Spring Boot整合Mybatis、Druid和Sharding-jdbc
前言
Spring Boot的出现让开发人员摆脱了繁琐的配置文件和依赖冲突,让项目搭建变得快速而便捷。而数据往往承载着项目的核心,从最原始的JDBC数据操作到Hibernate的对象关系映射框架的出现,数据库的操作变得更加灵活。Mybatis则是比Hibernate更为强大与灵活的ORM框架,本文将着重讲解Spring Boot和Mybatis、Druid和Sharding-jdbc的整合。
框架介绍
Mybatis
MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以 及获取结果集。MyBatis 可以对配置和原生Map使用简单的 XML 或注解,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
Druid
Druid首先是一个数据库连接池。Druid是目前最好的数据库连接池,在功能、性能、扩展性方面,都超过其他数据库连接池,包括DBCP、C3P0、BoneCP、Proxool、JBoss DataSource。
数据库连接的创建与销毁往往代表着资源的消耗,而数据库连接池则接管了数据库连接的管理,它能够有效减少频繁的创建与销毁带来的资源消耗,重复利用连接资源,保证避免连接资源的无限制创建,同时提供对数据库连接的运行监控,保障数据层的安全。
Sharding-jdbc
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它支持且不仅限于数据分片(分库分表)、读写分离、分布式主键等功能。
当业务发展到一定阶段,高速膨胀的数据量已经无法通过单库单表来满足。单库单表的读写性能将无法承载业务发展所带来的巨额数据。即使可以通过类似Mysql的物理分区或者提高数据库的硬件资源缓解这一问题,但单个硬件资源是存在上限的,所以往往需要通过分库分表弹性扩展和分摊数据库的读写压力。
整合教程
数据层项目结构
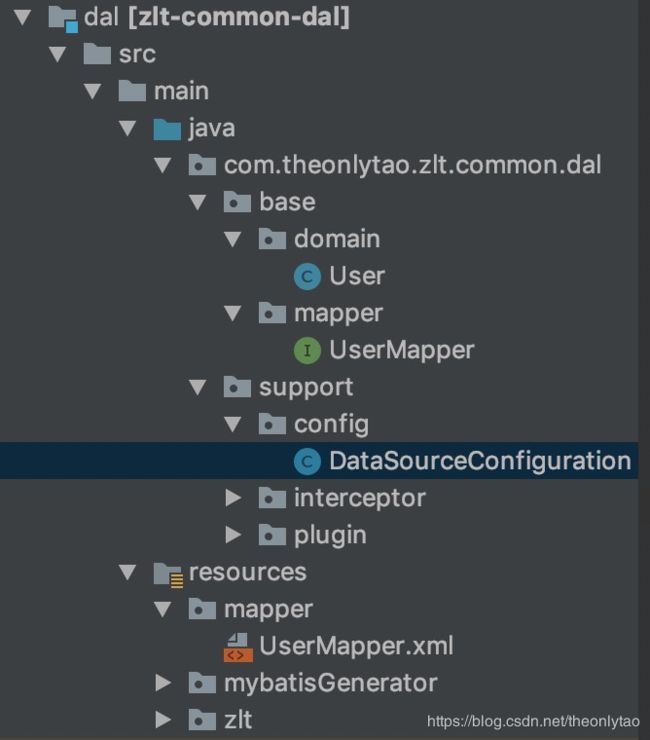
- domain
数据库表与Java POJO对象的映射 - mapper
数据库表向外暴露的SQL操作Api接口 - config
数据库连接(DataSource)配置 - resources/mapper
数据库表SQL与Java POJO对象的实际映射逻辑
Maven配置
org.mybatis
mybatis
3.4.4
org.mybatis.generator
mybatis-generator-core
1.3.5
org.mybatis
mybatis-spring
1.3.1
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
com.alibaba
druid-spring-boot-starter
1.1.10
org.apache.shardingsphere
sharding-jdbc-core
4.0.0-RC1
因为Dao层是作为独立的一层结构,所以父亲Pom文件已经引入了Spring Boot的依赖,请根据各自的项目结构调整。
org.springframework.boot
spring-boot-starter-parent
2.0.3.RELEASE
数据库连接配置(核心)
package com.theonlytao.zlt.common.dal.support.config;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import com.google.common.collect.ImmutableMap;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.shardingsphere.api.config.sharding.KeyGeneratorConfiguration;
import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.strategy.InlineShardingStrategyConfiguration;
import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.support.TransactionTemplate;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.Map;
import java.util.Properties;
/**
* 数据库配置类
*
* @author zoult on 2019/9/17
*/
@Configuration
@MapperScan(value = {"com.theonlytao.zlt.common.dal.base.mapper"}, sqlSessionFactoryRef = "sqlSessionFactory")
public class DataSourceConfiguration {
@Bean("master")
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource masterDataSource() {
return DruidDataSourceBuilder.create().build();
}
@Bean
@Primary
public DataSource dataSource() throws SQLException {
// 分库分表配置
Map dataSourceMap = ImmutableMap.of("ds0", masterDataSource());
return ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfiguration(), new Properties());
}
/**
* 分片策略
*
* @return
*/
private ShardingRuleConfiguration shardingRuleConfiguration() {
// 设置分表逻辑名称(user)和分表范围(user_00和user_01),Sharding-JDBC的行表达式
TableRuleConfiguration userTbRule = new TableRuleConfiguration("user", "ds0.user_0${0..1}");
// 分表策略
// 设置分片主键user_id,根据用户ID取模2决定路由的表,这里仅分2张表
userTbRule.setTableShardingStrategyConfig(
new InlineShardingStrategyConfiguration("user_id", "user_0${user_id%2}"));
// 分布式ID方案(雪花算法)
userTbRule.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "user_id"));
ShardingRuleConfiguration shardingRuleConfiguration = new ShardingRuleConfiguration();
shardingRuleConfiguration.getTableRuleConfigs().add(userTbRule);
return shardingRuleConfiguration;
}
@Bean("sqlSessionFactory")
@Primary
public SqlSessionFactory initSqlSessionFactory() throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(dataSource());
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
factoryBean.setMapperLocations(resolver.getResources("classpath*:mapper/*.xml"));
factoryBean.setTypeAliasesPackage("com.theonlytao.zlt.common.dal.base.domain");
return factoryBean.getObject();
}
@Bean("transactionManager")
@Primary
public DataSourceTransactionManager initDataSourceTransactionManager() throws SQLException {
return new DataSourceTransactionManager(dataSource());
}
@Bean("sqlSessionTemplate")
@Primary
public SqlSessionTemplate initSqlSessionTemplate() throws Exception {
return new SqlSessionTemplate(initSqlSessionFactory());
}
@Bean("transactionTemplate")
@Primary
public TransactionTemplate initTransactionTemplate() throws Exception {
return new TransactionTemplate(initDataSourceTransactionManager());
}
} 数据库配置类设置了Mybatis的domain、mapper和resources/mapper的扫描路径,数据库连接的管理交给了Druid连接池,Sharding-jdbc则对Druid的DataSource再次进行装饰,最后交给Mybatis的SqlSessionFactory托管。DataSourceTransactionManager、SqlSessionTemplate和TransactionTemplate则是对Spring Boot事务的整合。
相关application.properties、domain、mapper和mapper.xml
application.properties
# 数据库连接池配置
# 初始化大小
spring.datasource.initialSize=1
# 最小连接池数量
spring.datasource.minIdle=1
# 最大连接池数量
spring.datasource.maxActive=50
# 获取连接时最大等待时间,单位毫秒
spring.datasource.maxWait=60000
# 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=60000
# 一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis=300000
spring.datasource.validationQuery=SELECT 1
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
spring.datasource.filters=stat,wall
# mysql连接配置
spring.datasource.name=zlt-boot
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/user
spring.datasource.username=zlt
spring.datasource.password=123456domain
public class User {
/** 主键ID */
private Long id;
/** 创建时间 */
private Date gmtCreated;
/** 修改时间 */
private Date gmtModified;
/** 用户ID */
private Long userId;
/** 用户名 */
private String name;
}mapper
@Repository
public interface UserMapper {
int insert(User record);
User findByUserId(@Param("userId") Long userId);
}mapper.xml
id, gmt_created, gmt_modified, user_id, `name`
insert into `user` (gmt_created, gmt_modified,
user_id,`name`)
values (#{gmtCreated,jdbcType=DATE}, #{gmtModified,jdbcType=DATE},
#{userId,jdbcType=BIGINT}, #{name,jdbcType=VARCHAR})