使用seata在解决分布式事务中遇到的一些常见问题
背景:
随着微服务架构的流行,分布式事务作为必须要面对和解决的课题,业界也存在着多种解决方案。例如:两阶段提交、TCC(try、confirm、cancel)、借助于消息队列的等等。但这些要么不能很好地保证数据的一致性,要么就是实现起来复杂度比较高,还有就是业务的侵入性。
seata作为一个分布式事务框架,最开始吸引我的地方,就是他的AT模式,不但避免了业务的侵入性,降低开发的复杂度,而且它的异步提交策略(如果一阶段分支事务成功提交,则二阶段一开始,全局锁即被释放,否则,直到二阶段回滚完成才能释放全局锁)在保证数据一致性的前提下,尽可能的提高了分布式事务的效率。
关于原理性的内容可以参照githup(https://github.com/seata/seata),我就不多赘述了。
我主要采用了seata提供的AT模式,下面主要介绍一下,我在使用seata解决分布式事务时遇到的一些问题和怎么解决的。
我使用的是0.9.0版本,有些问题已经被新版本修复,下面会用加粗斜体标识,也建议大家去使用1.0版本,当然这里遇到的一些问题,也可以参考一下
==================================================================
首先贴出我的pom主要依赖:


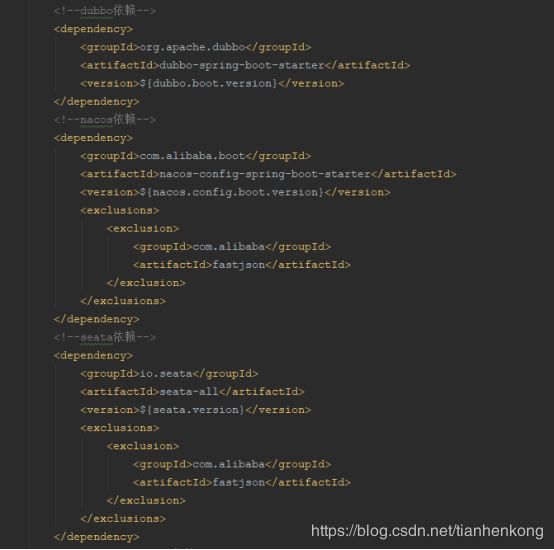
问题1:一个分支事务中双数据源无法切换,准确来说,是双数据源在一个分支事务开启后不能切换
可能有些朋友在看到这里已经知道,为什么在开启事务之后,不能进行数据源的切换了。
是这样的,我们系统配置了两个数据源A和B,其中A数据源是主要的业务数据源,B只是用来做些基础数据的查询。
实际上,当开启一个本地事务之后,Spring框架是不会再调用AbstractRoutingDataSource的determineCurrentLookupKey()方法的。因为一旦再次调用该方法,使用另一个数据源,并且对其进行增删改操作,就相当于同时操作了两个数据库的记录,这是与我们的常识相违背的。
这也是对seata理解不清,误以为加入@GlobalTransaction注解后,可以回滚或者提交一个分支事务中的多个数据源的操作。
实际上,seata是可以对多个数据源进行事务控制的,前提是一个分支事务操作一个数据源。(经大神指导,此处改动)
解决方法:
1、可以针对一个数据源开启一个分支事务,用seata来管理全局事务的提交或回滚
2、尽量在事务开启之前,将需要的数据从B数据源查询出来。(因为我B数据源都是查询操作,不需要开启一个分支事务了)
当然啦,如果都是查询类的操作,就可以随意切换数据源了。
问题2:就是偶尔出现无法成功开启全局事务
要开启全局事务,seata会在全局表global_table中,插入全局事务信息,表结构如下:

可以看到,这里的transaction_name属性长度只有64位。
seata默认会使用方法名和参数类型来作为全局事务的名称,所以很容易就超出长度范围,导致开启全局事务失败。
下图是seata默认生成的全局事务名称:
![]()
针对这个问题,解决方法有两个:
1、既然长度不够,就把属性长度加长就行了;
2、在开启全局事务的时候,给GlobalTransaction注解,添加一个name属性就可以了。
当然选择哪种方案,都可以,我是采用了长度加长的方案,因为不能保证每个地方都加上name属性了。
注:我使用的是0.9.0版本,新的版本中已经彻底解决了这个transaction_name问题
问题3:全局事务成功开启之后,可能会遇到分支事务有时无法注册成功的情况
报错日志如下图所示:
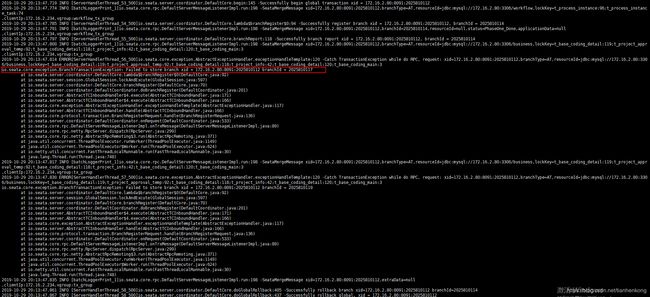
把图片放大之后,可以看到其中lock_key的值如下:

而分支表的建表语句如下所示:
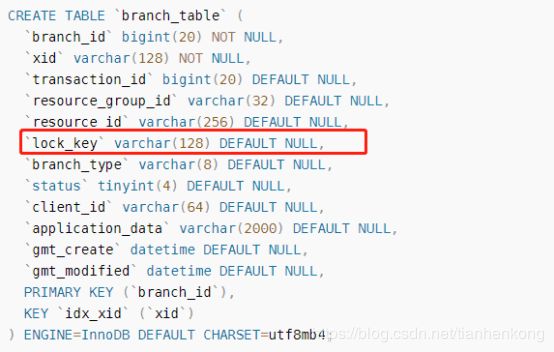
所以,很容易想到解决方案,就是把lock_key的长度范围加大,或者把表名缩短。
当然你也可以尽量保证一个事务不要锁定太多的记录行。
注:lock_key长度不足的问题,在 最新的1.0版本中,已经彻底解决
另外一种可能导致分支事务注册失败的情况是,表名称太长。
下面是lock_table的表结构:
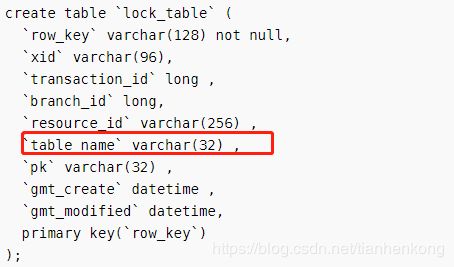
当然,解决方案也是增加字段长度,获取表名尽量用简短的字母表示。
问题4:这是一个比较常见也是非常关键的问题
有些朋友包括我,在建表的时候,经常使用联合主键,或者唯一索引,而去掉主键ID,尤其是关联表的子表。
需要特别注意的是,如果要使用seata,一定要给每一张表都创建一个主键,最起码,目前seata是不支持没有主键的。
如果在更新一条记录的时候,没有传主键ID也会报错,如下:
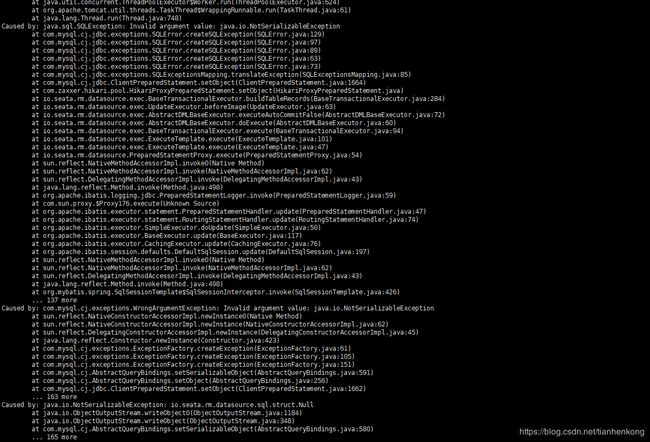
报错的信息比较诡异,是没有序列化异常,最新版本也已经解决了(我是0.9.0版本)。
欢迎一起讨论,如果你遇到一些问题,欢迎评论下方留言。
欢迎转载,转载请注明出处:
https://mp.csdn.net/postedit/103178451