一.前言
前文探究了非阻塞算法的实现ConcurrentLinkedQueue安全队列,也说明了阻塞算法实现的两种方式,使用一把锁(出队和入队同一把锁ArrayBlockingQueue)和两把锁(出队和入队各一把锁LinkedBlockingQueue)来实现,今天来探究下ArrayBlockingQueue。
ArrayBlockingQueue是一个阻塞队列,底层使用数组结构实现,按照先进先出(FIFO)的原则对元素进行排序。
ArrayBlockingQueue是一个线程安全的集合,通过ReentrantLock锁来实现,在并发情况下可以保证数据的一致性。
此外,ArrayBlockingQueue的容量是有限的,数组的大小在初始化时就固定了,不会随着队列元素的增加而出现扩容的情况,也就是说ArrayBlockingQueue是一个“有界缓存区”。
从下图可以看出,ArrayBlockingQueue是使用一个数组存储元素的,当向队列插入元素时,首先会插入到数组下标索引为6的位置,再有新元素进来时插入到索引为7的位置,依次类推,如果满了就不会再插入。
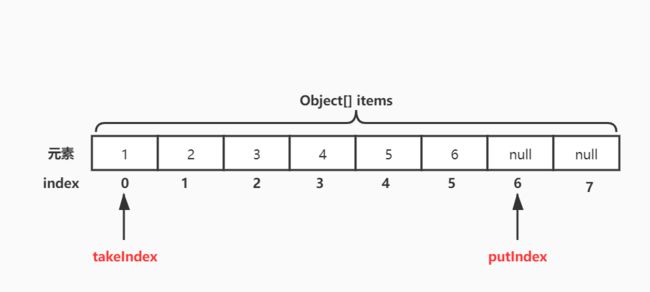
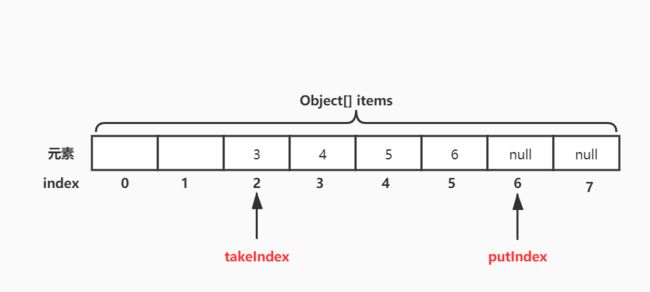
当元素出队时,先移除索引为2的元素3,与入队一样,依次类推,移除索引3、4、5...上的元素。这也形成了“先进先出”。
二.源码解析
-
构造方法
public class ArrayBlockingQueue
extends AbstractQueue implements BlockingQueue , java.io.Serializable { //队列实现:数组 final Object[] items; //当读取元素时数组的下标(下一个被取出元素的索引) int takeIndex; //添加元素时数组的下标 (下一个被添加元素的索引) int putIndex; //队列中元素个数: int count; //可重入锁: final ReentrantLock lock; //入队操作时是否让线程等待 private final Condition notEmpty; //出队操作时是否让线程等待 private final Condition notFull; /** * 初始化队列容量构造:由于公平锁会降低队列的性能,因而使用非公平锁(默认)。 */ public ArrayBlockingQueue(int capacity) { this(capacity, false); } //带初始容量大小和公平锁队列(公平锁通过ReentrantLock实现): public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } } -
在多线程中,默认不保证线程公平的访问队列;
-
在ArrayBlockingQueue中为了保证数据的安全,使用了ReentrantLock锁。由于锁的引入,导致了线程之间的竞争。当有一个线程获取到锁时,其余线程处于等待状态。当锁被释放时,所有等待线程为夺锁而竞争;
-
锁有公平锁和非公平锁:
-
公平锁:等待的线程在获取锁而竞争时,按照等待的先后顺序FIFO进行获取操作;公平锁可以应用在比如并发下的日志输出队列中,保证了日志输出的顺序完整性;
-
优点:等待锁的线程不会饿死,和非公平锁相比,在获得锁和保证锁分配的均衡性差异较小;
-
缺点:使用公平锁的程序在多线程访问时表现为很低的吞吐量(即速度很慢),等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁的大;公平锁不能保证线程调度的公平性,因此,使用公平锁的众多线程中的一员可能获得多倍的成功机会,这种情况发生在其他活动线程没有被处理并且目前并未持有锁时【ReentrantLock源码对公平锁的定义】;
Note however, that fairness of locks does not guarantee fairness of thread scheduling. Thus, one of many threads using a fair lock may obtain it multiple times in succession while other active threads are not progressing and not currently holding the lock.
-
上面这句话有重入锁的概念,一个线程可以在已经获取锁的情况下再次进入获取到锁,不需要竞争;同时,如果一个线程获取到了锁,然后释放,在其他线程来获取之前再次是可以获取到锁的。
A: Request Lock -> Release Lock -> Request Lock Again (Succeeds) B: Request Lock (Denied)... ----------------------- Time --------------------------------->
-
-
-
非公平锁:在获取锁时,无论是先等待还是后等待的线程,均有可能获取到锁。即根据抢占机制,是随机获取锁的,和公平锁不一样的是先来的不一定能获取到锁,有可能一直拿不到锁,这样会造成“饥饿”现象;
-
优点:非公平锁性能高于公平锁性能。首先,在恢复一个被挂起的线程与该线程真正运行之间存在着严重的延迟,而且,非公平锁更能充分的利用CPU的时间片,尽量减少CPU空闲的状态时间;即可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获取到锁,CPU不必唤醒其他所有线程;
-
缺点:处于等待队列中的线程可能会饿死或者等很久才会获得锁;
-
-
产生“饥饿”的原因:
-
高优先级吞噬所有低优先级的CPU时间片,优先级越高,就会获得越高的CPU执行机会; ---> 使用默认的优先级;
-
线程被永久阻塞在一个等待进入同步块synchronized的状态(长时间执行) ,同时synchronized并不保障等待线程的顺序(锁释放后,随机竞争,由OS调度),这会存在一个可能是某个线程总是抢锁抢不到导致一直等待状态 ---> 避免持有锁的线程长时间执行、使用显示lock来代替synchronized;
synchronized(obj) { while (true) { // .... infinite loop }
-
等待的线程永远不被唤醒:如果多个线程处在wait方法执行上,而对其调用notify方法不会保证哪一个线程会获得唤醒,唤醒是无序的,跟VM/OS调度有关,甚至底层是随机选取一个或是队列中的第一个,任何线程都有可能处于继续等待的状态,因此存在这样一个风险,即一个等待线程从来得不到唤醒,因为其他等待线程总是能被获得唤醒 ---> 使用显示lock来代替synchronized;
-
-
比如ReentrantLock:
-
在公平锁中,如果有另一个线程持有锁或者有其他线程在等待队列中等待这个锁,那么新发出的请求的线程将被放入到队列中;
-
非公平锁中, 根据抢占机制,拥有锁的线程在释放锁资源的时候, 新发出请求的线程可以和等待队列中的第一个线程竞争锁资源, 新线程竞争失败才放入队列中,但是已经进入等待队列的线程, 依然是按照先进先出的顺序获取锁资源;
-
-
-
-
入队:有阻塞式和非阻塞式
-
阻塞式:当队列中的元素已满时,则会将此线程停止,让其处于等待状态,直到队列中有空余位置产生
public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly();//获取锁 try { //队列中元素 == 数组长度(队列满了),则线程等待 while (count == items.length) notFull.await(); enqueue(e);//元素加入队列 } finally { lock.unlock();//释放锁 } }
-
lockInterruptibly:
-
如果当前线程未被中断,则获取锁。
-
如果该锁没有被另一个线程保持,则获取该锁并立即返回,将锁的保持计数设置为 1。
-
如果当前线程已经保持此锁,则将保持计数加 1,并且该方法立即返回。
-
如果锁被另一个线程保持,则出于线程调度目的,禁用当前线程,并且在发生以下两种情况之一以前,该线程将一直处于休眠状态:1)锁由当前线程获得;2)其他某个线程中断当前线程
-
-
-
非阻塞式:当队列中的元素已满时,并不会阻塞此线程的操作,而是让其返回又或者是抛出异常
public boolean add(E e) { return super.add(e);// AbstractQueue.add } public boolean add(E e) { if (offer(e))//调用实现接口 return true; else throw new IllegalStateException("Queue full"); } public boolean offer(E e) { checkNotNull(e);//检测是否有空指针异常 final ReentrantLock lock = this.lock;//获得锁对象 lock.lock();//加锁 try { //如果队列满了,返回false if (count == items.length) return false; else { //元素加入队列 enqueue(e); return true; } } finally { lock.unlock();//释放锁 } } private void enqueue(E x) { // assert lock.getHoldCount() == 1; // assert items[putIndex] == null; //获得数组 final Object[] items = this.items; //槽位填充元素 items[putIndex] = x; //获得下一个被添加元素的索引,如果值等于数组长度,表示到达尾部了,需要从头开始填充 if (++putIndex == items.length) putIndex = 0; count++;//数量+1 notEmpty.signal();//唤醒出队上的等待线程,表示有元素可以消费了 }
-
enqueue中++putIndex == items.length,putIndex=0:这是因为当前队列执行元素出队时总是从队列头部获取,而添加元素的索引从队列尾部获取所以当队列索引(从0开始)与数组长度相等时,下次我们就需要从数组头部开始添加了
-
-
阻塞式和非阻塞式的结合:offer(E e, long timeout, TimeUnit unit),向队列尾部添加元素,可以设置线程等待时间,如果超过指定时间队列还是满的,则返回false;
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException { checkNotNull(e);//检测是否为空 long nanos = unit.toNanos(timeout);//转换成超时时间阀值 final ReentrantLock lock = this.lock; lock.lockInterruptibly();//加锁 try { //队列是否满了的判断 while (count == items.length) { if (nanos <= 0)//等待超时结束返回false return false; nanos = notFull.awaitNanos(nanos);//队列满了,等待出队有空位填充 } enqueue(e);//加入队列中 return true; } finally { lock.unlock();//释放锁 } }
-
-
出队:同样有阻塞式和非阻塞式
-
阻塞式:当队列中的元素已空时,则会将此线程停止,让其处于等待状态,直到队列中有元素插入
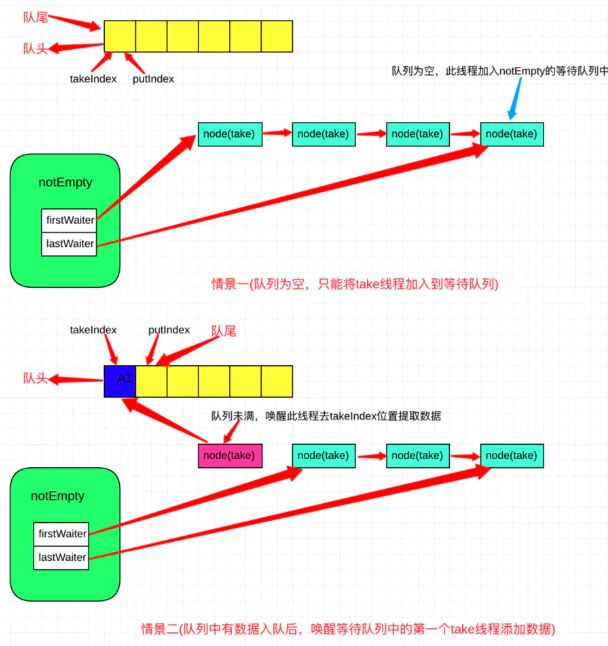
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { //队列为空,进行等待 while (count == 0) notEmpty.await(); return dequeue();//返回出队元素 } finally { lock.unlock(); } }
-
非阻塞式:当队列中的元素已满时,并不会阻塞此线程的操作,而是让其返回null或元素【里面的迭代器比较复杂,留待下文探究】
public E poll() { final ReentrantLock lock = this.lock; lock.lock(); try { //队列为空,返回null,否则返回元素 return (count == 0) ? null : dequeue(); } finally { lock.unlock(); } } private E dequeue() { // assert lock.getHoldCount() == 1; // assert items[takeIndex] != null; final Object[] items = this.items;//获得队列 @SuppressWarnings("unchecked") E x = (E) items[takeIndex];//获得出队元素 items[takeIndex] = null;//出队槽位元素置为null //下一个被取出元素的索引+1,如果值等于长度,表示后面没有元素了,需要从头开始取出 if (++takeIndex == items.length) takeIndex = 0; count--;//数量-1 if (itrs != null)//迭代器不为空 itrs.elementDequeued();//同时更新迭代器中的元素数据 notFull.signal();//唤醒入队线程 return x;//返回出队元素 }
-
阻塞式和非阻塞式的结合:poll(long timeout, TimeUnit unit),出队获取元素,可以设置线程等待时间,如果超过指定时间队列还是空的,则返回null;
public E poll(long timeout, TimeUnit unit) throws InterruptedException { long nanos = unit.toNanos(timeout);//转换成超时时间阀值 final ReentrantLock lock = this.lock; lock.lockInterruptibly();//加锁 try { while (count == 0) {//队列空了,等待 if (nanos <= 0)//超时了返回null return null; nanos = notEmpty.awaitNanos(nanos);//等待入队填充元素 } return dequeue();//返回出队元素 } finally { lock.unlock();//释放锁 } }
-
-
移除元素remove:
public boolean remove(Object o) { //要移除的元素为空返回false if (o == null) return false; //获得队列数组 final Object[] items = this.items; final ReentrantLock lock = this.lock; lock.lock();//加锁 try { //队列有元素 if (count > 0) { final int putIndex = this.putIndex;//获得下一个被添加元素的索引 int i = takeIndex;//下一个被取出元素的索引 do { if (o.equals(items[i])) {//从takeIndex下标开始,找到要被删除的元素 removeAt(i);//移除 return true; } if (++i == items.length)//下一个被取出元素的索引+1并判断是否等于队列长度,如果是,表示需要从头开始遍历 i = 0; } while (i != putIndex);//继续查找,直到找到最后一个元素 } return false; } finally { lock.unlock();//解锁 } } /** * 根据下标移除元素,那么会分成两种情况一个是移除的是队首元素,一个是移除的是非队首元素,移除队首元素,就相当于出队操作, * 移除非队首元素那么中间就有空位了,后面元素需要依次补上,然后如果是队尾元素,那么putIndex也就是插入操作的下标也就需要跟着移动。 */ void removeAt(final int removeIndex) { // assert lock.getHoldCount() == 1; // assert items[removeIndex] != null; // assert removeIndex >= 0 && removeIndex < items.length; final Object[] items = this.items;//获得队列 if (removeIndex == takeIndex) {//移除的是队首元素 // removing front item; just advance items[takeIndex] = null;//队首置为null if (++takeIndex == items.length)//下一个被取出元素的索引+1并判断是否等于队列长度 takeIndex = 0; count--;//数量-1 if (itrs != null)//迭代器不为空 itrs.elementDequeued();//更新迭代器元素 } else {//移除的不是队首元素,而是中间元素 // an "interior" remove // slide over all others up through putIndex. final int putIndex = this.putIndex;//下一个被添加元素的索引 for (int i = removeIndex;;) {//对队列进行遍历,因为是队列中间的值被移除了,所有后面的元素都要挨个迁移 int next = i + 1;//获取移除元素的下一个坐标 if (next == items.length)//判断是否等于队列长度 next = 0; if (next != putIndex) {//获取移除元素的下一个坐标!=下一个被添加元素的索引,表示移除元素的索引后面有值 items[i] = items[next];//当前要移除的元素置为后面的元素,即对后面的元素往前迁移,覆盖要移除的元素 i = next;//下一个迁移的索引 } else {//移除的元素是最后一个,后面没有值了 items[i] = null;//移除元素,直接置为null this.putIndex = i;//更新下一个被添加元素的索引 break;//结束 } } count--;//数量-1 if (itrs != null)//迭代器不为空 itrs.removedAt(removeIndex);//更新迭代器元素 } notFull.signal();//唤醒入队线程,可以添加元素了 }
-
清空元素clear:用于清空ArrayBlockingQueue,并且会释放所有等待notFull条件的线程(存放元素的线程)
public void clear() { final Object[] items = this.items;//获得队列 final ReentrantLock lock = this.lock; lock.lock(); try { int k = count;//获取元素数量 if (k > 0) {//有元素,表示队列不为空 final int putIndex = this.putIndex;//下一个被添加元素的索引 int i = takeIndex;//下一个被取出元素的索引 do { items[i] = null;//对每个有元素的槽位置为null if (++i == items.length) i = 0; } while (i != putIndex);//从有元素的第一个槽位开始遍历,直到槽位元素为null takeIndex = putIndex;//更新取出和添加的索引 count = 0;//数量更新为0 if (itrs != null)//迭代器不为空 itrs.queueIsEmpty();//更新迭代器为空 //若有等待notFull条件的线程,则逐一唤醒 for (; k > 0 && lock.hasWaiters(notFull); k--) notFull.signal();//唤醒入队线程,可以添加元素了 } } finally { lock.unlock(); } }
-
offer(E e, long timeout, TimeUnit unit)和poll(long timeout, TimeUnit unit)里面有awaitNanos,下面探讨该功能实现:对当前线程或等待的入/出队线程进行挂起,如果有入/出队操作进行了唤醒出/入队操作,则acquireQueued自旋获取到锁,然后出/入队中的ReentrantLock是重入锁,可以重入获取到锁进行出/入队操作
AbstractQueuedSynchronizer: //进行超时控制 public final long awaitNanos(long nanosTimeout) throws InterruptedException { //如果当前线程中断了抛出中断异常 if (Thread.interrupted()) throw new InterruptedException(); //当前线程加入到Condition队列中 Node node = addConditionWaiter(); //锁释放是否成功:释放当前线程的lock,从AQS的队列中移出 int savedState = fullyRelease(node); //到达等待时间点 final long deadline = System.nanoTime() + nanosTimeout; //中断标识 int interruptMode = 0; //当前节点是否在同步队列中,否表示不在,进入挂起判断操作,如果已经在Sync队列中,则退出循环 //那什么时候会把当前线程又加入到Sync队列中呢?当然是调用signal方法的时候,因为这里需要唤醒之前调用await方法的线程,唤醒之后进行下面的获取锁等操作 while (!isOnSyncQueue(node)) { //如果超时了,将线程挂起,然后停止遍历 if (nanosTimeout <= 0L) { transferAfterCancelledWait(node); break; } //如果等待时间间隔超过了1000,继续挂起 if (nanosTimeout >= spinForTimeoutThreshold) LockSupport.parkNanos(this, nanosTimeout); //线程中断了停止遍历 if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; //获得剩余的等待时间间隔 nanosTimeout = deadline - System.nanoTime(); } //结束挂起,acquireQueued自旋对当前线程的队列出队进行获取锁并返回线程是否中断 //如果线程被中断,并且中断的方式不是抛出异常,则设置中断后续的处理方式设置为REINTERRUPT if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT;//中断标识更新为退出等待时重新中断 if (node.nextWaiter != null)//当前节点后面还有节点,多并发操作了 unlinkCancelledWaiters();//从头到尾遍历Condition队列,移除被cancel的节点 //如果线程已经被中断,则根据之前获取的interruptMode的值来判断是继续中断还是抛出异常 if (interruptMode != 0) reportInterruptAfterWait(interruptMode); return deadline - System.nanoTime();//返回剩余等待时间 }
-
drainTo可以一次性获取队列中所有的元素,它减少了锁定队列的次数,使用得当在某些场景下对性能有不错的提升
//最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定collection中 public int drainTo(Collectionsuper E> c) { return drainTo(c, Integer.MAX_VALUE); } public int drainTo(Collectionsuper E> c, int maxElements) { checkNotNull(c);//检查是否为空 if (c == this)//如果集合类型相同抛出参数异常 throw new IllegalArgumentException(); if (maxElements <= 0)//如果给定移除数量小于0,返回0,表示不做移除操作 return 0; final Object[] items = this.items;//获得队列 final ReentrantLock lock = this.lock; lock.lock();//加锁 try { int n = Math.min(maxElements, count);//获得元素的最小数量 int take = takeIndex;//下一个被取出元素的索引 int i = 0; try { while (i < n) {//遍历移除和添加 @SuppressWarnings("unchecked") E x = (E) items[take];//获得移除元素 c.add(x);//元素添加到直到集合中 items[take] = null;//元素原先队列位置置为null if (++take == items.length)//如果取出索引到达尾部,从头开始遍历取出 take = 0; i++;//移除的数量+1,如果达到了移除的最小数量,结束遍历 } return n;//返回一共移除并添加了多少个元素 } finally { // Restore invariants even if c.add() threw if (i > 0) {//如果有移除操作 count -= i;//队列元素数量-i takeIndex = take;//重置下一个被取出元素的索引 if (itrs != null) {//迭代器不为空 if (count == 0)//队列空了 itrs.queueIsEmpty();//迭代器清空 else if (i > take)//说明take中间变成0了,通知itr itrs.takeIndexWrapped(); } //唤醒在因为队列满而等待的入队线程,最多唤醒i个,避免线程被唤醒了因为队列又满了而阻塞 for (; i > 0 && lock.hasWaiters(notFull); i--) notFull.signal(); } } } finally { lock.unlock(); } }
三.Logback 框架中异步日志打印中ArrayBlockingQueue的使用
-
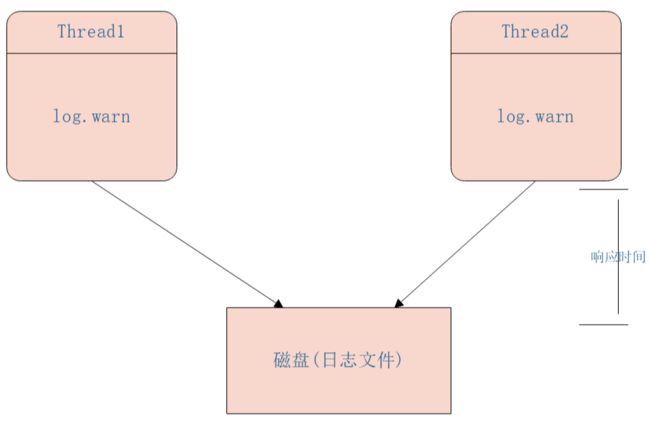
在高并发并且响应时间要求比较小的系统中同步打日志已经满足不了需求了,这是因为打日志本身是需要同步写磁盘的,会造成 响应时间 增加,如下图同步日志打印模型为:
-
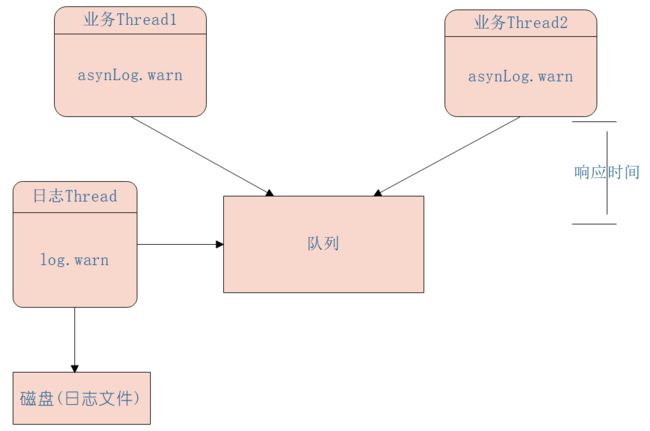
异步模型是业务线程把要打印的日志任务写入一个队列后直接返回,然后使用一个线程专门负责从队列中获取日志任务写入磁盘,其模型具体如下图:
-
如图可知其实 logback 的异步日志模型是一个多生产者单消费者模型,通过使用队列把同步日志打印转换为了异步,业务线程调用异步 appender 只需要把日志任务放入日志队列,日志线程则负责使用同步的 appender 进行具体的日志打印到磁盘;
-
-
接下来看看异步日志打印具体实现,要把同步日志打印改为异步需要修改 logback 的 xml 配置文件:
<appender name="PROJECT" class="ch.qos.logback.core.FileAppender"> <file>project.logfile> <encoding>UTF-8encoding> <append>trueappend> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>project.log.%d{yyyy-MM-dd}fileNamePattern> <maxHistory>7maxHistory> rollingPolicy> <layout class="ch.qos.logback.classic.PatternLayout"> <pattern> %n%-4r [%d{yyyy-MM-dd HH:mm:ss}] %X{productionMode} - %X{method} %X{requestURIWithQueryString} [ip=%X{remoteAddr}, ref=%X{referrer}, ua=%X{userAgent}, sid=%X{cookie.JSESSIONID}]%n %-5level %logger{35} - %m%n]]> pattern> layout> appender> <appender name="asyncProject" class="ch.qos.logback.classic.AsyncAppender"> <discardingThreshold>0discardingThreshold> <queueSize>1024queueSize> <neverBlock>trueneverBlock> <appender-ref ref="PROJECT" /> appender> <logger name="PROJECT_LOGGER" additivity="false"> <level value="WARN" /> <appender-ref ref="asyncProject" /> logger>
-
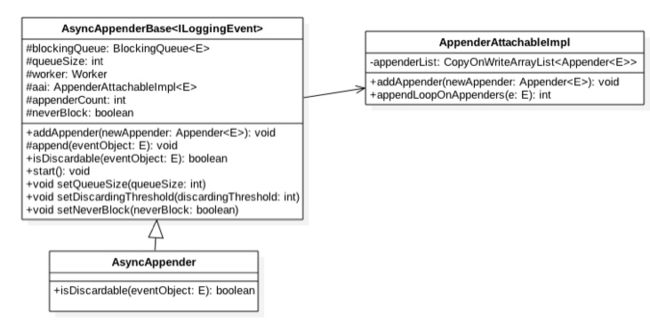
从上面可知 AsyncAppender 是实现异步日志的关键,下面探究它的原理:
-
如上图可知 AsyncAppender 继承自 AsyncAppenderBase,其中后者具体实现了异步日志模型的主要功能,前者只是重写了其中的一些方法。另外从类图可知 logback 中的异步日志队列是一个阻塞队列, 后面会知道其实是一个有界阻塞队列 ArrayBlockingQueue, 其中 queueSize 是有界队列的元素个数默认为 256;
-
worker则是工作线程,也就是异步打印日志的消费者线程,aai则是一个appender的装饰器,里边存放的同步日志的appender,其中appenderCount记录aai里边附加的同步appender的个数(这个和配置文件相对应,一个异步的appender对应一个同步的appender),neverBlock用来指示当同步队列已满时是否阻塞打印日志线程(如果配置neverBlock=true,当队列满了之后,后面阻塞的线程想要输出的消息就直接被丢弃,从而线程不会阻塞),discardingThreshold是一个阈值,当日志队列里边的空闲元素个数小于该值时,新来的某些级别的日志就会直接被丢弃。
-
-
接下来看下何时创建的日志队列以及何时启动的消费线程,这需要看下 AsyncAppenderBase 的 start 方法,该方法是在解析完毕配置 AsyncAppenderBase 的 xml 的节点元素后被调用 :
public void start() { if (isStarted()) return; if (appenderCount == 0) { addError("No attached appenders found."); return; } if (queueSize < 1) { addError("Invalid queue size [" + queueSize + "]"); return; } // 创建一个ArrayBlockingQueue阻塞队列,queueSize默认为256,创建阻塞队列的原因是:防止生产者过多,造成队列中元素过多,产生OOM异常 blockingQueue = new ArrayBlockingQueue
(queueSize); // 如果discardingThreshold未定义的话,默认为queueSize的1/5 if (discardingThreshold == UNDEFINED) discardingThreshold = queueSize / 5; addInfo("Setting discardingThreshold to " + discardingThreshold); // 将工作线程设置为守护线程,即当jvm停止时,即使队列中有未处理的元素,也不会在进行处理 worker.setDaemon(true); // 为线程设置name便于调试 worker.setName("AsyncAppender-Worker-" + getName()); // make sure this instance is marked as "started" before staring the worker Thread // 启动线程 super.start(); worker.start(); } -
logback 使用的队列是有界队列 ArrayBlockingQueue,之所以使用有界队列是考虑到内存溢出问题,在高并发下写日志的 qps 会很高如果设置为无界队列队列本身会占用很大内存,很可能会造成 内存溢出。
-
这里消费日志队列的 worker 线程被设置为了守护线程,意味着当主线程运行结束并且当前没有用户线程时候该 worker 线程会随着 JVM 的退出而终止,而不管日志队列里面是否还有日志任务未被处理。另外这里设置了线程的名称是个很好的习惯,因为这在查找问题的时候很有帮助,根据线程名字就可以定位到是哪个线程。
-
-
既然是有界队列那么肯定需要考虑如果队列满了,该如何处置,是丢弃老的日志任务,还是阻塞日志打印线程直到队列有空余元素那?下面看append 方法:
protected void append(E eventObject) { // 判断队列中的元素数量是否小于discardingThreshold,如果小于的话,并且日志等级小于info的话,则直接丢弃这些日志任务 if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { return; } preprocess(eventObject); // 日志入队 put(eventObject); } private boolean isQueueBelowDiscardingThreshold() { return (blockingQueue.remainingCapacity() < discardingThreshold); } // 子类重写的方法 判断日志等级 protected boolean isDiscardable(ILoggingEvent event) { Level level = event.getLevel(); return level.toInt() <= Level.INFO_INT; }
-
日志入队put:从下面可知如果 neverBlock 设置为 false(默认为 false)则会调用阻塞队列的 put 方法,而 put 是阻塞的,也就是说如果当前队列满了,如果再企图调用 put 方法向队列放入一个元素则调用线程会被阻塞直到队列有空余空间。这里有必要提下其中blockingQueue.put(eventObject)当日志队列满了的时候 put 方法会调用 await() 方法阻塞当前线程,如果其它线程中断了该线程,那么该线程会抛出 InterruptedException 异常,那么当前的日志任务就会被丢弃了。如果 neverBlock 设置为了 true 则会调用阻塞队列的 offer 方法,而该方法是非阻塞的,如果当前队列满了,则会直接返回,也就是丢弃当前日志任务。
private void put(E eventObject) { // 判断是否阻塞(默认为false),则会调用阻塞队列的put方法 if (neverBlock) { blockingQueue.offer(eventObject); } else { putUninterruptibly(eventObject); } } // 可中断的阻塞put方法 private void putUninterruptibly(E eventObject) { boolean interrupted = false; try { while (true) { try { blockingQueue.put(eventObject); break; } catch (InterruptedException e) { interrupted = true; } } } finally { if (interrupted) { Thread.currentThread().interrupt(); } } }
-
-
最后看下 addAppender 方法,可以看出,一个异步的appender只能绑定一个同步appender,这个appender会被放入AppenderAttachableImpl的appenderList列表里边
public void addAppender(Appender
newAppender) { if (appenderCount == 0) { appenderCount++; addInfo("Attaching appender named [" + newAppender.getName() + "] to AsyncAppender."); aai.addAppender(newAppender); } else { addWarn("One and only one appender may be attached to AsyncAppender."); addWarn("Ignoring additional appender named [" + newAppender.getName() + "]"); } } -
通过上面我们已经分析完了日志生产线程放入日志任务到日志队列的实现,下面一起来看下消费线程是如何从队列里面消费日志任务并写入磁盘的,由于消费线程是一个线程,那就从 worker 的 run 方法看起(消费者,将日志写入磁盘的线程方法):
class Worker extends Thread { public void run() { AsyncAppenderBase
parent = AsyncAppenderBase.this; AppenderAttachableImpl aai = parent.aai; // loop while the parent is started 一直循环知道线程被中断 while (parent.isStarted()) { try {// 从阻塞队列中获取元素,交由给同步的appender将日志打印到磁盘 E e = parent.blockingQueue.take(); aai.appendLoopOnAppenders(e); } catch (InterruptedException ie) { break; } } addInfo("Worker thread will flush remaining events before exiting. "); //执行到这里说明该线程被中断,则把队列里边的剩余日志任务刷新到磁盘 for (E e : parent.blockingQueue) { aai.appendLoopOnAppenders(e); parent.blockingQueue.remove(e); } aai.detachAndStopAllAppenders(); } } -
try逻辑中从日志队列使用 take 方法获取一个日志任务,如果当前队列为空则当前线程会阻塞到 take 方法直到队列不为空才返回,获取到日志任务后会调用 AppenderAttachableImpl 的 aai.appendLoopOnAppenders 方法,该方法会循环调用通过 addAppender 注入的同步日志 appener 具体实现日志打印到磁盘的任务。
-
四.参考:
- 公平锁的使用场景:https://stackoverflow.com/questions/26455578/when-to-use-fairness-mode-in-java-concurrency
- 公平锁和非公平锁的区别的提问:https://segmentfault.com/q/1010000006439146
- 公平锁不能保证线程调度的公平性:https://stackoverflow.com/questions/60903107/understanding-fair-reentrantlock-in-java
- logback异步日志打印中的ArrayBlockingQueue的使用:https://my.oschina.net/u/4410397/blog/3428573/print