Logstash pattern 例子
Logstash pattern 例子,就以Websphere为例:
e.g.
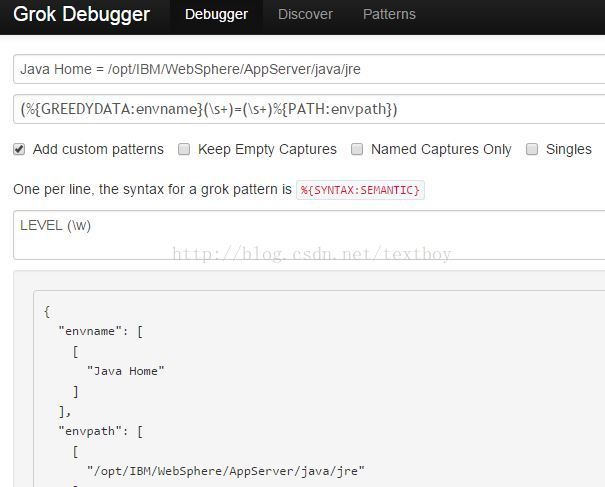
LEVEL (\w)
LOG1 (%{GREEDYDATA:envname}(\s+)=(\s+)%{PATH:envpath})
LOG2 (Java version = %{GREEDYDATA:javaversion}, Java Compiler = %{GREEDYDATA:javacompiler}, Java VM name = %{GREEDYDATA:javavm})
LOG3 (\[%{DATESTAMP:datetime}(\s+)%{TZ}\](\s+)%{INT}(\s+)%{WORD:category}(\s+)(%{LEVEL:level})(\s+)%{GREEDYDATA:detail})
WEBS_LOGLINE_ALL (%{LOG1}|%{LOG2}|%{LOG3})\w - 一个单词
%{GREEDYDATA:envname} - 调用Grok库里的%{GREEDYDATA},match任何字符;重命名为envname
\s+ - \s表空格,+表1个或无穷多个
%{PATH:envpath} - 调用Grok库里的%{PATH},match Unix或Windows路径;重命名为envpath
| - 表‘或’的关系
测试Log:
was.install.root = /opt/IBM/WebSphere/AppServer
Java version = 1.6.0, Java Compiler = j9jit24, Java VM name = IBM J9 VM
[5/18/15 9:30:38:383 CST] 00000000 ManagerAdmin I TRAS0017I: The startup trace state is *=info.在线测试地址:
http://grokdebug.herokuapp.com/ (注意:这link用到google 的 js,国内需要fa n/qian g~)
合并行的情况
如果是合并行的情况,需要注意换行符的处理,e.g.
conf
input
{
file
{
codec => multiline
{
patterns_dir => ["/home/logagent/mypatterns/pattern_platform_mysql"]
pattern => "^([^(%{LOG1})])"
negate => false
what => previous
}
...
filter
{
mutate
{
gsub => ["message", "\r\n", "#L_B#"]
gsub => ["message", "\n", "#L_B#"]
}
...Pattern
ALLDATA ([\s\S]*)
LB (#L_B#)
LBDATA ((#L_B#)%{ALLDATA})
ORAAUDITFILE (Audit file(\s*)%{PATH:oraauditfile}%{LBDATA})这里的换行符转为#L_B#,需要对此处理。
其它
如要避免大量tags为grokparsefailure标志的日志,可在最后匹配时加上|%{GREEDYDATA},这样哪怕所有自定义正则都不匹配的情况下,也至少匹配上greedydata。
2015.06.24 补充:在最后匹配时加上|%{GREEDYDATA},如果原pattern优先级不够GREEDYDATA高的话(不是按写的先后顺序),有机会导致原pattern匹配不上,so不建议使用。去除grokparsefailure 可以用filter { alter { remove_tag => "_grokparsefailure" }} 来解决。