RabbitMQ工作模式详解
-
- 工作队列
- 发布订阅模式
- 路由模式
- topic 模式
- 总结
此文我将以python为示例进行讲解。官方tutorial链接为:https://www.rabbitmq.com/tutorials/tutorial-five-python.html
本文将按照官网文档的方式介绍rabbitmq的几种工作模式。会讲解工作队列,发布订阅模式,路由模式,topic模式 这四种工作模式。
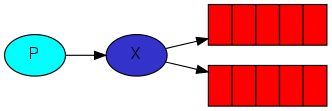
1. 工作队列
工作队列的模型如下图所示:

工作方式:
在此模式下,exchange声明为空,并且声明的队列的名称要和routing key同名。
生产者声明队列,并设置routing key与队列名相同
消费者声明同样名字的队列,不需要设置routing key,因为这种情况下是一个消费者将消息发到一个队列,多个消费者去那一个队列消费数据
为什么是这样呢,因为工作队列模式下是没有exchange的,生产者讲消息发到消息队列,然后消费者从同名的消息队列中取数据,如上面的图所示。
代码如下:
生产者代码:
# -*- coding:utf-8 -*-
import pika
"""
工作队列模式:
当exchange 为空时,声明的队列的名称要和routing key同名,
生产者声明队列,并设置routing key与队列名相同
消费者声明同样名字的队列,不需要设置routing key,因为这种情况下是一个消费者将消息发到一个队列,
多个消费者去那一个队列消费数据
"""
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
channel.queue_declare(queue="task_queue", durable=False)
while True:
line = raw_input("input msg:\n")
# line_split = line.split(" ")
# route_key = line_split[0]
# msg = lin
channel.basic_publish(
exchange='',
routing_key="task_queue", # direct ex 的 routing_key 要和queue的名字一样
body=line
)消费者代码:
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=False)
def callback(ch, method, properties, body):
print "callback"
print body
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, queue='task_queue')
print "start....."
channel.start_consuming()2. 发布订阅模式
发布订阅模式如下图所示:
工作方式:
发布订阅模式下面是有exchange需要声明的,注意,工作队列模式是没有exchange的。
fanout exchange是指将消息广播到多个队列,所有的与fanout exchange绑定的队列都会收到消息。然后不同的消费者绑定到不同的队列,这样就能有广播的效果。其实队列是由消费者来决定的,一个消费者进程可以declare一个队列,declare的新队列exchange就会将消息也会赋值发到新队列。
fanout exchange 的生产者不需要声明队列,而消费者需要声明队列,并将队列与exchange绑定,这样生产者的消息通过exchange才会发到所有队列
fanout exchange 也就没有routing key 之说,因为不存在有消息路由的情况
生产者代码:
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
channel.exchange_declare(exchange="test", type="fanout")
while True:
line = raw_input("input msg:\n")
channel.basic_publish(
exchange='test',
routing_key="",
body=line
)
# connection.close()
消费者代码:
# -*- coding:utf-8 -*-
import pika
import sys
"""
发布/订阅模式:
fanout exchange是指将消息广播到多个队列,所有的与fanout exchange绑定的队列都会收到消息
fanout exchange 的生产者不需要声明队列,而消费者需要声明队列,并将队列与exchange绑定,这样生产者的消息通过exchange才会发到所有队列
fanout exchange 也就没有routing key 之说,因为不存在有消息路由的情况
"""
queue_name = sys.argv[1]
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange="test", type="fanout")
# 声明队列
channel.queue_declare(queue=queue_name, durable=False)
# 绑定队列
channel.queue_bind(exchange="test", queue=queue_name)
def callback(ch, method, properties, body):
print "callback"
print body
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, queue=queue_name)
print "start....."
channel.start_consuming()
3. 路由模式
如下图所示:
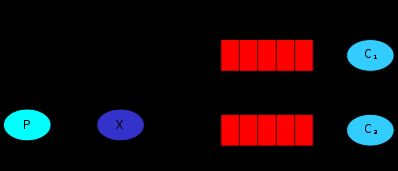
路由模式,顾名思义,就是根据不同的routing key能将消息路由到不同的队列。
此时的exchange是direct类型
消费者声明exchange,并根据自己的消息使用不同的routing key,将routing key和消息队列进行绑定,这样exchange便将不同routing key的消息发到不同的队列中,然后消费者通过不同的routing key绑定不同的消息队列,然后消费不同队列中的消息。
生产者代码:
# -*- coding:utf-8 -*-
import pika
"""
路由模式:
direct exchange
routing key 起到路由作用
"""
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
channel.exchange_declare(exchange="test_dir", type="direct")
while True:
line = raw_input("input routing key and msg:\n")
line_split = line.split(" ")
routing_key = line_split[0]
msg = line_split[1]
channel.basic_publish(
exchange='test_dir',
routing_key=routing_key,
body=line
)
# connection.close()
消费者代码:
# -*- coding:utf-8 -*-
import pika
import sys
"""
Usage:
python consumer.py queue_name routing_key1 routing_key2 ...
"""
queue_name = sys.argv[1]
routing_keys = sys.argv[2:]
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange="test_dir", type="direct")
# 声明队列
channel.queue_declare(queue=queue_name, durable=False)
# 绑定队列和routing_key,可以将多个routing_key同时绑定,调用多次bind函数
for key in routing_keys:
channel.queue_bind(exchange="test_dir", queue=queue_name, routing_key=key)
def callback(ch, method, properties, body):
print "callback"
print body
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, queue=queue_name)
print "start....."
channel.start_consuming()
4. topic 模式
如下图所示:

topic模式在路由方面的功能就更加丰富。能根据路由键的模式规则进行exchange与队列的绑定。
When a queue is bound with “#” (hash) binding key - it will receive all the messages, regardless of the routing key - like in fanout exchange.
When special characters “*” (star) and “#” (hash) aren’t used in bindings, the topic exchange will behave just like a direct one.
"*"与"#"的区别在于前者只能代表一个词,而后者可以表示0个或多个词。就例如上图中的lazy.#,如果带有routing key为lazy.orange.male.rabbit的消息,则只会发网Q2队列。不会匹配到其他两种routing key
生产者代码:
# -*- coding:utf-8 -*-
import pika
"""
topic 类型的exchange
记着一点:要对消息进行多路由分发,则必须是要多队列,因为分发消息是往队列发的,
而消费者是从队列消费的,如果多个消费者声明了同一个队列,则多个消费者都从同一个
队列拿数据,则一个消息只能被一个消费者消费。而如果声明了多个队列,并和一个exchange
进行了绑定,则exchange会将消息发到多个与之绑定的队列,则可以做到一条消息被复制到多个
队列被多个消费者消费
"""
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
channel.exchange_declare(exchange="test_topic", type="topic")
while True:
line = raw_input("input routing key and msg:\n")
line_split = line.split(" ")
routing_key = line_split[0]
msg = line_split[1]
channel.basic_publish(
exchange='test_topic',
routing_key=routing_key,
body=line
)
# connection.close()
消费者代码:
# -*- coding:utf-8 -*-
import pika
import sys
queue_name = sys.argv[1]
routing_keys = sys.argv[2:]
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='172.16.229.128',
port=5672,
virtual_host='/test',
credentials=pika.PlainCredentials("test", "test")
))
channel = connection.channel()
# 声明exchange
channel.exchange_declare(exchange="test_topic", type="topic")
# 声明队列
channel.queue_declare(queue=queue_name, durable=False)
# 绑定队列
for key in routing_keys:
channel.queue_bind(exchange="test_topic", queue=queue_name, routing_key=key)
def callback(ch, method, properties, body):
print "callback"
print body
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, queue=queue_name)
print "start....."
channel.start_consuming()
总结
其实direct类型和topic类型和fanout类型的exchange都能做到将线上的消息复制一份拿来做其他使用,只是要结合具体情况,代码中的注释提到了一点:
记着一点:
要对消息进行多路由分发,则必须是要多队列,因为分发消息是往队列发的,
而消费者是从队列消费的,如果多个消费者声明了同一个队列,
则多个消费者都从同一个队列拿数据,则一个消息只能被一个消费者消费。
而如果声明了多个队列,并和一个exchange进行了绑定,
则exchange会将消息发到多个与之绑定的队列,
则可以做到一条消息被复制到多个队列被多个消费者消费