Oracle 数据同步至 Elasticsreach
数据同步使用的是:logstash
官方文档:
https://www.elastic.co/guide/en/logstash/7.6/plugins-inputs-jdbc.html
环境准备:
elasticsearch7.6、kibana7.6、logstash7.6.
这里没必要用docker, 因为太过麻烦, 只有依赖过多时,使用docker才方便。
oracle 版本:

对应的jar版本:

将jar包下载,上传至logstash/lib
新建一个jar文件夹。

在/software/es/logstash-7.6.0/config 目录下新建logstash.json的配置文件: logstash.json
转载: https://blog.csdn.net/u014646662/article/details/94736551
这个文件指定分片数量, 分词器等等。 将如下内容加入 logstash.json 文件中:
"shards": 主分片数量
"template": "*",是匹配所有索引的意思,
如果只想匹配以test-开头的索引, "template": "test-*"
"analyzer": "ik_smart",这里用的是ik分词器,如果想是有其他分词器,在这里修改即可
"match": "*",匹配字段名
"date_detection": true,识别日期类型
"numeric_detection": true,识别数字类型
{
"index_patterns": ["*"],
"order" : 0,
"version": 1,
"settings": {
"number_of_shards": 5,
"number_of_replicas":3
},
"mappings": {
"date_detection": true,
"numeric_detection": true,
"dynamic_templates": [
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false,
"analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
]
}
}
在/software/es/logstash-7.6.0/config 目录下新建表名的配置文件: xxx.conf
将如下内容加入, 修改自己的路径, 表名。 这里使用的是更新时间判断数据是否修改。
配置转载: https://blog.csdn.net/huan_lxyd/article/details/103547686
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input{
jdbc{
# 数据库驱动包存放路径
# 此处遇到坑
jdbc_driver_library => "/software/es/logstash-7.6.0/lib/jar/ojdbc8-12.2.0.1.jar"
# 数据库驱动器;
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
# 数据库连接方式
jdbc_connection_string => "jdbc:oracle:thin:@192.168.10.128:1521/test"
# 数据库用户名
jdbc_user => "tests"
# 数据库密码
jdbc_password => "tests"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600s
jdbc_validation_timeout => "3600"
# 开启分页查询(默认false不开启)
jdbc_paging_enabled => "true"
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值)
jdbc_page_size => "1000"
# statement为查询数据sql,如果sql较复杂,建议通过statement_filepath配置sql文件的存放路径
# statement_filepath => "E:\STUDY\elasticsearch\oralce2es\logstash-7.5.0\config\querysql.sql"
# sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为rowid
statement => "SELECT * FROM T_TEST_JJDB WHERE GXSJ > :sql_last_value"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值
use_column_value => true
# 查询结果某字段的数据类型,仅包括numeric和timestamp,默认为numeric
tracking_column_type => timestamp
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "GXSJ"
# 记录上次执行结果数据的存放位置
last_run_metadata_path => "/software/es/logstash-7.6.0/path/jjdblast.log"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false
clean_run => false
# 同步频率(分 时 天 月 年),默认每分钟同步一次
schedule => "* * * * *"
# ES索引的type
#type => "_doc"
}
}
output{
elasticsearch{
# ES地址,集群中多个地址可用数组形式:hosts => ["192.168.1.1:9200", "192.168.1.2:9200"]
hosts => "192.168.10.xxx:9200"
# 索引名称
index => "jjdb"
# 数据唯一索引(建议同数据库表的唯一ID对应)
document_id => "%{JJDBID}"
#模版名称
template_name => "logstash"
#模版文件路径
template => "/software/es/logstash-7.6.0/config/logstash.json"
#模版如果存在, 则覆盖
template_overwrite => true
#管理模版
manage_template => true
}
}
2: 在/software/es/logstash-7.6.0/config/pipelines.yml 文件中加入刚刚创建的xxx.conf文件路径。
如果是多个表,就创建多个 xxx.conf, 然后在pipelines.yml 的 pipeline.id 中配置路径。多个xx.conf就多个pipeline.id,path.config

3: 启动logstash:
./../bin/logstash -f 需要指定 xxx.conf, 没有指定xxx.conf则默认使用pipelines.yml中的配置。
报如下错误就是:
数据库驱动jdbc_driver_class前面少了Java::,导致启动报错:oracle.jdbc.driver.OracleDriver not loaded. Are you sure you’ve included the correct jdbc driver in :jdbc_driver_library?

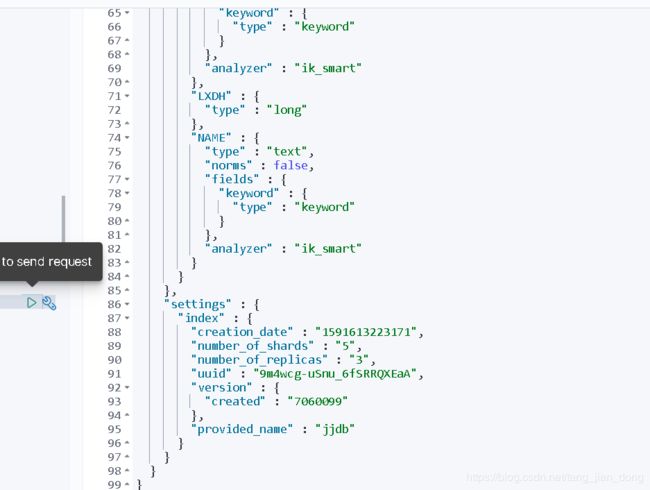
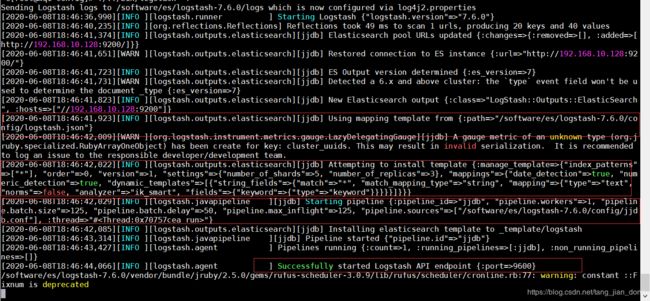
如下为启动成功, logstash.json, pipe 都成功, 并执行sql.
kibana 中看见索引已经创建了。
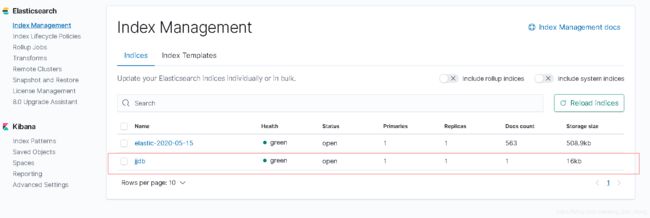
kibana中, 分片数量, 分词器都是配置文件中配置的。 至此同步完成。