',index=False)
op.close()代码解析:
import:导入pandas、os、sqlalchemy库;
os.listdir():列出路径里面的所有文件;
list1.sort(key=lambda fn: os.path.getmtime(file_dir+fn) if not os.path.isdir(file_dir+fn) else 0)
a=file_dir+list1[-1]
这两句是找到创建时间最新的那个文件;
open():打开文件,后面参数rb,已只读形式打开;
pd.read_csv():文件是CSV的,所以会用这个把打开的文件读取到dataframe里,当然如果是excel文件或者其他的,也可以用对应的读取方法;
create_engine:这里是我的本地mysql的账号等信息,按格式填进去即可;
create_engine('mysql+pymysql://root:031710Trplb@@localhost:3306/idcs?charset=utf8')
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'to_sql:
pd.io.sql.to_sql(data,'afs_pending_audit_final', connerting, schema='idcs', if_exists='append',index=False)
调取pd.io.sql.to_sql这个函数,将之前的dataframe文件data按连接connerting(我之前定义的)导入到mysql中库名为“idcs” 表名为“afs_pending_audit_final”表中,导入方式append为如果库中没有这个表则新建一个表,如果有则在最后增加你导入的内容,index=false表明不把dataframe里面的index列一起导入;*这里需要注意的是,使用sqlalchemy需要先安装,下载地址点击这里,安装方法点击这里;
另外,因为自动导入mysql会自己给字段选一种类型,所以需要在表设计中修改,我都统一改为varchar;
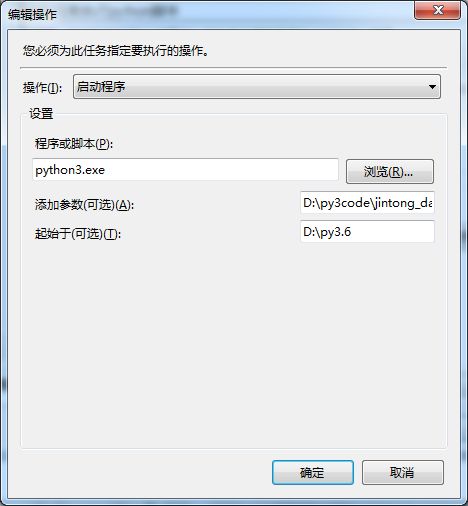
- 自动执行:使用Windows自带任务计划程序,任务计划程序位置:控制面板>管理工具>任务计划程序>创建任务,然后就可以新建任务-设置每日执行-操作为启动程序,其中:
程序或脚本是python解释器的名称;起始于是python解释器的目录;添加参数是你的python程序的完整路径
以上,底层数据算是搭建好了,下面要进行可视化设计;
四、power BI