spark操作mysql数据库
spark对mysql提供了一些基本的读写操作,今天这边文章主要从读写两个方面来讲。
一、spark读取mysql数据库
1、通过JdbcRdd来读取
首先看一下官方文档是如何介绍的
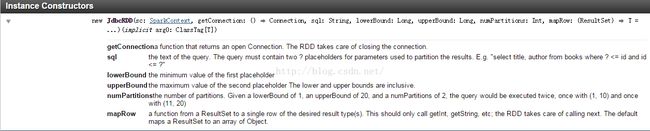
翻译为:
1、getConnection 返回一个已经打开的结构化数据库连接,JdbcRDD会自动维护关闭。
2、sql 是查询语句,此查询语句必须包含两处占位符?来作为分割数据库ResulSet的参数,例如:"select title, author from books where ? < = id and id <= ?"
3、lowerBound, upperBound, numPartitions 分别为第一、第二占位符,partition的个数。例如,给出lowebound 1,upperbound 20, numpartitions 2,则查询分别为(1, 10)与(11, 20)
4、mapRow 是转换函数,将返回的ResultSet转成RDD需用的单行数据,此处可以选择Array或其他,也可以是自定义的case class。默认的是将ResultSet 转换成一个Object数组。代码示例:
val sc = new SparkContext("local", "mysql")
val rdd = new JdbcRDD(
sc,
() => {
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/db", "root", "123456")
},
"SELECT content FROM mysqltest WHERE ID >= ? AND ID <= ?",
1, 100, 3,
r => r.getString(1)).cache()
print(rdd.filter(_.contains("success")).count())缺点:
只能用于查找符合ID >= ? AND ID <= ?这种形式的数据
2、通过SQLContext.read.jdbc来读取
看一下官方文档介绍

翻译一下:
url:database的url,格式:jdbc:subprotocol:subname
table:表名
predicates:where条件
connectionProperties:数据库连接属性
代码示例:
val url="jdbc:mysql://localhost:3306/my_db"
val prop = new java.util.Properties
prop.setProperty("user","root")
prop.setProperty("password","123456)
#指定读取条件,这里 Array("gender=1") 是where过滤条件
val cnFlight = sqlContext.read.jdbc(url,"gps_location",Array("gender=1"),prop).select("id","name")二、spark写入mysql数据库
spark1.3添加了DataFrame,可以方便的对表和数据进行操作。
createJDBCTable介绍:

url:数据库信息
table:表名
overwrite:是否覆盖之前数据
insertIntoJDBC介绍:

url:数据库信息
table:表名
allowExisting:如果表存在,是否删除之前表
看文档,我们可以看到,这个方法会执行一个create table和insert into 的过程,如果allowdExisting为true,则会删除之前的表,
示例如下:
import org.apache.spark.SparkContext
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
/**
* class description :
* project_name:test.mysql
* author:lucaifang
* createTime:2016/7/18 17:11
* updateTime:2016/7/18 17:11
*
*/
object JdbcTest {
def main(args: Array[String]) {
val sc = new SparkContext
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val data = sc.parallelize(List((1,"name1"),(2,"name2"),(3,"name3"),(4,"name4"))).
map(item=>Row.apply(item._1,item._2))
val schema = StructType(StructField("id", IntegerType)::StructField("name", StringType):: Nil)
val df = sqlContext.createDataFrame(data,schema)
val url="jdbc:mysql://172.16.3.66:3306/data_kanban?user=root&password=dataS@baihe!"
df.createJDBCTable(url, "table1", false)//创建表并插入数据
df.insertIntoJDBC(url,"table1",false)//插入数据 false为不覆盖之前数据
}
}文章整理来自:http://www.iteblog.com/archives/1290